
# 1. 定义
- 集合通信(Collective Communication):是一个进程组中的所有进程都参加的全局通信操作。
- 特点:
- 通信空间中的所有进程都参与通信操作
- 每一个进程都需要调用该操作函数
数据移动类型
- Broadcast
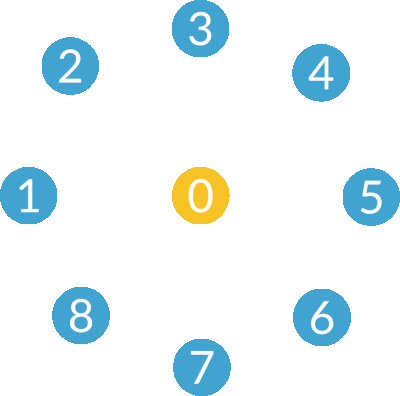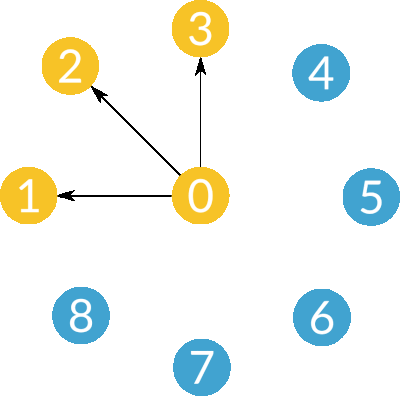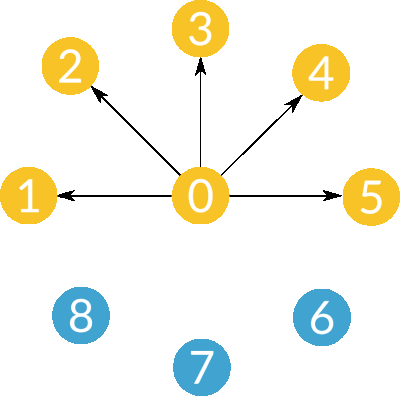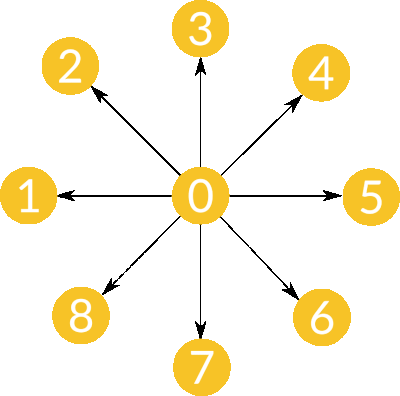
- Scatter
- Gather
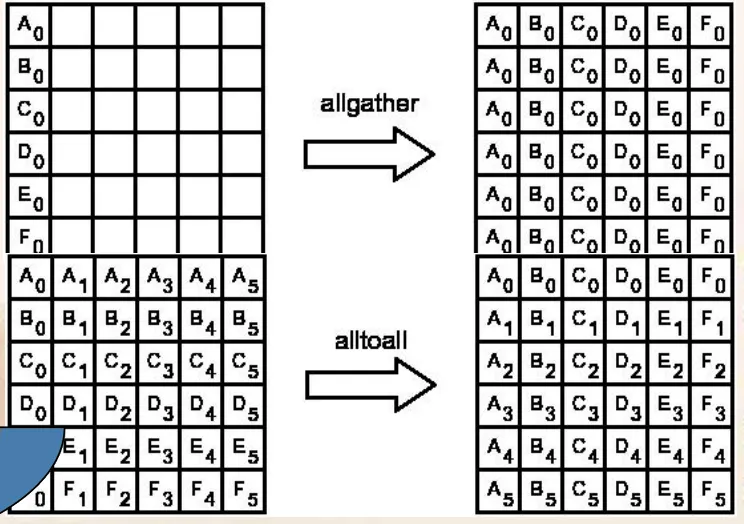
- AllGather
- Alltoall
# 2. 集合通信实现的功能
集合通信一般实现三个功能:通信、聚合和同步
类型 函数名 含义 通信 MPI_Bcast 一对多广播同样的消息 通信 MPI_Gather 多对一收集各个进程的消息 通信 MPI_Gatherv MPI_Gather 的一般化 通信 MPI_Allgather 全局收集 通信 MPI_Allgatherv MPI_Allgather 的一般化 通信 MPI_Scatter 一对多散播不同的消息 通信 MPI_Scatterv MPI_Scatter 的一般化 通信 MPI_Alltoall 多对多全局交换消息 通信 MPI_Alltoallv MPI_Alltoall 的一般化 聚合 MPI_Reduce 多对一规约 聚合 MPI_Allreduce MPI_Reduce 的一般化 聚合 MPI_Scan 多对多扫描 聚合 MPI_Reduce_scatter MPI_Reduce 的一般化 同步 MPI_Barrier 路障同步 通信:集合通信,按照通信方向的不同,又可以分为三种:一对多通信,多对一通信和多对多通信。
一对多通信:一个进程向其它所有的进程发送消息,这个负责发送消息的进程叫做 Root 进程。
多对一通信:一个进程负责从其它所有的进程接收消息,这个接收的进程也叫做 Root 进程。
多对多通信:每一个进程都向其它所有的进程发送或者接收消息。
# 3. 一对多通信:广播
- 广播是一对多通信的典型例子,其调用格式为:
MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
注释
示例 1:广播
| |
- 结果:
| |
- 广播的特点
- 标号为 Root 的进程发送相同的消息给通信域 Comm 中的所有进程。
- 消息的内容如同点对点通信一样由三元组<Address, Count, Datatype>标识。
- 对 Root 进程来说,这个三元组既定义了发送缓冲也定义了接收缓冲。对其它进程来说,这个三元组只定义了接收缓冲
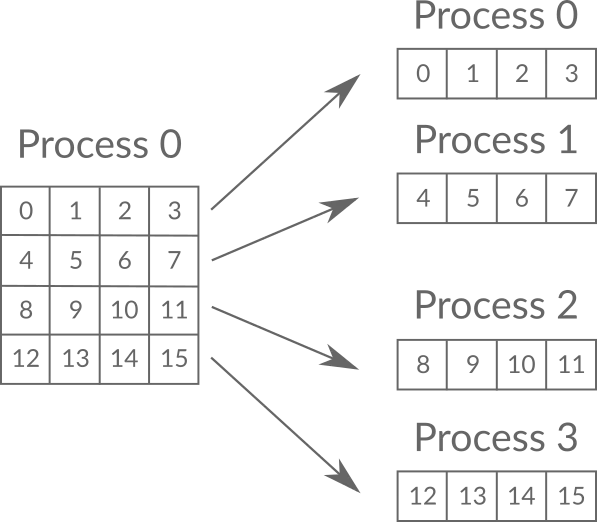
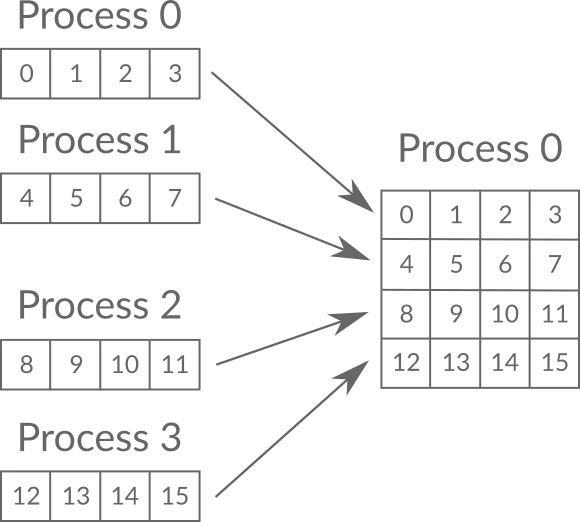
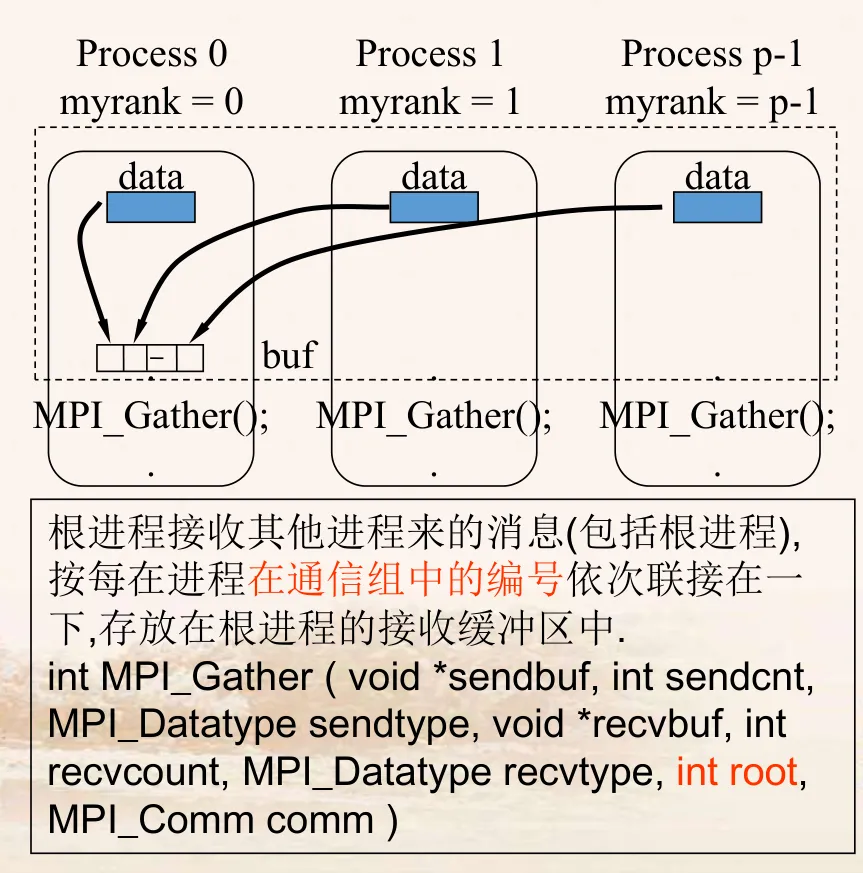
# 4. 多对一通信:收集
- 收集是多对一通信的典型例子,其调用格式为:
MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
注释
示例 2:收集
| |
- 结果:
| |
- 收集的特点
- 在收集操作中,Root 进程从进程域 Comm 的所有进程(包括它自已)接收消息。
- 这 n 个消息按照进程的标识 rank 排序进行拼接,然后存放在 Root 进程的接收缓冲中。
- 接收缓冲由三元组<RecvAddress, RecvCount, RecvDatatype>标识,发送缓冲由三元组<SendAddress, SendCount, SendDatatype>标识,所有非 Root 进程忽略接收缓冲。
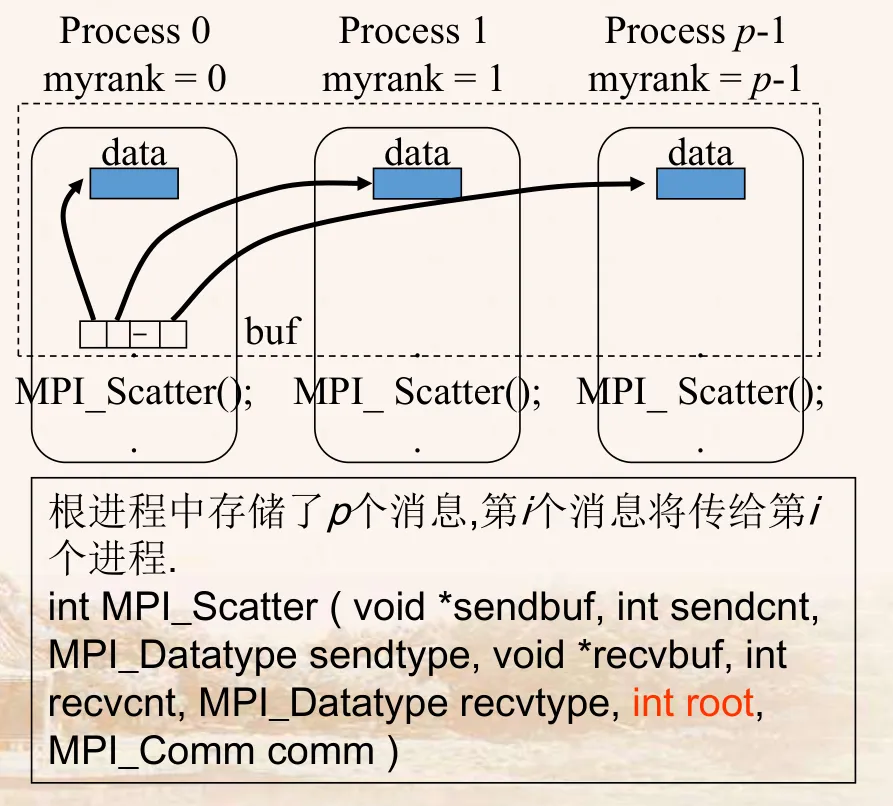
# 5. 一对多通信:散播
- 散播是一个一对多操作,其调用格式为:
MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
注释
示例 3:散播
| |
- 结果:
| |
- 散播的特点
- Scatter 执行与 Gather 相反的操作。
- Root 进程给所有进程(包括它自已)发送一个不同的消息,这 n (n 为进程域 comm 包括的进程个数)个消息在 Root 进程的发送缓冲区中按进程标识的顺序有序地存放。
- 每个接收缓冲由三元组<RecvAddress, RecvCount, RecvDatatype>标识,所有的非 Root 进程忽略发送缓冲。对 Root 进程,发送缓冲由三元组<SendAddress,SendCount, SendDatatype>标识。
# 6. 聚合
- 集合通信的聚合功能使得 MPI 进行通信的同时完成一定的计算。
- MPI 聚合的功能分三步实现:
- 首先是通信的功能,即消息根据要求发送到目标进程,目标进程也已经收到了各自需要的消息
- 然后是对消息的处理,即执行计算功能
- 最后把处理结果放入指定的接收缓冲区
- MPI 提供了两种类型的聚合操作: 归约(Reduce)和扫描(Scan)。
# 7. 同步
- 同步功能用来协调各个进程之间的进度和步伐 。目前 MPI 的实现中支持一个同步操作,即路障同步(Barrier)。
- 路障同步的调用格式为:
MPI_Barrier(MPI_Comm comm)- 在路障同步操作
MPI_Barrier(Comm)中,通信域 Comm 中的所有进程相互同步。 - 在该操作调用返回后,可以保证组内所有的进程都已经执行完了调用之前的所有操作,可以开始该调用后的操作。
- 在路障同步操作
# 8. 规约
MPI_REDUCE 将组内每个进程输入缓冲区中的数据按给定的操作 op 进行运算,并将其结果返回到序列号为 root 的进程的输出缓冲区中,输入缓冲区由参数 sendbuf、count 和 datatype 定义,输出缓冲区由参数 recvbuf count 和 datatype 定义,要求两者的元素数目和类型都必须相同,因为所有组成员都用同样的参数 count、datatype、op、root 和 comm 来调用此例程 故而所有进程都提供长度相同、元素类型相同的输入和输出缓冲区,每个进程可能提供一个元素或一系列元素 组合操作依次针对每个元素进行。
操作 op 始终被认为是可结合的 并且所有 MPI 定义的操作被认为是可交换的,用户自定义的操作被认为是可结合的,但可以不是可交换的。MPI 中已经定义好的一些操作,它们是为函数MPI_Reduce 和一些其他的相关函数,如MPI_Allreduce、MPI_Reduce_scatter 和MPI_Scan 而定义的 这些操作用来设定相应的 op。
MPI 预定的归约操作如下:
| 操作 | 含义 | 操作 | 含义 |
|---|---|---|---|
| MPI_MAX | 最大值 | MPI_MIN | 最小值 |
| MPI_SUM | 求和 | MPI_PROD | 求积 |
| MPI_LAND | 逻辑与 | MPI_BAND | 按位与 |
| MPI_LOR | 逻辑或 | MPI_BOR | 按位或 |
| MPI_LXOR | 逻辑异或 | MPI_BXOR | 按位异或 |
| MPI_MAXLOC | 最大值和位置 | MPI_MINLOC | 最小值和位置 |
注释
示例 4:计算 pi 值
| |