# 1 简介
# 1.1 实验环境
本实验主要使用 Ubuntu 20.04 64 位作为系统环境,采用 6 台 4 核 8GB 云服务器作为 Kubernetes 集群部署机器,1 台 2 核 4GB 云服务器作为集群管理工具 Kuboard Spary 部署机器,1 台 2 核 4GB 云服务器作为 NFS Server(使用 Centos 7.6 系统)部署机器。
使用的软件如下:
| 名称 | 版本 |
|---|---|
| kuboard spary | v1.2.3-amd64 |
| kubernetes | v1.25.4 |
| calico | v3.23.3 |
| etcd | v3.5.5 |
| crictl | v1.25.0 |
| crun | 1.4.5 |
| krew | v0.4.3 |
| runc | v1.1.4 |
| cni | v1.1.1 |
| nerdctl | 1.0.0 |
| coredns | v1.8.6 |
| dnsautoscaler | 1.8.5 |
| pod_infra | 3.7 |
| spark | 3.3.1 |
| hadoop | 3.2.3 |
# 1.2 集群规划
- Kuborad Spary
| 主机名 | IP |
|---|---|
| kuborad | 192.168.0.115 |
- NFS Server
| 主机名 | IP |
|---|---|
| NFS-server | 192.168.0.132 |
- Kubernetes 集群规划
| 主机名 | IP | 控制节点 | etcd 节点 | 工作节点 |
|---|---|---|---|---|
| node1 | 192.168.0.76 | 是 | 是 | 是 |
| node2 | 192.168.0.213 | 是 | 是 | 是 |
| node3 | 192.168.0.2 | 是 | 是 | 是 |
| node4 | 192.168.0.41 | 否 | 否 | 是 |
| node5 | 192.168.0.73 | 否 | 否 | 是 |
| node6 | 192.168.0.12 | 否 | 否 | 是 |
# 2 部署 Kubernetes 集群
# 2.1 安装 Kuboard-Spray
Kuboard-Spray 是一款可以在图形界面引导下完成 Kubernetes 高可用集群离线安装的工具,开源仓库的地址为 Kuboard-Spray
在 kuborad 节点上安装 docker-ce
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28# 1. 安装必备的系统工具 sudo apt-get remove docker docker-engine docker.io containerd runc; sudo apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common; # 2. 安装 GPG 证书 curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/docker.gpg; # 3. 写入软件源信息 echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null # 4. 更新并安装 Docker-CE sudo apt-get update; sudo apt-get install docker-ce; # 5. 配置 docker 镜像加速器(可以在阿里云获取地址) sudo mkdir -p /etc/docker; sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": [ "https://docker.mirrors.ustc.edu.cn", "https://cr.console.aliyun.com/" ] } EOF sudo systemctl daemon-reload; sudo systemctl restart docker;在 kuboard 节点上执行以下命令:
1 2 3 4 5 6 7 8 9docker run -d \ --privileged \ --restart=unless-stopped \ --name=kuboard-spray \ -e TZ=Asia/Shanghai \ -p 80:80/tcp \ -v /var/run/docker.sock:/var/run/docker.sock \ -v ~/kuboard-spray-data:/data \ eipwork/kuboard-spray:v1.2.3-amd64在浏览器打开地址
http://这台机器的 IP,输入用户名admin,默认密码Kuboard123,即可登录 Kuboard-Spray 界面。
# 2.2 加载离线资源包
在 Kuboard-Spray 界面中,导航到
系统设置–>资源包管理界面,可以看到已经等候您多时的Kuboard-Spray 离线资源包,如下图所示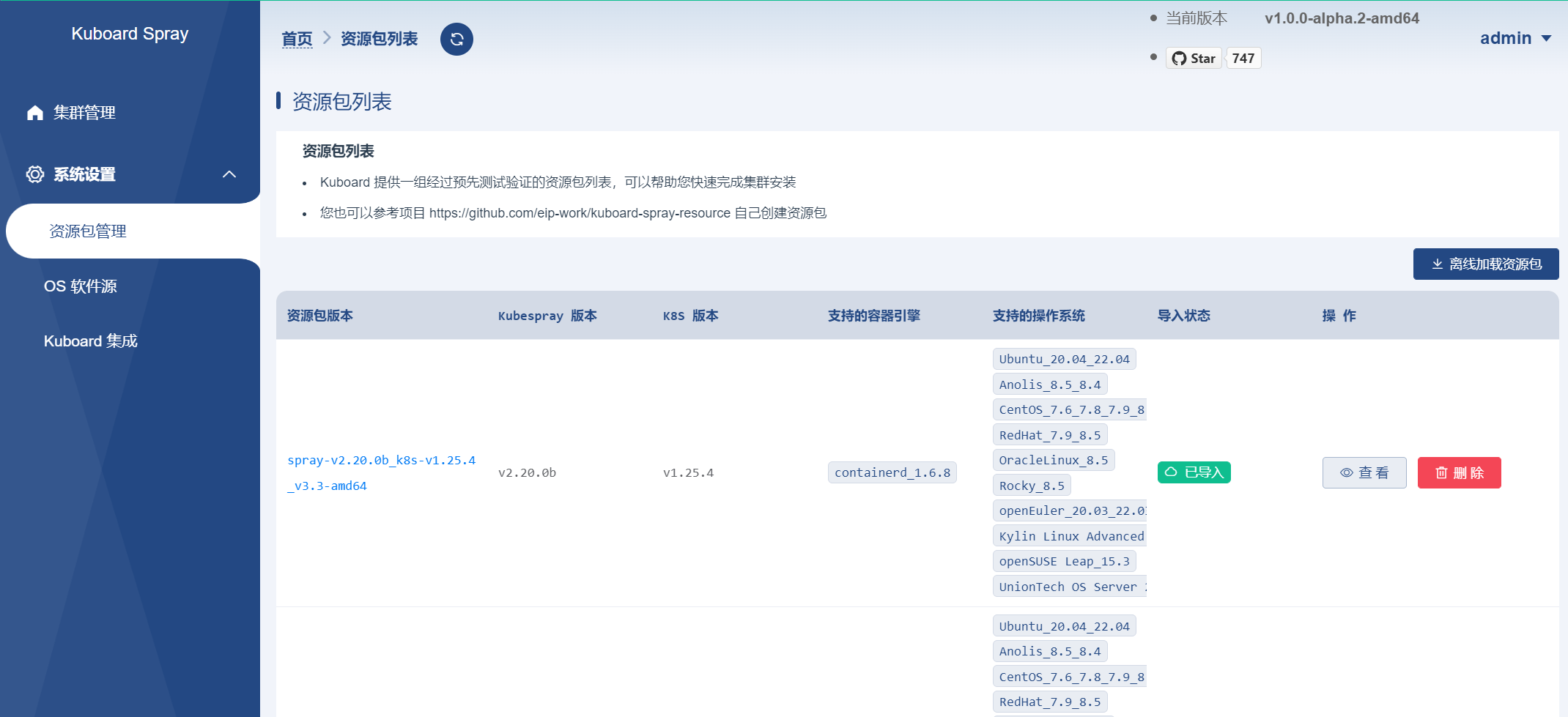
点击
导入按钮,在界面的引导下完成资源包的加载。
# 2.3 安装 Kubernetes 集群
在 Kuboard-Spray 界面中,导航到 集群管理 界面,点击界面中的 添加集群安装计划 按钮,填写表单如下:
集群名称: 自定义名称,本文中填写为
kuboard,此名称不可以修改;资源包:选择前面步骤中导入的离线资源包。
点击
确定按钮后,将进入集群规划页面,在该界面中添加每个集群节点的连接参数并设置节点的角色,如下图所示: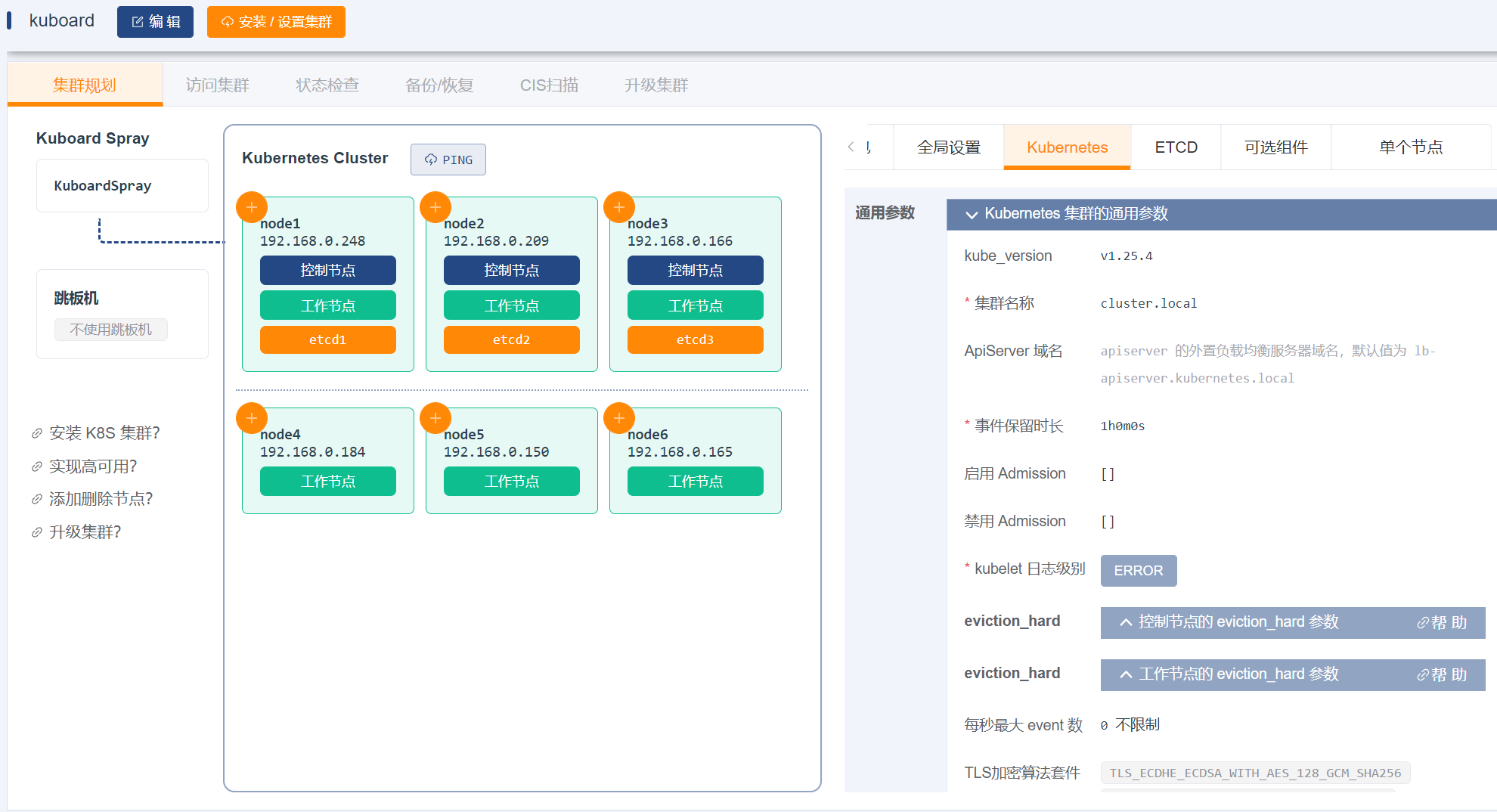
重要: kuboard-spray 所在机器不能当做 K8S 集群的一个节点,因为安装过程中会重启集群节点的容器引擎,这会导致 kuboard-spray 被重启掉。
注意:
- 最少的节点数量是 1 个;
- ETCD 节点、控制节点的总数量必须为奇数;
点击上图的
保存按钮,再点击执行按钮,可以启动集群的离线安装过程,安装结果如下: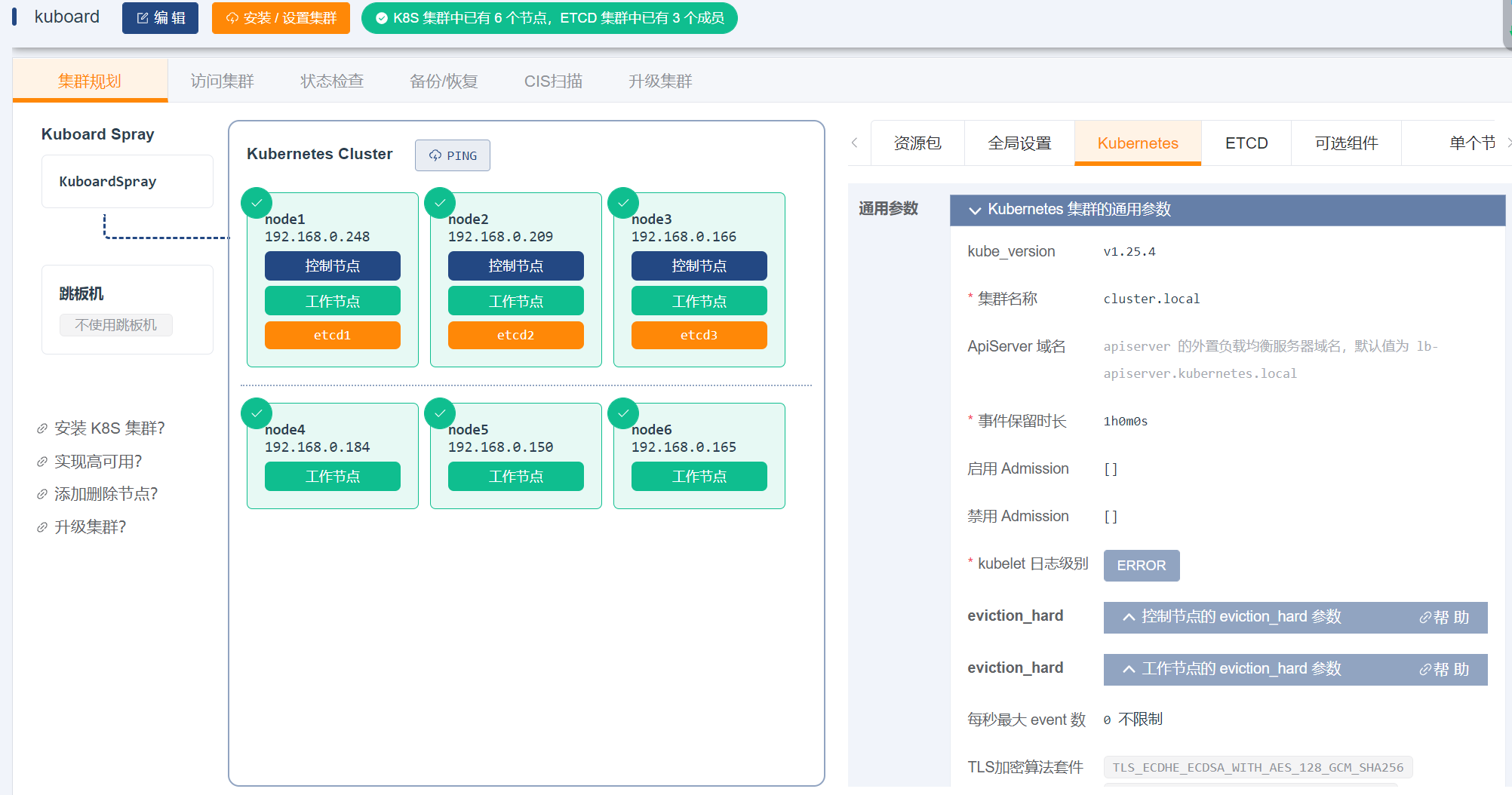
# 3 部署 Spark on k8s
# 3.1 制作 spark 容器镜像
下载 spark-3.3.1-bin-hadoop3
1 2 3wget https://mirrors.pku.edu.cn/apache/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz; tar -xzf spark-3.3.1-bin-hadoop.tgz; mv spark-3.3.1-bin-hadoop spark;修改 Dockerfile 默认 apt 源加速
1 2 3 4 5 6 7cd spark/kubernetes/dockerfiles/spark; // 修改 Dockerfile 内容 // 修改前: sed -i 's/http:\/\/deb.\(.*\)/https:\/\/deb.\1/g' /etc/apt/sources.list // 修改后: sed -i 's#http://deb.debian.org#https://mirrors.ustc.edu.cn#g' /etc/apt/source.list sed -i 's|security.debian.org/debian-security|mirrors.ustc.edu.cn/debian-security|g' /etc/apt/source.list构建 docker 镜像
1 2 3cd spark/bin; // -r <repo> -t <tag> ./docker-image-tool.sh -r cuterwrite -t 0.1 build;推送镜像到阿里云仓库(参考容器镜像服务->实例列表->镜像仓库)
1 2 3docker login --username=[阿里云账号] registry.cn-hangzhou.aliyuncs.com; docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/[repository]:[镜像版本号]; docker push registry.cn-hangzhou.aliyuncs.com/[repository]:[镜像版本号];
# 3.2 创建命名空间
访问 Kuboard,通常默认用户名为
admin,默认密码为Kuboard123,访问地址为第一个控制节点的 80 端口(取决于安装时的参数),如下图所示: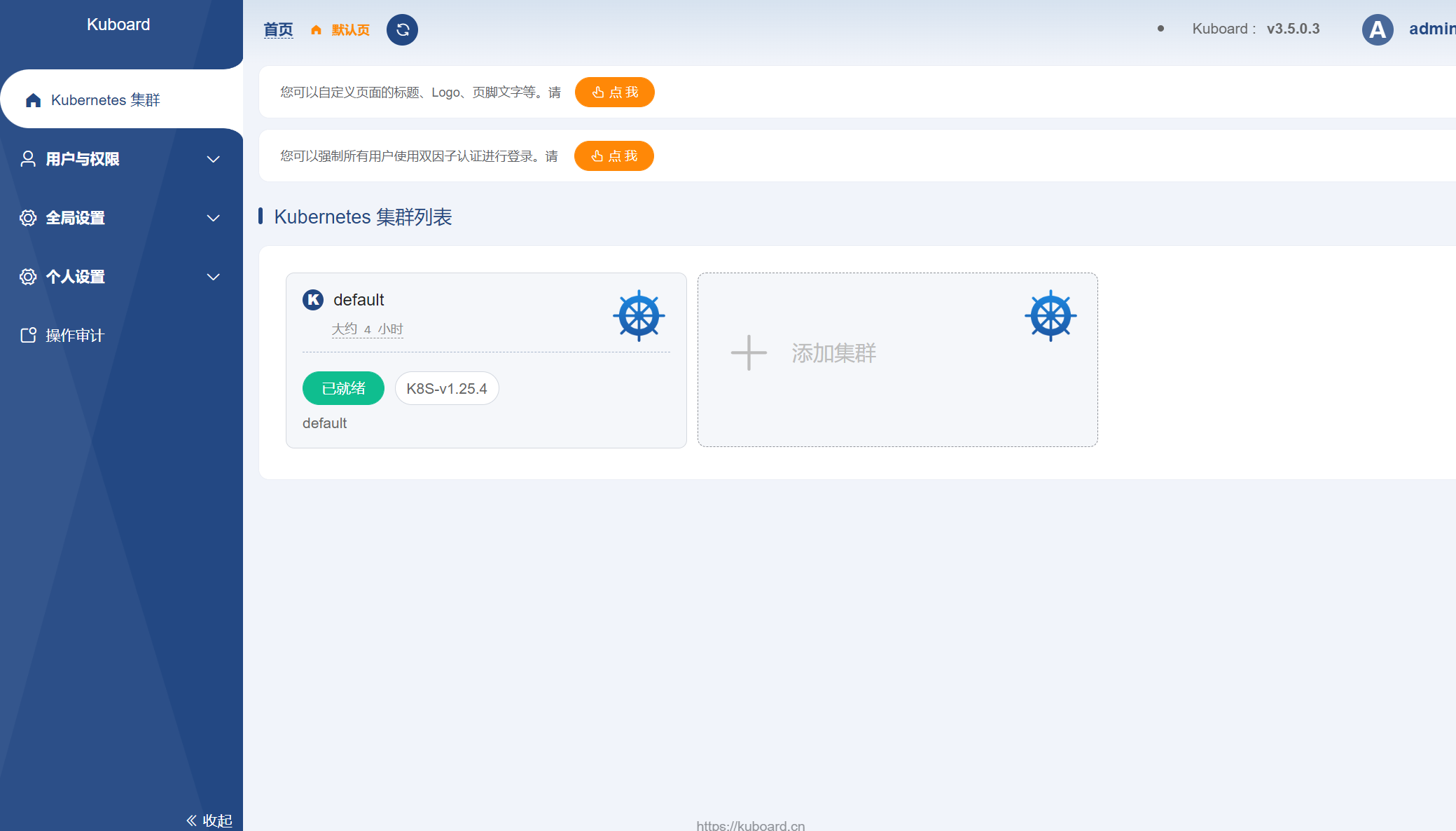
点击进入 default 集群,在下图所示的页面点击创建
spark命名空间: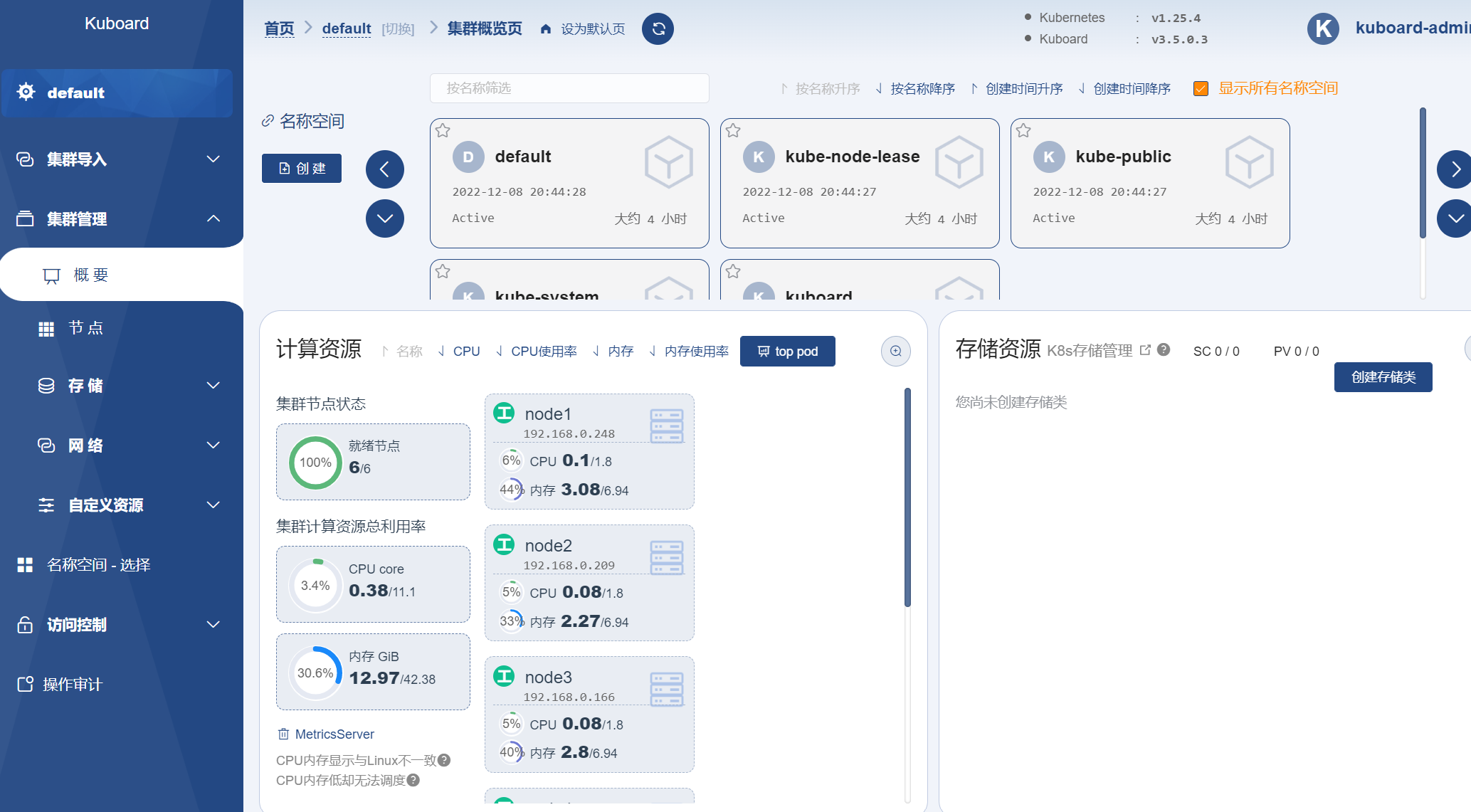
# 3.3 配置 spark 用户权限
创建用户
spark并配置权限1 2kubectl create serviceaccount spark kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark:spark --namesparce=spark
# 3.4 配置 spark 历史服务器
创建一个名为
spark-history-server的 deployment,配置如下:容器信息:
名称:spark-history-server
容器镜像:registry.cn-hangzhou.aliyuncs.com/[用户名]/spark:0.1(需配置仓库仓库名和密码)
环境变量:SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=hdfs://192.168.0.238:8020/sparkhistory(需提前部署 HDFS)
容器端口:18080,端口名称 http
参数:["/opt/spark/bin/spark-class", “org.apache.spark.deploy.history.HistoryServer”]
服务信息:
端口:18080
协议:TCP
目标端口:18080
NodePort:30080
类型:NodePort
测试配置是否成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18./spark-submit \ --master k8s://https://127.0.0.1:6443 \ --deploy-mode cluster \ --name spark-pi \ --class org.apache.spark.examples.SparkPi \ --conf spark.kubernetes.executor.request.cores=1 \ --conf spark.kubernetes.executor.limit.cores=1 \ --conf spark.kubernetes.driver.limit.cores=1 \ --conf spark.kubernetes.driver.request.cores=1 \ --conf spark.eventLog.enabled=true \ --conf spark.eventLog.dir=hdfs://192.168.0.238:8020/sparkhistory \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.kubernetes.namespace=bigdata \ --conf spark.executor.instances=2 \ --conf spark.kubernetes.file.upload.path=/tmp \ --conf spark.kubernetes.container.pullSecrets=aliyun-repository \ --conf spark.kubernetes.container.image=registry.cn-hangzhou.aliyuncs.com/cuterwrite/spark:0.1 \ hdfs://192.168.0.238:8020/user/root/jars/spark-examples_2.12-3.3.1.jar提交任务成功后可以在 Kuboard 管理界面看到一个新启动的容器组:
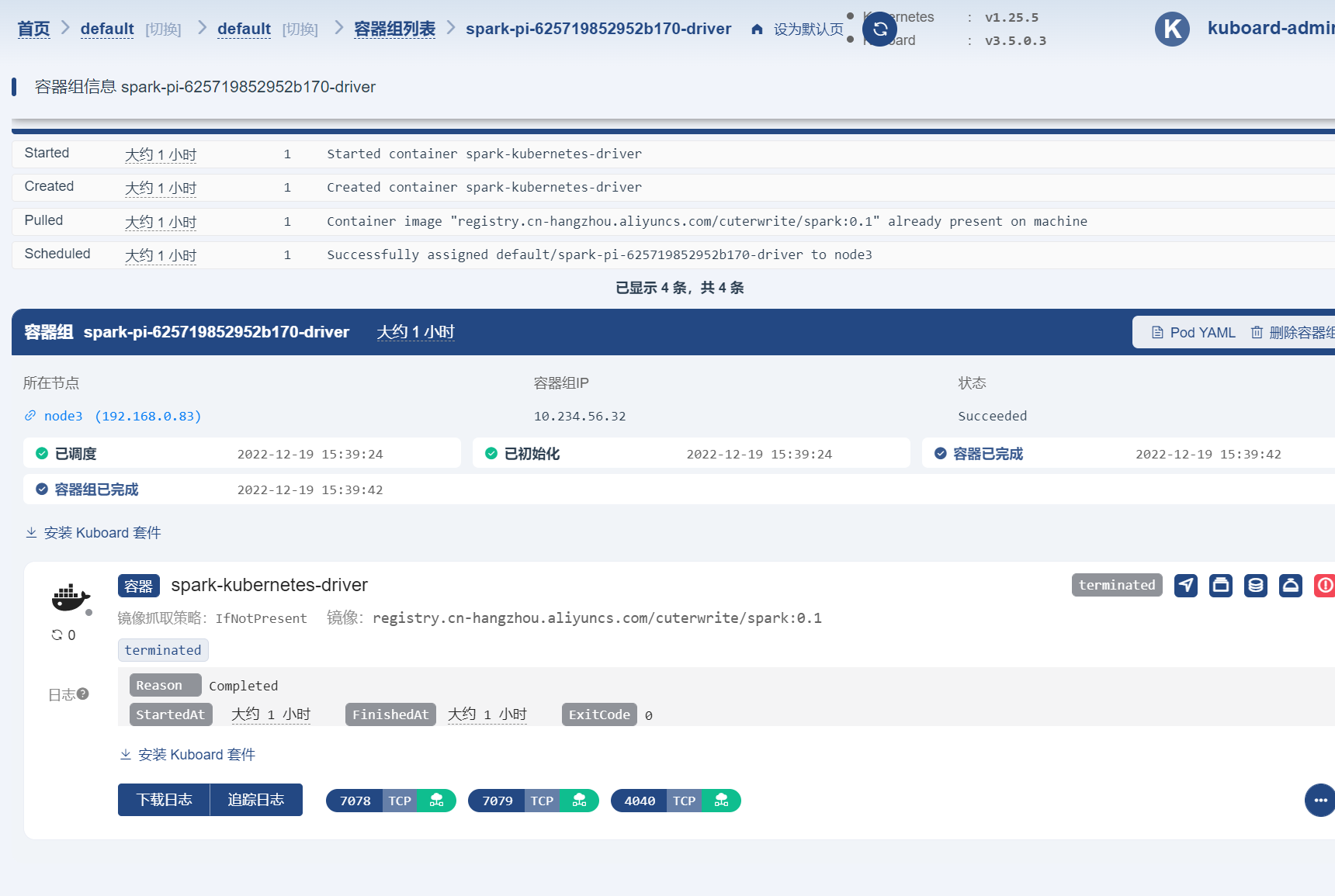
访问 spark 历史服务器,可以看到以下记录:
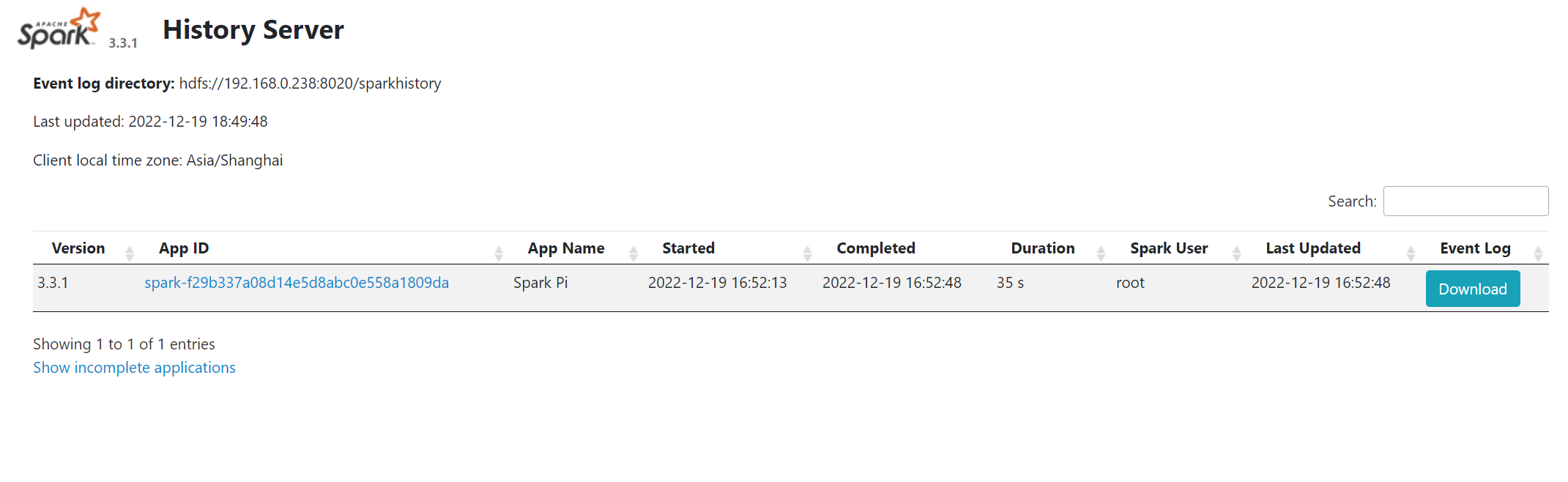
# 4 编写 WordCount 程序
WordCount.java
| |
# 5 实验结果
- 提交词频统计任务到
Kubernetes
| |
- 执行结果:
| |