
# 引言
在构建信息检索和生成式 AI 应用时,Retrieval-Augmented Generation (RAG) 模型凭借其能够从知识库中检索相关信息并生成准确答案的强大能力,受到越来越多开发者的青睐。然而,实现端到端的本地 RAG 服务,需求的不只是合适的模型,还需要集成强大的用户界面和高效的推理框架。
在构建本地 RAG 服务时,利用易于部署的 Docker 方式,可以极大简化模型管理和服务集成。这里我们依赖 Open WebUI 提供的用户界面与模型推理服务,再通过 Ollama 来引入 bge-m3 embedding 模型以实现文档向量化方式的检索功能,从而帮助 Qwen2.5 完成更精准的答案生成。
本文我们将讨论如何通过 Docker 快速启动 Open WebUI,同步 Ollama 的 RAG 能力,并结合 Qwen2.5 模型实现高效的文档检索与生成系统。
# 项目概览
该项目将使用以下关键工具:
- Open WebUI : 提供用户与模型交互的 web 界面。
- Ollama : 用于管理 embedding 和大语言模型的模型推理任务。其中 Ollama 中的
bge-m3模型将用于文档检索,Qwen2.5 将负责回答生成。 - Qwen2.5 : 模型部分使用阿里推出的 Qwen 2.5 系列,为检索增强生成服务提供自然语言生成。
为了实现 RAG 服务,我们需要以下步骤:
- 部署 Open WebUI 作为用户交互界面。
- 配置 Ollama 以高效调度 Qwen2.5 系列模型。
- 使用 Ollama 配置的名为
bge-m3的 embedding 模型实现检索向量化处理。
# 部署 Open WebUI
Open WebUI 提供了一个简洁的 Docker 化解决方案,用户无需手动配置大量依赖,直接通过 Docker 启动 Web 界面。
首先,服务器上需要确保已经安装了 Docker ,如果没有安装,可以通过以下命令进行快速安装:
| |
然后创建一个目录用于保存 Open WebUI 的数据,这样数据不会在项目更新后丢失:
| |
接下来,我们可以通过以下命令来启动 Open WebUI :
| |
如果想要运行支持 Nvidia GPU 的 Open WebUI ,可以使用以下命令:
| |
这里我们将 Open WebUI 的服务暴露在机器的 3000 端口,可以通过浏览器访问 http://localhost:3000 即可使用(远程访问则使用公网 ip ,开放 3000 端口)。/DATA/open-webui 是数据存储目录,你可以根据需要调整这个路径。
当然除了 Docker 安装方式外,你也可以通过 pip 、源码编译、Podman 等方式安装 Open WebUI 。更多安装方式请参考 Open WebUI 官方文档 。
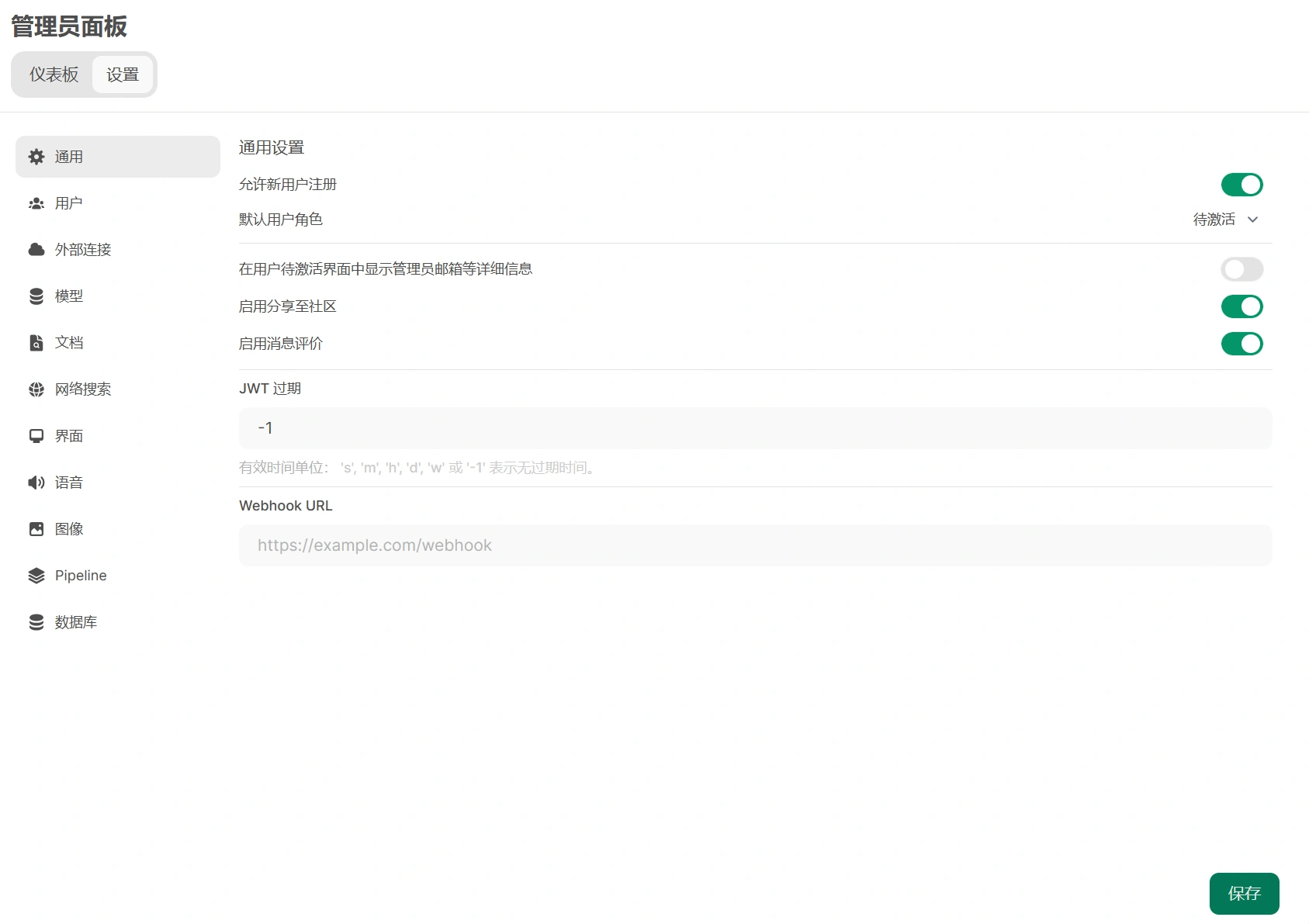
# 基础设置
- 输入要注册的账号信息,设置强密码!!!
重要
第一个注册的用户将被自动设置为系统管理员,所以请确保你是第一个注册的用户。
- 点击左下角头像,选择管理员面板
- 点击面板中的设置
- 关闭允许新用户注册(可选)
- 点击右下角保存
# 配置 Ollama 和 Qwen2.5
# 部署 Ollama
在本地服务器上安装 Ollama。目前 Ollama 提供多种安装方式,请参考 Ollama 的官方文档
下载安装最新的 0.3.11 版本(Qwen2.5 在该版本才开始支持)。安装细节可以参考我之前写的一篇文章:Ollama:从入门到进阶
。
启动 Ollama 服务(如果是 Docker 方式启动则不需要,但必须暴露 11434 端口):
| |
Ollama 服务启动后,可以通过访问地址 http://localhost:11434 连接到 Ollama 服务。
Ollama Library
提供了语义向量模型 ( bge-m3 ) 以及各大文本生成模型(包括 Qwen2.5)。下一步我们将配置 Ollama 以适应本项目对文档检索和问答生成的需求。
# 下载 Qwen2.5 模型
通过 Ollama 安装 Qwen2.5,你可以直接在命令行中运行 ollama pull 命令来下载 Qwen2.5 模型,比如要下载 Qwen2.5 的 72B 模型,可以使用以下命令:
| |
该命令将从 Ollama 的模型仓库抓取 Qwen2.5 模型,并准备运行环境。
Qwen2.5 提供了多种模型尺寸,包括 72B、32B、14B、7B、3B、1.5B、0.5B 等,你可以根据自己的需求和 GPU 显存大小选择合适的模型。我采用的是 4x V100 的服务器,所以可以直接选择 72B 模型。如果要求吐字速度快且能接收微小的性能损失的话,可以使用 q4_0 量化版本 qwen2.5:72b-instruct-q4_0 ;如果能接受吐字速度慢一些,可以使用 qwen2.5:72b-instruct-q5_K_M 。对于 4x V100 的服务器,虽然 q5_K_M 模型的 token 生成明显卡顿,但是为了试验一下 Qwen2.5 的性能,我还是选择了 q5_K_M 模型。
对于显存较少的个人电脑,推荐使用 14B 或 7B 模型,通过以下命令下载:
| |
或者
| |
如果你同时启动好了 Open WebUI 和 Ollama 服务,那么也可以在管理员面板中下载模型。
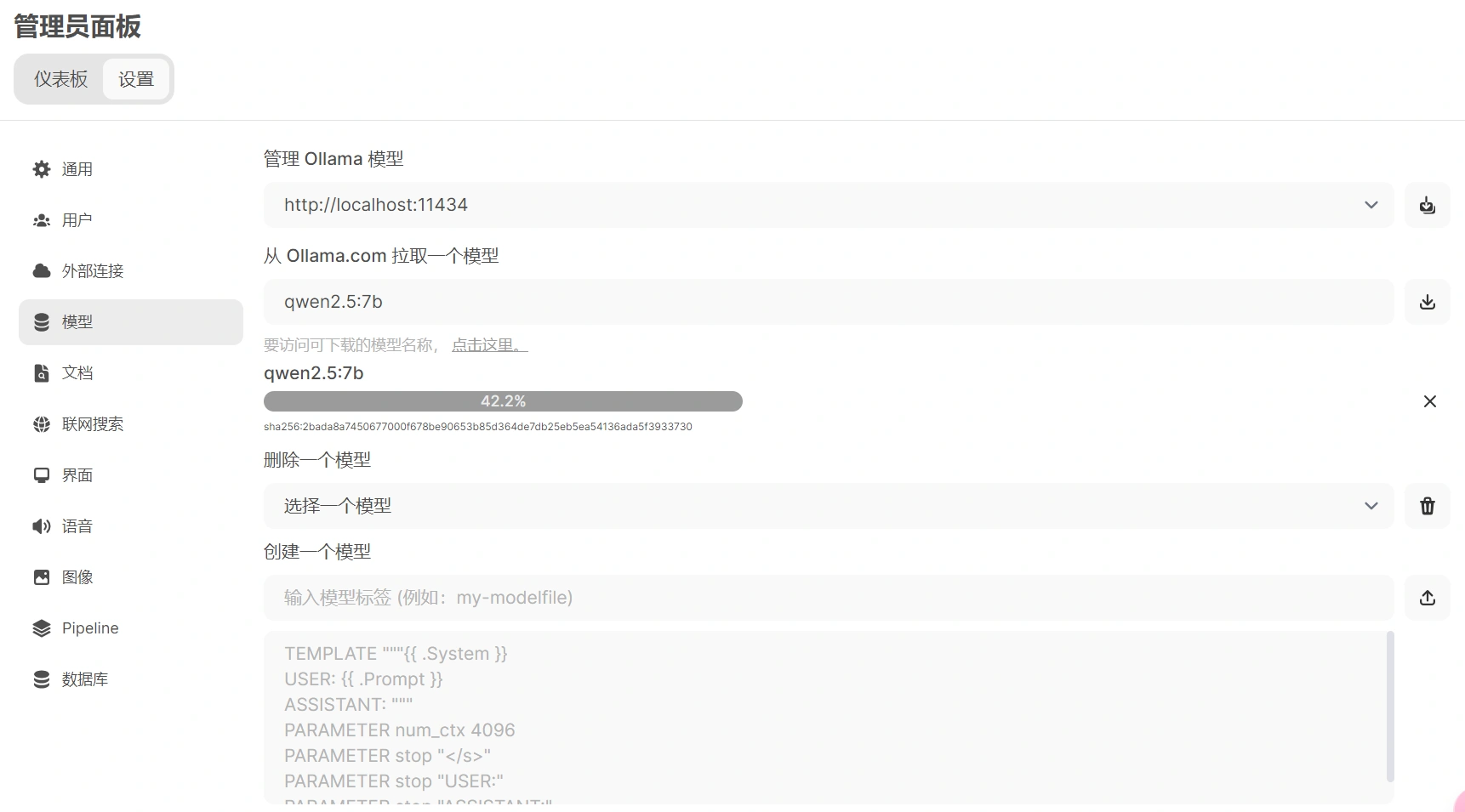
# 下载 bge-m3 模型
在 Ollama 中下载 bge-m3 模型,该模型用于文档向量化处理。在命令行中运行以下命令下载模型(或者在 Open WebUI 界面下载):
| |
到这里,我们已经完成了 Ollama 的配置,接下来我们将在 Open WebUI 中配置 RAG 服务。
# RAG 集成与配置
# 在 Open WebUI 中配置 Ollama 的 RAG 接口
# 访问 Open WebUI 管理界面
启动 Open WebUI 之后,你可以直接通过 Web 浏览器访问服务地址,登录你的管理员账户,然后进入管理员面板。
# 设置 Ollama 接口
在 Open WebUI 的管理员面板中,点击设置,你会看到外部连接的选项,确保 Ollama API 的地址为 host.docker.internal:11434 ,然后点击右边的 verify connection 按钮确认 Ollama 服务是否正常连接。

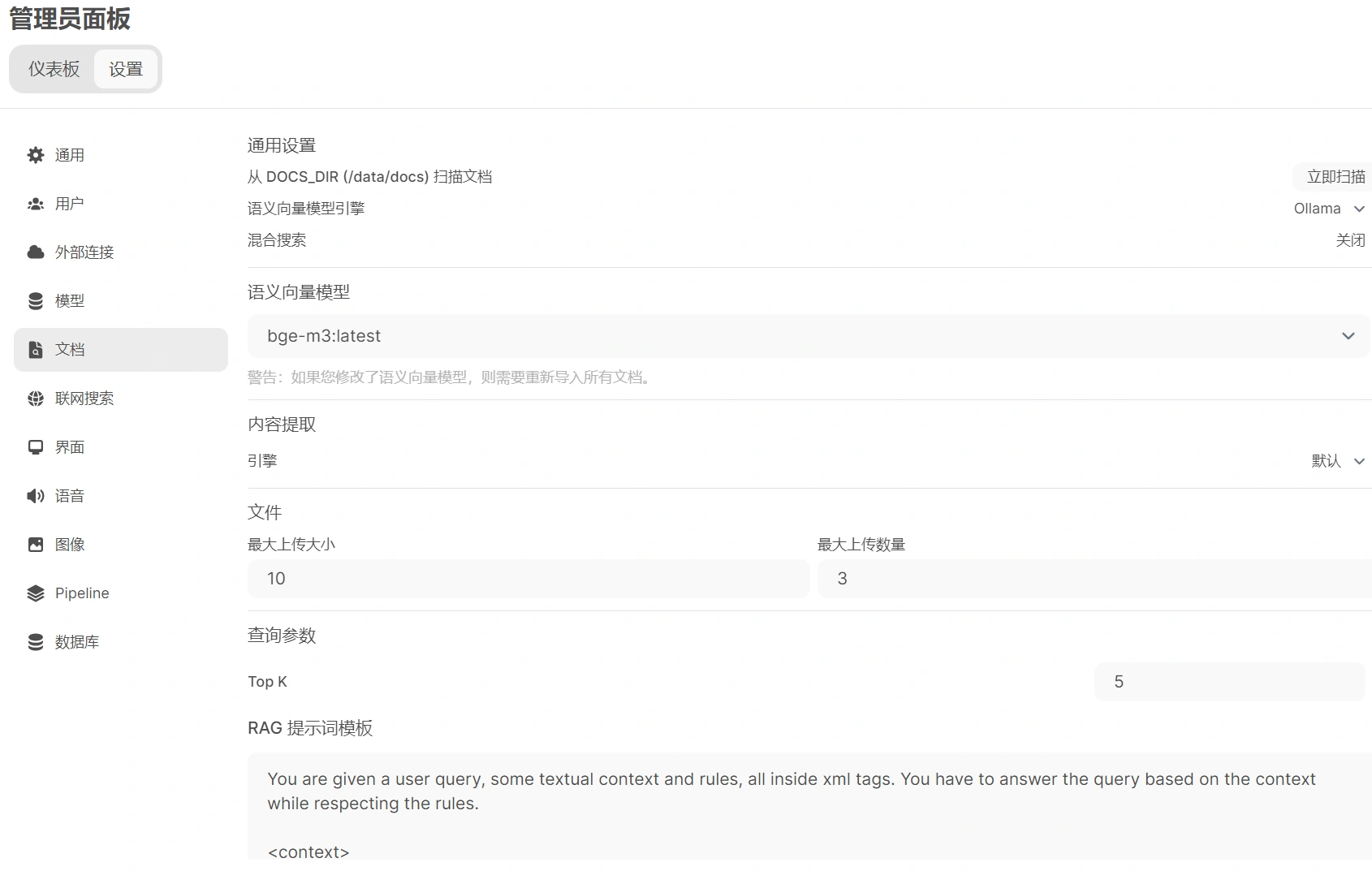
# 设置语义向量模型
在 Open WebUI 的管理员面板中,点击设置,接着点击文档,依次完成以下步骤:
- 设置语义向量模型引擎为 Ollama 。
- 设置语义向量模型为
bge-m3:latest。 - 其余设置可以保持默认,这里我设置了文件最大上传大小为 10MB,最大上传数量为 3,Top K 设置为 5,块大小和块重叠分别设置为 1500 和 100 ,并开启 PDF 图像处理。
- 点击右下角保存。
# 测试 RAG 服务
现在,你已经实现了完整的本地 RAG 系统。你可以在 Open WebUI 的主界面中输入任意自然语言问题,然后上传响应文档,系统会调用语义向量模型向量化文档,再使用 Qwen2.5 模型检索文档生成答案并返回给用户。
在 Open WebUI 的用户聊天界面,上传你要检索的文档,然后输入你的问题,点击发送,Open WebUI 将会调用 Ollama 的 bge-m3 模型进行文档向量化处理,然后调用 Qwen2.5 模型进行问答生成。
这里我上传了一个简单的 txt 文件(由 GPT 生成的文本),内容如下:
| |
然后分别提了三个问题:
- 艾文在森林中遇到的奇异生物是什么?
- 艾文在洞穴中找到的古老石板上刻的是什么?
- 艾文在祭坛中心发现了什么宝藏?
下图是回答结果:

# 总结
借助 Open WebUI 和 Ollama,我们可以轻松搭建一个高效、直观的本地 RAG 系统。通过将 bge-m3 语义向量模型用于文本向量化,再结合 Qwen2.5 生成模型,用户可以在一个统一的 Web 界面中进行文档检索与增强生成任务的高效互动。不但保护了数据隐私,还大幅提升了生成式 AI 的本地化应用能力。