
本文欢迎非商业转载,转载请注明出处。
声明:仅用于收藏,便于阅读
― Savir, 知乎专栏:4. RDMA 操作类型
前面几篇涉及 RDMA 的通信流程时一直在讲 SEND-RECV,然而它其实称不上是“RDMA”,只是一种加入了 0 拷贝和协议栈卸载的传统收发模型的“升级版”,这种操作类型没有完全发挥 RDMA 技术全部实力,常用于两端交换控制信息等场景。当涉及大量数据的收发时,更多使用的是两种 RDMA 独有的操作:WRITE 和 READ。
我们先来复习下双端操作——SEND 和 RECV,然后再对比介绍单端操作——WRITE 和 READ。
# SEND & RECV
SEND 和 RECV 是两种不同的操作类型,但是因为如果一端进行 SEND 操作,对端必须进行 RECV 操作,所以通常都把他们放到一起描述。
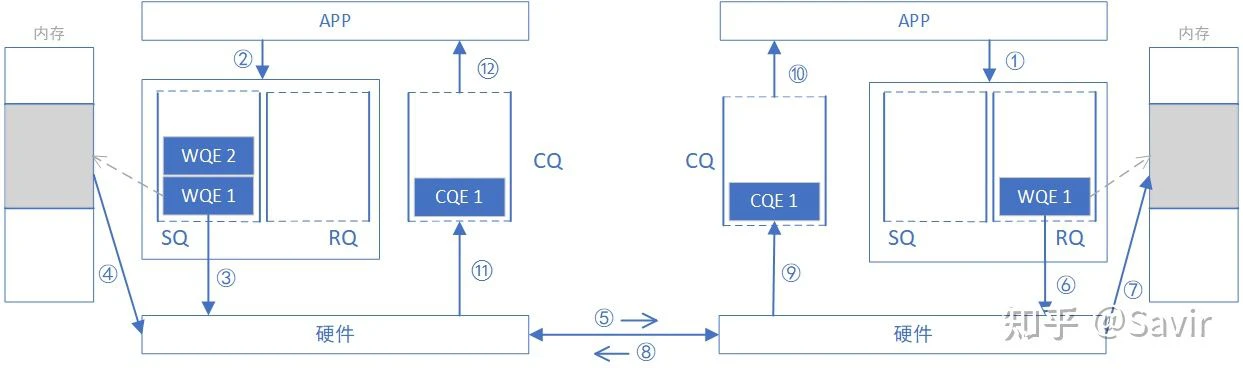
为什么称之为“双端操作”?因为完成一次通信过程需要两端 CPU 的参与,并且收端需要提前显式的下发 WQE。下图是一次 SEND-RECV 操作的过程示意图。原图来自于[1],我做了一些修改。

上一篇我们讲过,上层应用通过 WQE(WR)来给硬件下任务。在 SEND-RECV 操作中,不止发送端需要下发 WQE,接收端也需要下发 WQE 来告诉硬件收到的数据需要放到哪个地址。发送端并不知道发送的数据会放到哪里,每次发送数据,接收端都要提前准备好接收 Buffer,而接收端 CPU 自然会感知这一过程。
为了下文对比 SEND/RECV 与 WRITE/READ 的异同,我们将上一篇的 SEND-RECV 流程中补充内存读写这一环节,即下图中的步骤④——发送端硬件根据 WQE 从内存中取出数据封装成可在链路上传输数据包和步骤⑦——接收端硬件将数据包解析后根据 WQE 将数据放到指定内存区域,其他步骤不再赘述。另外再次强调一下,收发端的步骤未必是图中这个顺序,比如步骤⑧⑪⑫和步骤⑨⑩的先后顺序就是不一定的。
下面将介绍 WRITE 操作,对比之后相信大家可以理解的更好。
# WRITE
WRITE 全称是 RDMA WRITE 操作,是本端主动写入远端内存的行为,除了准备阶段,远端 CPU 不需要参与,也不感知何时有数据写入、数据在何时接收完毕。所以这是一种单端操作。
通过下图我们对比一下 WRITE 和 SEND-RECV 操作的差异,本端在准备阶段通过数据交互,获取了对端某一片可用的内存的地址和“钥匙” ,相当于获得了这片远端内存的读写权限。拿到权限之后,本端就可以像访问自己的内存一样直接对这一远端内存区域进行读写,这也是 RDMA——远程直接地址访问的内涵所在。
WRITE/READ 操作中的目的地址和钥匙是如何获取的呢?通常可以通过我们刚刚讲过的 SEND-RECV 操作来完成,因为拿到钥匙这个过程总归是要由远端内存的控制者——CPU 允许的。虽然准备工作还比较复杂, 但是一旦完成准备工作,RDMA 就可以发挥其优势,对大量数据进行读写。一旦远端的 CPU 把内存授权给本端使用,它便不再会参与数据收发的过程,这就解放了远端 CPU,也降低了通信的时延。
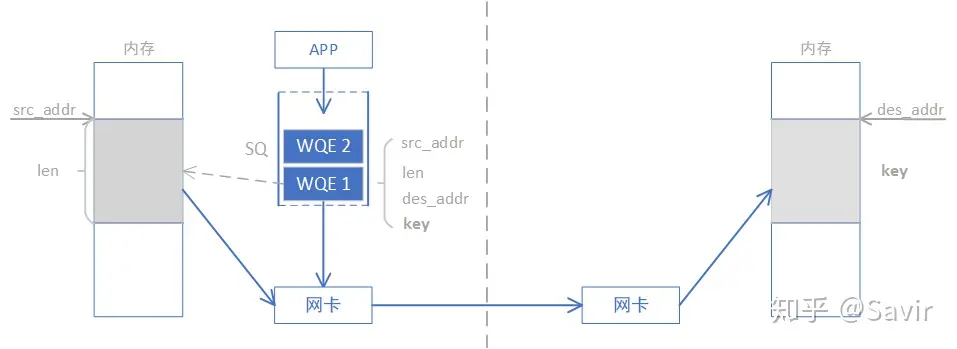
需要注意的是,本端是通过虚拟地址来读写远端内存的,上层应用可以非常方便的对其进行操作。实际的虚拟地址—物理地址的转换是由 RDMA 网卡完成的。具体是如何转换的,将在后面的文章介绍。
忽略准备阶段 key 和 addr 的获取过程,下面我们描述一次 WRITE 操作的流程,此后我们不再将本端和对端称为“发送”和“接收”端,而是改为“请求”和“响应”端,这样对于描述 WRITE 和 READ 操作都更恰当一些,也不容易产生歧义。
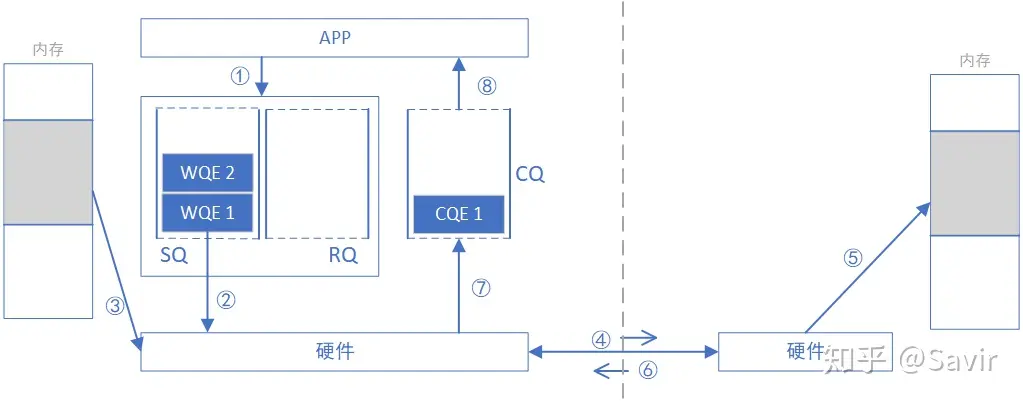
- 请求端 APP 以 WQE(WR)的形式下发一次 WRITE 任务。
- 请求端硬件从 SQ 中取出 WQE,解析信息。
- 请求端网卡根据 WQE 中的虚拟地址,转换得到物理地址,然后从内存中拿到待发送数据,组装数据包。
- 请求端网卡将数据包通过物理链路发送给响应端网卡。
- 响应端收到数据包,解析目的虚拟地址,转换成本地物理地址,解析数据,将数据放置到指定内存区域。
- 响应端回复 ACK 报文给请求端。
- 请求端网卡收到 ACK 后,生成 CQE,放置到 CQ 中。
- 请求端 APP 取得任务完成信息。
注:严谨地说,第 6 步回复 ACK 之时,RDMA 网卡只能保证数据包中的 Payload 已经被”暂存“了下来,但不能保证一定已经把数据放到目的内存里面了。不过这一点不影响我们对整理流程的理解,感谢@nekomii 同学的提醒。
IB Spec. 9.7.5.1.6 ACKNOWLEDGE MESSAGE SCHEDULING 原文:”For SEND or RDMA WRITE requests, an ACK may be scheduled before data is actually written into the responder’s memory. The ACK simply indicates that the data has successfully reached the fault domain of the responding node. That is, the data has been received by the channel adapter and the channel adapter will write that data to the memory system of the responding node, or the responding application will at least be informed of the failure.“
# READ
顾名思义,READ 跟 WRITE 是相反的过程,是本端主动读取远端内存的行为。同 WRITE 一样,远端 CPU 不需要参与,也不感知数据在内存中被读取的过程。
获取 key 和虚拟地址的流程也跟 WRITE 没有区别,需要注意的是 “读”这个动作所请求的数据,是在对端回复的报文中携带的。
下面描述一次 READ 操作的流程,注意跟 WRITE 只是方向和步骤顺序的差别。
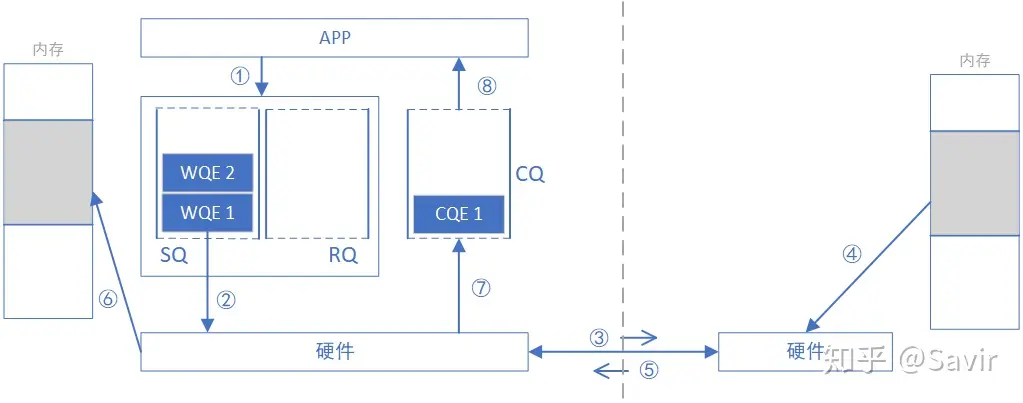
- 请求端 APP 以 WQE 的形式下发一次 READ 任务。
- 请求端网卡从 SQ 中取出 WQE,解析信息。
- 请求端网卡将 READ 请求包通过物理链路发送给响应端网卡。
- 响应端收到数据包,解析目的虚拟地址,转换成本地物理地址,解析数据,从指定内存区域取出数据。
- 响应端硬件将数据组装成回复数据包发送到物理链路。
- 请求端硬件收到数据包,解析提取出数据后放到 READ WQE 指定的内存区域中。
- 请求端网卡生成 CQE,放置到 CQ 中。
- 请求端 APP 取得任务完成信息。
# 总结
我们忽略各种细节进行抽象,RDMA WRITE 和 READ 操作就是在利用网卡完成下面左图的内存拷贝操作而已,只不过复制的过程是由 RDMA 网卡通过网络链路完成的;而本地内存拷贝则如下面右图所示由 CPU 通过总线完成的:
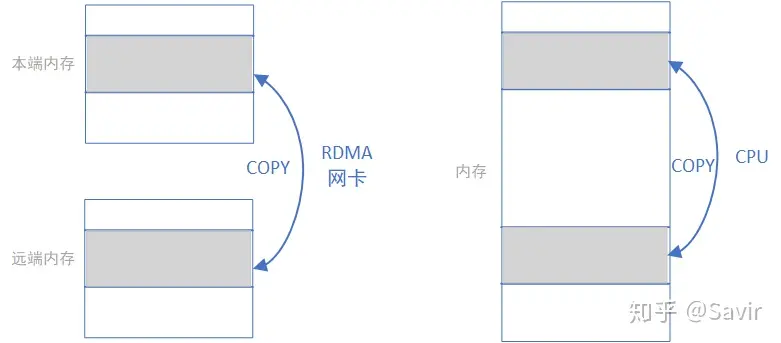
RDMA 标准定义上述几种操作的时候使用的单词是非常贴切的,“收”和“发”是需要有对端主动参与的语义 ,而‘读“和”写“更像是本端对一个没有主动性的对端进行操作的语义。
通过对比 SEND/RECV 和 WRITE/READ 操作,我们可以发现传输数据时不需要响应端 CPU 参与的 WRITE/READ 有更大的优势,缺点就是请求端需要在准备阶段获得响应端的一段内存的读写权限。但是实际数据传输时,这个准备阶段的功率和时间损耗都是可以忽略不计的,所以 RDMA WRITE/READ 才是大量传输数据时所应用的操作类型,SEND/RECV 通常只是用来传输一些控制信息。
除了本文介绍的几种操作之外,还有 ATOMIC 等更复杂一些的操作类型,将在后面的协议解读部分详细分析。本篇就到这里,下一篇将介绍 RDMA 基本服务类型。
# 代码示例
本文中的操作类型都是通过 WQE 来下发的,下面是一个简单的例子,展示了如何使用 libibverbs 来创建一个 QP,然后通过 WQE 来下发一个 WRITE 操作。
| |
# 参考资料
[1] part1-OFA_Training_Sept_2016.pdf