
# 1. 预定义数据类型
MPI 支持异构计算(Heterogeneous Computing),它指在不同计算机系统上运行程序,每台计算可能有不同生产厂商,不同操作系统。 MPI 通过提供预定义数据类型来解决异构计算中的互操作性问题,建立它与具体语言的对应关系。
- MPI 中预定义的数据类型如下:
| MPI 数据类型(C 语言绑定) | C 语言数据类型 |
|---|---|
| MPI_CHAR | char |
| MPI_SHORT | short |
| MPI_INT | int |
| MPI_LONG | long |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short |
| MPI_UNSIGNED | unsigned |
| MPI_UNSIGNED_LONG | unsigned long |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | 无 |
| MPI_PACKED | 无 |
但是,对于点对点通信,仅仅使用包含一系列相同基本数据类型的缓冲区是不够的。我们经常要传递包含不同数据类型值的信息(例如一个整数变量 count,然后是一串实数);并且我们经常要发送不连续的数据(例如,矩阵的一个子块)。
OpenMPI 为发送非连续数据提供 pack/unpack 函数。用户在发送数据前要明确地将数据打包到连续的缓冲区中,并在接收数据后将其从连续的缓冲区中解包。虽然使用这些函数可以实现非连续数据的发送,但是这种方式不够灵活,而且效率低下。不过为了与以前的库或代码兼容,下面提供了这两个函数的使用方法。
| |
inbuf:输入缓冲区的起始地址incount:输入缓冲区中数据的个数datatype:输入缓冲区中数据的类型outbuf:输出缓冲区的起始地址outsize:输出缓冲区的大小position:输出缓冲区中的位置comm:通信域
| |
inbuf:输入缓冲区的起始地址insize:输入缓冲区的大小position:输入缓冲区中的位置outbuf:输出缓冲区的起始地址outcount:输出缓冲区中数据的个数datatype:输出缓冲区中数据的类型comm:通信域
注释
示例 1:Pack/Unpack
| |
# 2. 派生数据类型
- MPI 提供了全面而强大的 构造函数(Constructor Function) 来定义派生数据类型。派生数据类型是一种抽象的数据结构,可以用来描述数据的组织形式,而不是数据本身。
- 派生数据类型可以用类型图来描述,这是一种通用的类型描述方法,它是一系列二元组<基类型,偏移>的集合,可以表示成如下格式:
| |
在派生数据类型中,基类型可以是任何 MPI 预定义数据类型,也可以是其它的派生数据类型,即支持数据类型的嵌套定义。
如图,阴影部分是基类型所占用的空间,其它空间可以是特意留下的,也可以是为了方便数据对齐。
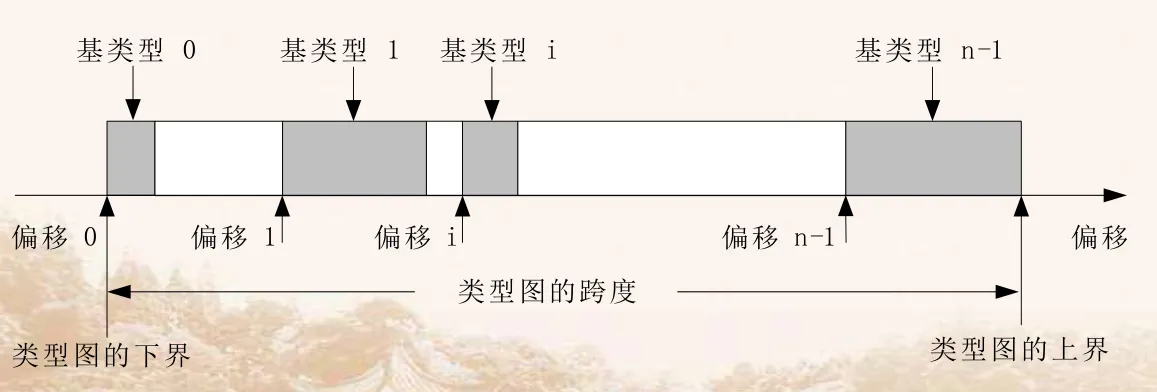
基类型指出了该类型图中包括哪些基本的数据类型,而偏移则指出该基类型在整个类型图中的起始位置,基类型可以是预定义类型或派生类型,偏移可正可负,没有递增或递减的顺序要求,而一个类型图中包括的所有基类型的集合称为某类型的类型表,表示为:
| |
- 将类型图和一个数据缓冲区的基地址结合起来 可以说明一个通信缓冲区内的数据分布情况
- 预定义数据类型是通用数据类型的特例,比如 MPI_INT 是一个预先定义好了的数据类型句柄,其类型图为
{(int, 0)},有一个基类型入口项 int 和偏移 0,其它的基本数据类型与此相似,数据类型的跨度被定义为该数据类型的类型图中从第一个基类型到最后一个基类型间的距离 - 即如果某一个类型的类型图为:
| |
- 则该类型图的下界定义为:
| |
- 该类型图的上界定义为:
| |
- 该类型图的跨度定义为:
| |
由于不同的类型有不同的对齐位置的要求 e(extent)就是能够使类型图的跨度满足该类型的类型表中的所有的类型都能达到下一个对齐要求所需要的最小非负整数值
假设
type={(double, 0), (char, 8)},进一步假设 double 型的值必须严格分配到地址为 8 的倍数的存储空间,则该数据类型的 extent 是 16((从 9 循环到下一个 8 的倍数),一个由一个字符后面紧跟一个双精度值的数据类型,其 extent 也是 16在 MPI 中,派生数据类型的构造函数有如下几种:
| 函数名 | 含义 |
|---|---|
| MPI_Type_contiguous | 定义由相同数据类型的元素组成的类型 |
| MPI_Type_vector | 定义由成块的元素组成的类型,块之间具有相同间隔 |
| MPI_Type_indexed | 定义由成块的元素组成的类型,块长度和偏移由参数指定 |
| MPI_Type_struct | 定义由不同数据类型的元素组成的类型 |
| MPI_Type_commit | 提交一个派生数据类型 |
| MPI_Type_free | 释放一个派生数据类型 |
(1)最简单的数据类型构造函数是 MPI_Type_contiguous ,它允许将数据类型复制到连续位置。

| |
count: 重复的次数oldtype: 基本数据类型newtype: 派生数据类型
注释
示例 2: MPI_Type_contiguous 的使用
| |
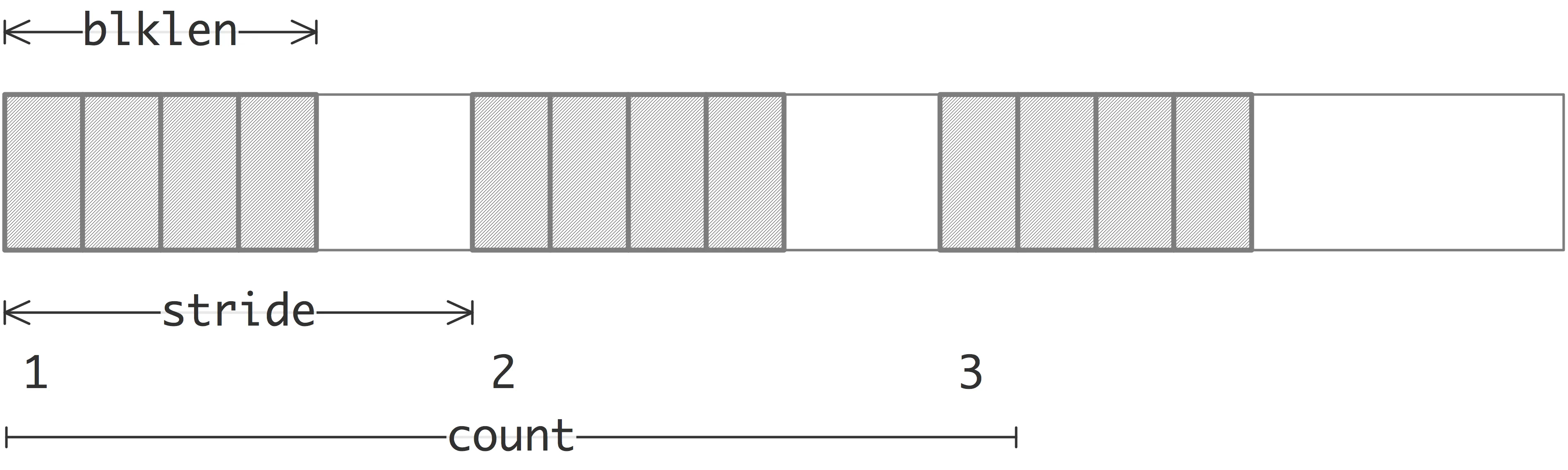
(2)函数 MPI_Type_vector 是一个更通用的构造函数,它允许将数据类型复制到由等间距块组成的位置。每个块都是通过连接相同数量的旧数据类型副本来获得的。块之间的间距是旧数据类型范围的倍数。
| |
count: 重复的次数blocklength: 每个块中的元素数stride: 旧数据类型的跨度oldtype: 基本数据类型newtype: 派生数据类型
注释
示例 3: MPI_Type_vector 的使用
| |
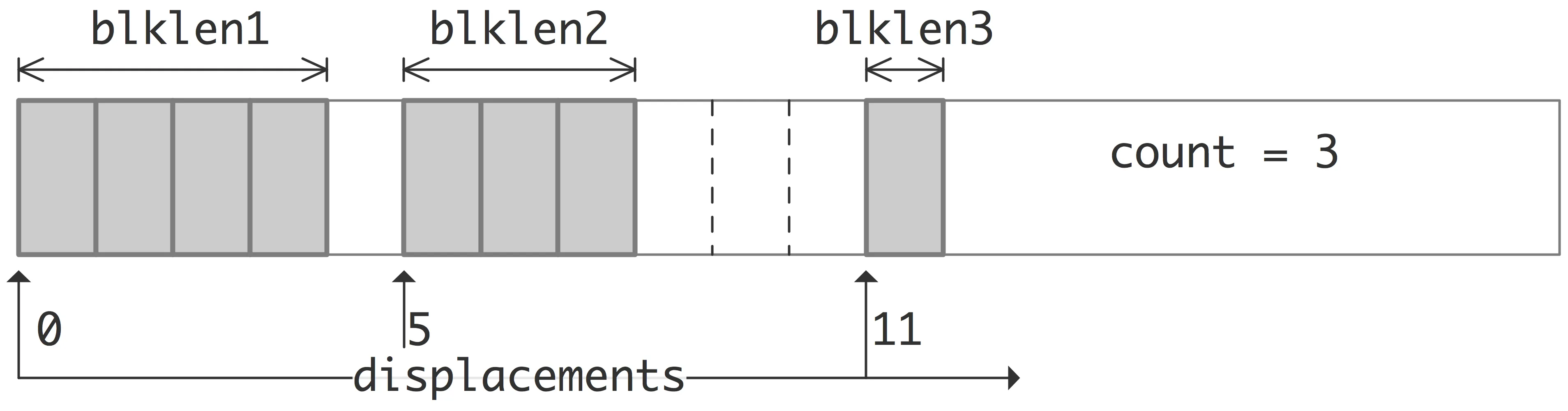
(3)函数 MPI_Type_index 允许将旧数据类型复制到一系列块中(每个块是旧数据类型的串联),其中每个块可以包含不同数量的副本,并且具有不同的位移。所有块位移都是旧类型范围的倍数。
| |
count: 重复的次数array_of_blocklengths: 每个块中的元素数array_of_displacements: 每个块的偏移量oldtype: 基本数据类型newtype: 派生数据类型
注释
示例 4: MPI_Type_indexed 的使用
| |
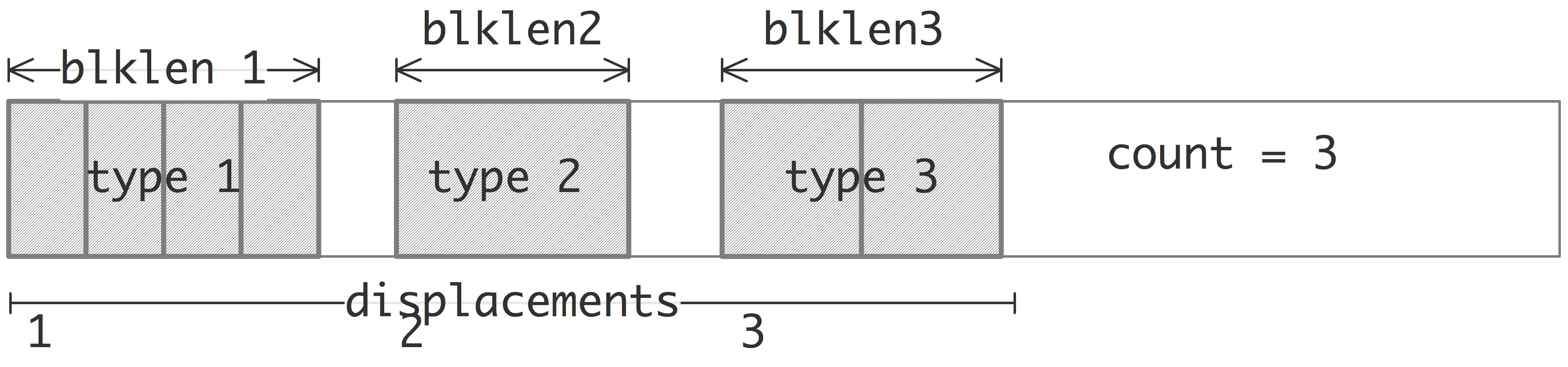
(4)MPI_Type_create_struct 是最通用的类型构造函数。允许程序员定义由组件数据类型的完全定义的映射形成的新数据类型。
| |
count: 重复的次数array_of_blocklengths: 每个块中的元素数array_of_displacements: 每个块的偏移量array_of_types: 每个块的数据类型newtype: 派生数据类型
注释
示例 5:MPI_Type_create_struct 的使用
| |
在这里,偏移量有一个问题。手动计算偏移量可能比较麻烦。虽然这种情况越来越少,但有些类型的大小会因系统/操作系统而异,因此硬编码可能会带来麻烦。一种更简洁的方法是使用标准库中的 offsetof 宏(在 C 语言中必须包含 stddef.h,在 C++ 语言中必须包含 cstddef)。它会返回一个 size_t(可隐式转换为 MPI_Aint),与该属性的偏移量相对应。于是可以将偏移量表定义为:
| |