
近年来,大型语言模型(LLM)以其强大的文本生成和理解能力,成为了人工智能领域的中坚力量。商业 LLM 的价格通常高昂且代码封闭,限制了研究者和开发者的探索空间。幸运的是,开源社区提供了像 Ollama 这样优秀的替代方案,让每个人都能够轻松体验 LLM 的魅力,并能结合 HPC 和 IDE 插件,打造更强大的个人助手。
# 什么是 Ollama?
Ollama 是一个用于构建大型语言模型应用的工具,它提供了一个简洁易用的命令行界面和服务器,让你能够轻松下载、运行和管理各种开源 LLM。与需要复杂配置和强大硬件的传统 LLM 不同,Ollama 让你能够方便地像使用手机 App 一样体验 LLM 的强大功能。
# Ollama 的优势
Ollama 拥有以下显著优势:
- 开源免费: Ollama 及其支持的模型完全开源免费,任何人都可以自由使用、修改和分发。
- 简单易用: 无需复杂的配置和安装过程,只需几条命令即可启动和运行 Ollama。
- 模型丰富: Ollama 支持 Llama 3、Mistral、Qwen2 等众多热门开源 LLM,并提供一键下载和切换功能。
- 资源占用低: 相比于商业 LLM,Ollama 对硬件要求更低,即使在普通笔记本电脑上也能流畅运行。
- 社区活跃: Ollama 拥有庞大且活跃的社区,用户可以轻松获取帮助、分享经验和参与模型开发。
# 如何使用 Ollama?
使用 Ollama 非常简单,只需要按照以下步骤:
- 安装 Ollama: 根据你的操作系统,从 Ollama 官网 下载并安装最新版本。
- 启动 Ollama: 打开终端或命令行,输入
ollama serve命令启动 Ollama 服务器。 - 下载模型: 在模型仓库
找到想要的模型,然后使用
ollama pull命令下载,例如ollama pull llama3:70b。 - 运行模型: 使用
ollama run命令启动模型,例如ollama run llama3:70b。 - 开始聊天: 在终端中输入你的问题或指令,Ollama 会根据模型生成相应的回复。
# 安装 Ollama
# macOS
# Windows
# Linux
| |
# Docker
# CPU 版本
| |
# GPU 版本
- 安装 Nvidia container toolkit
- 在 Docker 容器中运行 Ollama
| |
# 启动 Ollama
| |
输出以下信息表示 Ollama 服务器已成功启动(V100 机器):
| |
# 下载模型
| |
# 运行模型
| |
例如,运行如下命令后:
| |
# Docker 容器中运行模型
| |
# 配置 Ollama
Ollama 提供了多种环境变量以供配置:
OLLAMA_DEBUG:是否开启调试模式,默认为false。OLLAMA_FLASH_ATTENTION:是否闪烁注意力,默认为true。OLLAMA_HOST:Ollama 服务器的主机地址,默认为空。OLLAMA_KEEP_ALIVE:保持连接的时间,默认为5m。OLLAMA_LLM_LIBRARY:LLM 库,默认为空。OLLAMA_MAX_LOADED_MODELS:最大加载模型数,默认为1。OLLAMA_MAX_QUEUE:最大队列数,默认为空。OLLAMA_MAX_VRAM:最大虚拟内存,默认为空。OLLAMA_MODELS:模型目录,默认为空。OLLAMA_NOHISTORY:是否保存历史记录,默认为false。OLLAMA_NOPRUNE:是否启用剪枝,默认为false。OLLAMA_NUM_PARALLEL:并行数,默认为1。OLLAMA_ORIGINS:允许的来源,默认为空。OLLAMA_RUNNERS_DIR:运行器目录,默认为空。OLLAMA_SCHED_SPREAD:调度分布,默认为空。OLLAMA_TMPDIR:临时文件目录,默认为空。
# 进阶用法:HPC 集群上部署 Ollama
对于大型模型或需要更高性能的情况,可以利用 HPC 集群的强大算力来运行 Ollama。结合 Slurm 进行任务管理,并使用端口映射将服务暴露到本地,即可方便地进行远程访问和使用:
- 在登录节点配置 Ollama 环境: 安装 Ollama,并下载需要的模型。
- 编写 slurm 脚本: 指定资源需求(CPU、内存、GPU 等),并使用
ollama serve命令启动模型服务,并绑定到特定端口。
| |
- 提交 slurm 任务: 使用
sbatch命令提交脚本,Slurm 会将任务分配到计算节点运行。 - 本地端口映射: 使用 ssh -L 命令将计算节点的端口映射到本地,例如:
| |
- 本地访问: 在浏览器或应用程序中访问 http://localhost:11434 即可使用 Ollama 服务。
重要
注意:由于计算节点不联网,需要提前在登录节点使用
ollama pull下载所需模型。此外,需要设置OLLAMA_ORIGINS为*,设置OLLAMA_HOST为0.0.0.0,以允许所有来源访问服务。
# 进阶用法:本地代码补全助手
Ollama 不仅可以用于聊天和文本创作,还可以结合代码生成模型和 IDE 插件,打造强大的代码补全助手。例如,使用 Codeqwen 7B 模型和 VS Code 插件 Continue ,可以实现高效便捷的代码补全功能。
首先介绍一下 Continue :
Continue enables you to easily create your own coding assistant directly inside Visual Studio Code and JetBrains with open-source LLMs. All this can run entirely on your own laptop or have Ollama deployed on a server to remotely power code completion and chat experiences based on your needs.
Continue 使您能够轻松地在 Visual Studio Code 和 JetBrains 中创建自己的代码助手,利用开源 LLM。这一切都可以完全在您的笔记本电脑上运行,或者在服务器上部署 Ollama,远程根据您的需求提供代码补全和聊天体验。
― Continue
在开始之前,你需要安装如下工具:
接下来,我们以 VS Code 为例,介绍如何使用 Ollama + Continue 实现代码补全功能:
# Codestral 22B 模型
Codestral 既能完成代码自动补全,也支持聊天功能。但鉴于其拥有 220 亿参数且不具备生产许可,它对显存要求颇高,仅限于研究和测试使用,因此可能并不适合日常本地应用。
# 下载并运行 Codestral 模型
| |
# 配置 config.json
- 在 VS Code 侧边栏点击 Continue 插件图标,然后在面板右下角点击 “齿轮” 图标,打开
config.json文件。然后复制以下配置到config.json文件中:
| |
# DeepSeek Coder 6.7B 模型 + Llama 3 8B 模型
根据机器的显存大小,可以利用 Ollama 同时运行多个模型并处理多个并发请求的能力,使用 DeepSeek Coder 6.7B 进行自动补全,Llama 3 8B 进行聊天。如果你的机器无法同时运行两者,那么可以分别尝试,决定你更偏好本地自动补全还是本地聊天体验。
# 下载并运行 DeepSeek Coder 模型
| |
# 下载并运行 Llama 3 模型
| |
# 配置 config.json
| |
# Codeqwen 7B 模型 + Qwen2 7B 模型
Codeqwen 7B 模型是一个专门用于代码补全的模型,而 Qwen2 7B 模型则是一个通用的聊天模型。这两个模型可以很好地结合在一起,实现代码补全和聊天功能。
# 下载并运行 Codeqwen 模型
| |
# 下载并运行 Qwen2 模型
| |
# 配置 config.json
| |
# 利用 RAG 向量检索优化聊天
Continue 内置了 @codebase 上下文提供器,能自动从代码库中检索到最相关的代码片段。假如你已经设置好了聊天模型(例如 Codestral、Llama 3),那么借助 Ollama 和 LanceDB 的向量化技术,可以实现更高效的代码检索和聊天体验。
这里,我们使用 nomic-embed-text 模型作为向量检索模型:
# 下载并运行 Nomic Embed Text 模型
| |
# 配置 config.json
- 在文件中添加以下内容:
| |
# 代码补全效果
Ctrl + I: 根据指令生成代码片段。


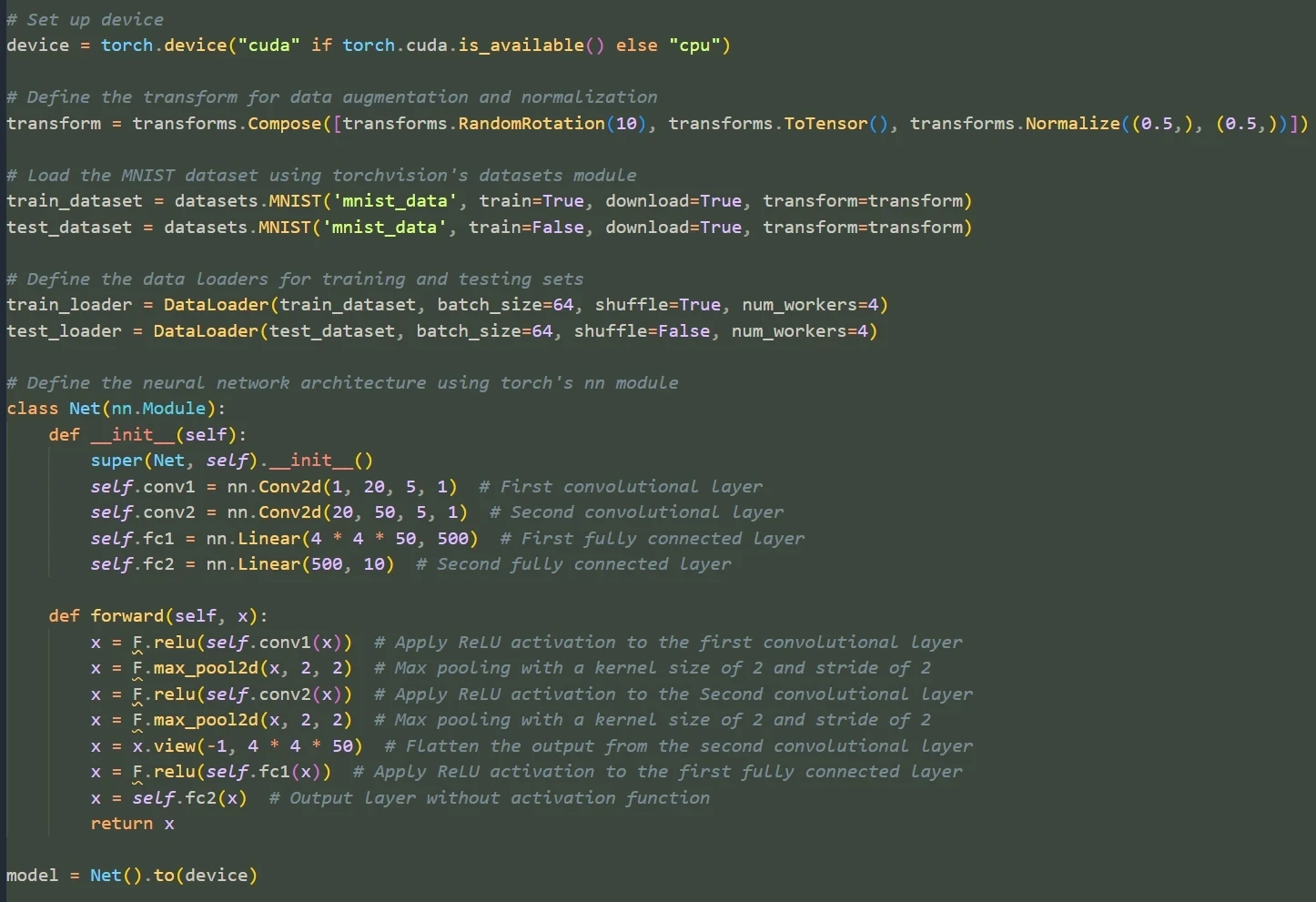
- 光标悬停自动补全代码
# 与 Ollama 聊天

# 代码自动注释
- 选中代码打开右键菜单
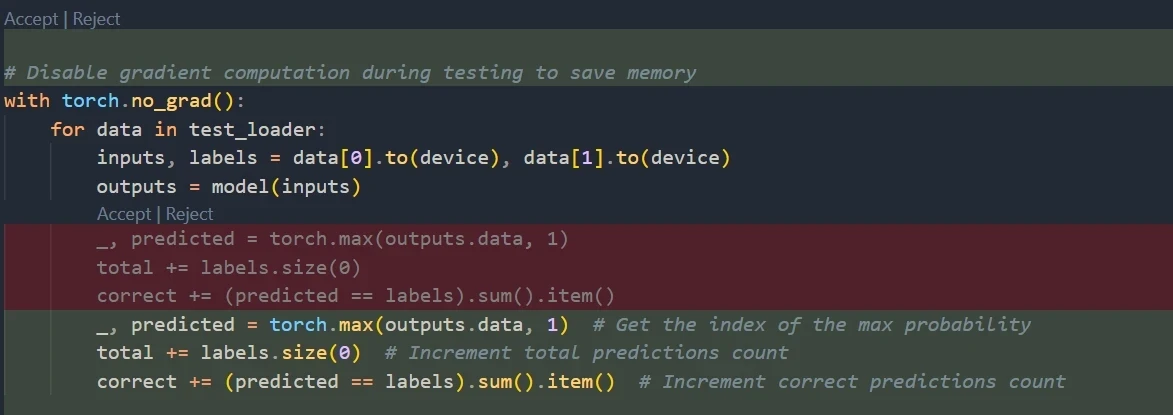
# 总结
Ollama 为我们打开了通往开源 LLM 世界的大门,让每个人都能轻松体验 LLM 的强大功能,并可以根据自身需求进行定制化应用。无论是进行研究、开发,还是日常使用,Ollama 都能为你提供探索 LLM 无限可能的平台。相信随着 Ollama 的不断发展,它将为我们带来更多惊喜,推动 LLM 技术在各个领域的应用和发展。