
# 1. 动态进程
MPI-1 假定所有的进程都是静态的,运行时不能增加和删除进程。MPI-2 引入了动态进程的概念:
- MPI-1 不定义如何创建进程和如何建立通信。MPI-2 中的动态进程机制以可移植的方式(平台独立)提供了这种能力。
- 动态进程有利于将 PVM 程序移植到 MPI 上。并且还可能支持一些重要的应用类型, 如 Client/Server 和 Process farm。
- 动态进程允许更有效地使用资源和负载平衡。例如,所用节点数可以按需要减少和增加。
- 支持容错。当一个节点失效时,可以在另一个节点上创建一个新进程运行该节点上的进程的工作。
在 MPI-1 中 一个 MPI 程序一旦启动,一直到该 MPI 程序结束,进程的个数是固定的,在程序运行过程中是不可能动态改变的。在 MPI-2 中,允许在程序运行过程中动态改变进程的数目,并提供了动态进程创建和管理的各种调用。
组间通信域在动态进程管理中处于核心的地位,只有掌握了它的基本概念,才能准确把握和使用进程的动态特性和动态进程之间的通信。
在 MPI-2 中,对点到点通信和组通信都给出了使用组间通信域时的确切含义。在语法上,不管是使用组内还是组间通信域,二者没有任何区别,但其语义是不同的。
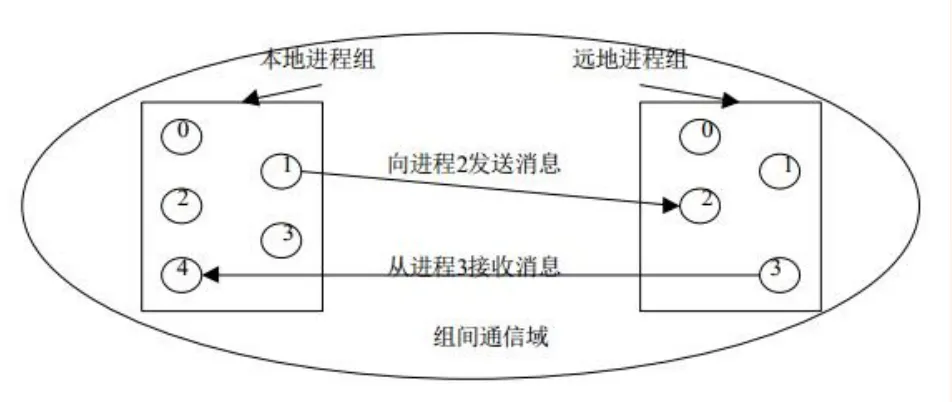
- 对于构成组间通信域的两个进程组,调用进程把自己所在的组看作是本地组,而把另一个组称为远地组,使用组间通信域的一个特点是本地组进程发送的数据被远地组进程接收而本地组接收的数据必然来自远地组。
- 在使用组间通信域的点到点通信中,发送语句指定的目的进程是远地组中的进程编号,接收进程指出的源进程编号也是远地组的进程编号。
- 如图所示为组间通信域上的点到点通信
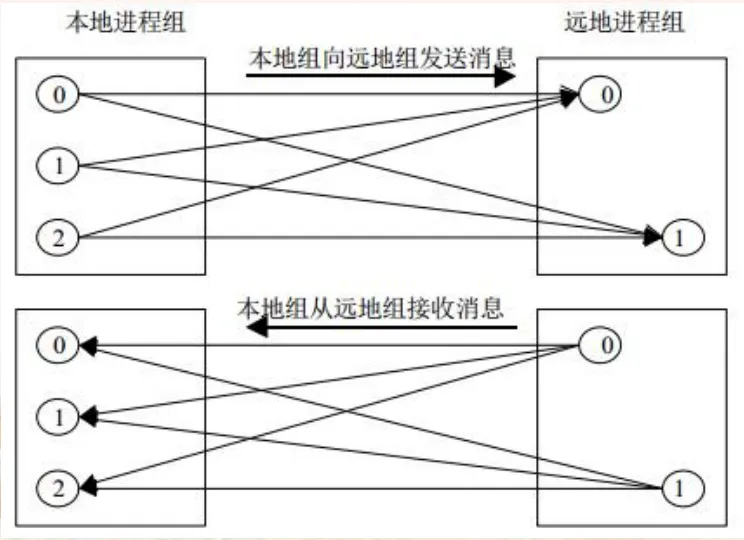
对于组通信,如果使用组间通信域,则其含义分不同的形式而有所不同:对于多对多通信,本地进程组的所有进程向远地进程组的所有进程发送数据,同时本地进程组的所有进程从远地进程组的所有进程接收数据,如图所示:
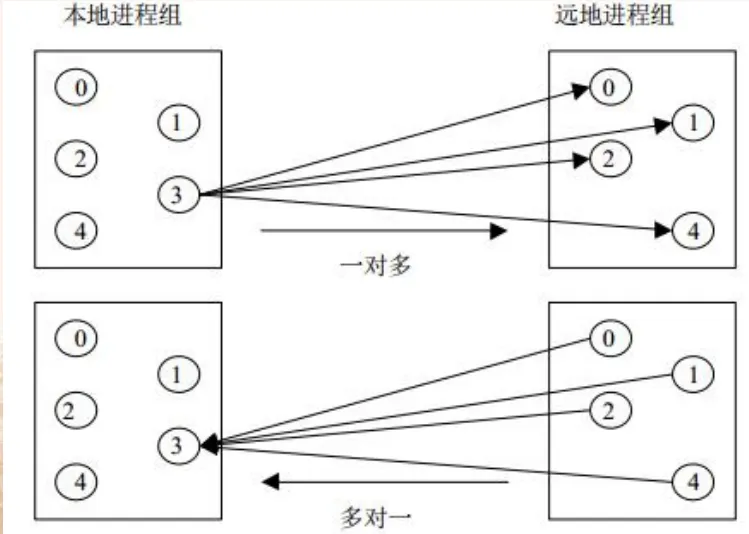
- 此外,组间通信域上的一对多通信或多对一通信如图所示:
注释
示例 1:动态进程的创建和通信
| |
- 在 16 个进程中,每两个进程一组,共 8 组,每组的进程编号相同,运行结果如下:
| |
注释
示例 2:更复杂的动态进程的创建和通信
| |
# 2. 远程存储访问(Remote Memory Access,RMA)
- 在 MPI-2 中增加远程存储访问的能力,主要是为了使 MPI 在编写特定算法和通信模型的并行程序时更加自然和简洁。因为在许多情况下,都需要一个进程对另外一个进程的存储区域进行直接访问。
- MPI-2 对远程存储的访问主要是通过窗口来进行的,为了进行远程存储访问,首先需要定义一个窗口,该窗口开在各个进程的一段本地进程存储空间,其目的是为了让其它的进程可以通过这一窗口来访问本地的数据。
- 定义好窗口之后,就可以通过窗口来访问远程存储区域的数据了。MPI-2 提供了三种基本的访问形式,即读、写和累计,读操作只是从远端的窗口获取数据,并不对远端数据进行任何修改;写操作将本地的内容写入远端的窗口,它修改远端窗口的内容;累计操作就更复杂一些,它将远端窗口的数据和本地的数据进行某种指定方式的运算之后,再将运算的结果写入远端窗口。
- MPI-2 就是通过读、写和累计三种操作来实现对远程存储的访问和更新的。除了基本的窗口操作之外 MPI-2 还提供了窗口管理功能 用来实现对窗口操作的同步管理。MPI-2 对窗口的同步管理有三种方式 :
- 栅栏方式 fence:在这种方式下,对窗口的操作必须放在一对栅栏语句之间,这样可以保证当栅栏语句结束之后,其内部的窗口操作可以正确完成。
- 握手方式:在这种方式下,调用窗口操作的进程需要将具体的窗口调用操作放在以 MPI_WIN_START 开始,以 MPI_WIN_COMPLETE 结束的调用之间。相应的,被访问的远端进程需要以一对调用 MPI_WIN_POST 和 MPI_WIN_WAIT 与之相适应。MPI_WIN_POST 允许其它的进程对自己的窗口进行访问,而 MPI_WIN_WAIT 调用结束之后可以保证对本窗口的调用操作全部完成。MPI_WIN_START 申请对远端进程窗口的访问,只有当远端窗口执行了 MPI_WIN_POST 操作之后才可以访问远端窗口,MPI_WIN_COMPLETE 完成对远端窗口访问操作。
- 锁方式:在这种方式下,不同的进程通过对特定的窗口加锁来实现互斥访问。当然用户根据需要可以使用共享的锁,这是就可以允许使用共享锁的进程对同一窗口同时访问。远端存储的访问窗口是具体的实现形式,通过窗口操作实现来实现单边通信,通过对窗口的管理操作来实现对窗口操作的同步控制。
| 窗口操作 | 说明 |
|---|---|
| MPI_Win_create | 创建窗口 |
| MPI_Win_free | 释放窗口 |
| MPI_Win_fence | 栅栏同步 |
| MPI_Win_start | 握手同步 |
| MPI_Win_complete | 握手同步 |
| MPI_Win_post | 握手同步 |
| MPI_Win_wait | 握手同步 |
| MPI_Win_lock | 锁同步 |
| MPI_Win_unlock | 锁同步 |
| MPI_Win_test | 锁同步 |
| MPI_Win_lock_all | 锁同步 |
| MPI_Win_unlock_all | 锁同步 |
| MPI_Win_flush | 锁同步 |
| MPI_Win_flush_all | 锁同步 |
| MPI_Win_flush_local | 锁同步 |
| MPI_Win_flush_local_all | 锁同步 |
| MPI_Win_shared_query | 查询窗口 |
- 小结:窗口是远程存储访问中的重要概念,其实 MPI-2 的远程存储访问就是各进程将自己的一部分内存区域开辟成其它所有进程都可以访问的窗口,从而使其它的进程实现对自己数据的远程访问,窗口操作是相对简单的,对窗口访问的同步控制是需要注意的问题。
注释
示例 3:远程存储访问
| |
# 3. 并行 I/O(MPI-IO)
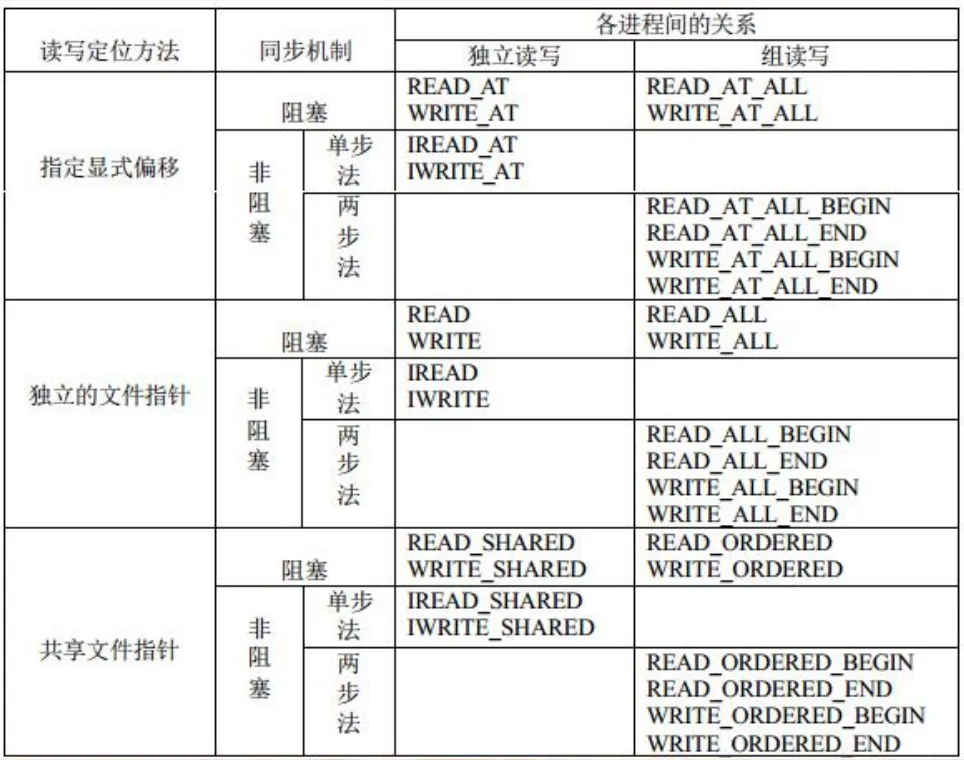
MPI-1 没有对并行文件 I/O 给出任何定义,原因在于并行 I/O 过于复杂,很难找到一个统一的标准。但是,I/O 是很多应用不可缺少的部分,MPI-2 在大量实践的基础上,提出了一个并行 I/O 的标准接口。MPI-2 提供的关于并行文件 I/O 的调用十分丰富,根据读写定位方法的不同,可以分为三种:
- 指定显示的偏移:这种调用没有文件指针的概念 每次读写操作都必须明确指定读写文件的位置。
- 各进程拥有独立的文件指针:这种方式的文件操作不需要指定读写的位置每一个进程都有一个相互独立的文件指针,读写的起始位置就是当前指针的位置。读写完成后文件指针自动移到下一个有效数据的位置。这种方式的文件操作需要每一个进程都定义各自在文件中的文件视图(view),文件视图(view)数据是文件连续或不连续的一部分,各个进程对文件视图(view)的操作就如同是对一个打开的独立的连续文件的操作一样。
- 共享文件指针:在这种情况下,每一个进程对文件的操作都是从当前共享文件指针的位置开始,操作结束后共享文件指针自动转移到下一个位置。共享指针位置的变化对所有进程都是可见的,各进程使用的是同一个文件指针。任何一个进程对文件的读写操作都会引起其它所有进程文件指针的改变。
- MPI-IO 文件访问过程
- 在进行 I/O 之前,必须要通过调用 MPI_File_open 打开文件
- 每个进程都需要定义文件指针用来控制文件访问
- I/O 操作完成后,必须通过调用 MPI_File_close 来关闭文件
- 并行文件的基本操作
- 打开:
MPI_File_open(comm, filename, amode, info, fh)- comm:组内通信域
- filename:文件名
- amode:打开模式
- info:传递给运行时的信息
- fh:返回的文件句柄
文件访问模式 含义 MPI_MODE_RDONLY 只读 MPI_MODE_RDWR 读写 MPI_MODE_WRONLY 只写 MPI_MODE_CREATE 若文件不存在则创建 MPI_MODE_EXCL 创建不存在的新文件,若文件已存在则报错 MPI_MODE_DELETE_ON_CLOSE 关闭文件时删除文件 MPI_MODE_UNIQUE_OPEN 文件只能被一个进程打开 MPI_MODE_SEQUENTIAL 文件只能被顺序访问 MPI_MODE_APPEND 追加方式打开,初始文件指针指向文件末尾
- 关闭:
MPI_File_close(fh)- fh:文件句柄
- 删除:
MPI_File_delete(filename, info)- filename:文件名
- info:传递给运行时的信息
- 修改文件大小:
MPI_File_set_size(fh, size)- fh:文件句柄
- size:新的文件大小(字节)
- 查看文件大小:
MPI_File_get_size(fh, size)- fh:文件句柄
- size:文件大小(字节)
- 预申请空间:
MPI_File_preallocate(fh, size)- fh:文件句柄
- size:预申请的空间大小(字节)
- 打开:
注释
示例 4:并行 I/O - 指定显示偏移并行读
| |
- tesfile 文件内容为:
| |
- 运行结果为:
| |
# 4. 正确地使用 MPI-IO
- 正确使用 MPI-IO
- 根据 I/O 需求,每个应用都有其特定的 I/O 访问模式
- 对于不同的 I/O 系统,同样的 I/O 访问模式也可以使用不同的 I/O 函数和 I/O 方式实现
- 通常 MPI-IO 中 I/O 访问模式的实现方式可分为 4 级:level0-level3
- 以分布式数组访问为例
- level0:每个进程对本地数组的一行发出一个独立的读请求(就像在 unix 中一样)
1 2 3 4 5 6 7MPI_File_open(..., file, ..., &fh); for (i = 0; i < n_local_rows; i++) { MPI_File_seek(fh, ...); MPI_File_read(fh, &(A[i][0]), ...); } MPI_File_close(&fh); - level1:类似于 level 0,但每个过程都使用集合 I/O 函数
1 2 3 4 5 6 7MPI_File_open(MPI_COMM_WORLD, file, ...,&fh); for (i = 0; i < n_local_rows; i++) { MPI_File_seek(fh, ...); MPI_File_read_all(fh, &(A[i][0]), ...); } MPI_File_close(&fh); - level2:每个进程创建一个派生数据类型来描述非连续访问模式,定义一个文件视图,并调用独立的 I/O 函数
1 2 3 4 5 6MPI_Type_create_subarray(...,&subarray, ...); MPI_Type_commit(&subarray); MPI_File_open(..., file, ..., &fh); MPI_File_set_view(fh, ..., subarray, ...); MPI_File_read(fh, A, ...); MPI_File_close(&fh); - level3:类似于 level 0,但每个过程都使用集合 I/O 函数
1 2 3 4 5 6MPI_Type_create_subarray(...,&subarray, ...); MPI_Type_commit(&subarray); MPI_File_open(MPI_COMM_WORLD, file,...,&fh); MPI_File_set_view(fh, ..., subarray, ...); MPI_File_read_all(fh, A, ...); MPI_File_close(&fh);
# 5. 总结
- MPI-IO 有许多功能,可以帮助用户获得高性能 I/O
- 支持非连续性访问
- 派生数据类型
- 文件视图
- 集合 I/O
- 支持非连续性访问
- 用户应该根据应用程序 I/O 特性来选择适合的 I/O 访问模式实现
- 同时,MPI-IO 不是实现并行 I/O 的唯一选择。目前已有一些更高级的库可代替 MPI-IO
- HDF5、netCDF……
- 这些库都是基于 MPI-IO 实现