# 关于 Hadoop3 HA 模式
# 单点故障(SPOF)
简单来说,单点故障指的是分布式系统过度依赖于某一个节点,以至于只要该节点宕掉,就算整个集群的其它节点是完好的,集群也无法正常工作。而单点故障问题一般出现在集群的元数据存储节点上,这种节点一般一个集群就一个,一旦坏了整个系统就不能正常使用。Hadoop 的单点故障出现在 namenode 上,影响集群不可用主要有以下两种情况:一是 namenode 节点宕机,将导致集群不可用,重启 namenode 之后才可使用;二是计划内的 namenode 节点软件或硬件升级,导致集群短时间内不可用。
为了避免出现单点故障,Hadoop 官方给出了高可用 HA 方案:可以采取同时启动两个 namenode:其中一个工作(active),另一个总是处于后备机(standby)的状态,让它只是单纯地同步活跃机的数据,当活跃机宕掉的时候就可以自动切换过去。这种模式称为HA 模式。HA 模式下不能用[namenode 主机:端口]的模式来访问 Hadoop 集群,因为 namenode 主机已经不再是一个固定的 IP 了,而是采用 serviceid 的方式来访问,这个 serviceid 存储在 ZooKeeper 上。
# Zookeeper
Zookeeper 是一个轻量级的分布式架构集群,为分布式应用提供一致性服务,提供的功能包括:配置维护、域名服务、分布式同步和组服务等。在 HA 模式中,Zookeeper 最大的功能之一是知道某个节点是否宕机了。其原理是:每一个机器在 Zookeeper 中都有一个会话,如果某个机器宕机了,这个会话就会过期,Zookeeper 就能发现该节点已宕机。
# 实验过程和结果
# 环境
本实验使用 Ubuntu 18.04 64 位作为系统环境,采用 3 台 2 核 16GB( MA3.MEDIUM16 型号)的腾讯云服务器作为集群部署机器。
使用的软件如下:
| 名称 | 版本 |
|---|---|
| Hadoop | 3.2.3 |
| Zookeeper | 3.6.3 |
| JDK | 11.0.2 |
提示
建议:在以下的部署过程中使用 root 用户可以避免很多权限问题。
# 集群规划
| 主机名 | IP | Namenode | Datanode | Zookeeper | JournalNode |
|---|---|---|---|---|---|
| master | 172.31.0.12 | 是 | 是 | 是 | 是 |
| slave1 | 172.31.0.16 | 是 | 是 | 是 | 是 |
| slave2 | 172.31.0.10 | 否 | 是 | 是 | 是 |
# 创建 hadoop 用户
在终端输出如下命令创建一个名为 hadoop 的用户。
| |
接着使用如下命令设置密码,按提示输入两次密码,这里简单设置为 hadoop
| |
此外,可以为 hadoop 用户添加管理员权限,方便后续的部署,避免一些权限问题的出现。
| |
# 主机名和网络映射配置
为了便于区分 master 节点和 slave 节点,可以修改各个节点的主机名。在 Ubuntu 系统中,我们可以执行以下命令来修改主机名。
| |
执行上面命令后,就打开了/etc/hostname 这个文件,这个文件记录了主机名。打开这个文件之后,里面只有当前的主机名这一行内容,可以直接删除,并修改为 master 或 slave1、slave2,然后保存退出 vim 编辑器,这样就完成了主机名的修改,需要重启系统后才能看到主机名的变化。
然后,在 master 节点中执行如下命令打开并修改 master 节点的/etc/hosts 文件
| |
在 hosts 文件中增加如下三条 IP(局域网 IP)和主机名映射关系。
| |
需要注意的是,一般 hosts 文件中只能有一个 127.0.0.1,其对应主机名为 localhost,如果有多余 127.0.0.1 映射,应删除,特别是不能存在“127.0.0.1 Master”这样的映射记录。修改后需要重启 Linux 系统。
上面完成了 master 节点的配置,接下来要继续完成对其他 slave 节点的配置修改。请参照上面的方法,把 slave1 节点上的“/etc/hostname”文件中的主机名修改为“slave1”,把 slave1 节点上的“/etc/hostname”文件中的主机名修改为“slave2”同时,修改“/etc/hosts”的内容,在 hosts 文件中增加如下三条 IP 和主机名映射关系:
| |
修改完成以后,重新启动 slave 节点的 Linux 系统。
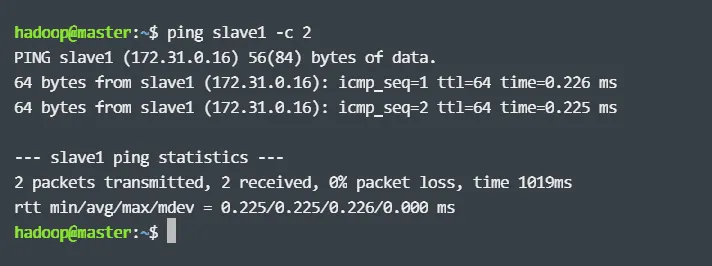
这样就完成了 master 节点和 slave 节点的配置,然后,需要在各个节点上都执行如下命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功:
| |
例如,在 master 节点上 ping slave1,如果 ping 通的话,会显示如下图所示的结果:
# 安装 SSH 并配置 SSH 免密登录
集群模式需要用到 SSH 登陆,Ubuntu 默认已经安装 SSH client,此外还需要安装 SSH server
| |
安装后,可以使用如下命令登陆本机
| |
在集群模式中,必须要让 master 节点可以 SSH 免密登录到各个 slave 节点上。首先,生成 master 节点的公钥,如果之前已经生成过公钥,必须要删除原来生成的公钥,重新生成一次。具体命令如下:
| |
为了让 master 节点能够 SSH 免密登录本机,需要在 master 节点上执行如下命令:
| |
完成后可以执行“ssh master”来验证一下,可能会遇到提示信息,输入 yes 即可,测试成功后执行 exit 命令返回原来的终端。
接下来,在 master 节点上将公钥传输到 slave1 和 slave2 节点
| |
接着在 slave1(slave2)节点上将 SSH 公钥加入授权
| |
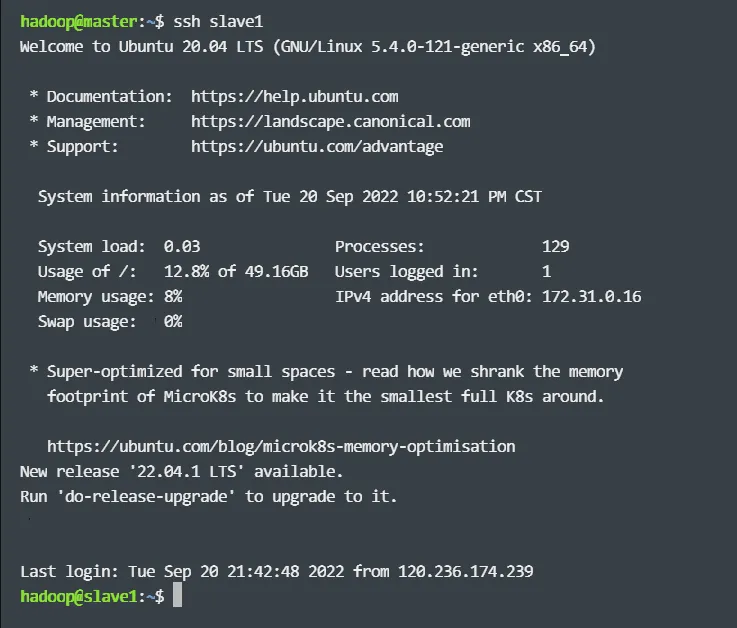
这样,master 节点就可以免密登录到各个 slave 节点上了,例如执行如下命令:
| |
会显示如下结果,显示已经登录到 slave1 节点上。
# 安装 Java 环境
Hadoop3 需要 JDK 版本在 1.8 以上,这里我选择 11 版本 JDK 作为 Java 环境,先执行以下命令下载压缩包。
| |
然后,使用如下命令解压缩:
| |
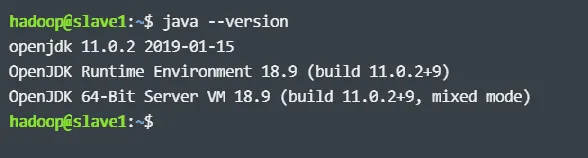
这时,可以执行以下命令查看是否安装成功
| |
如果返回如下信息,则说明安装成功:
# 安装 hadoop3
先执行以下命令下载压缩包。
| |
然后,使用如下命令解压缩:
| |
这时,可以执行以下命令查看是否安装成功
| |
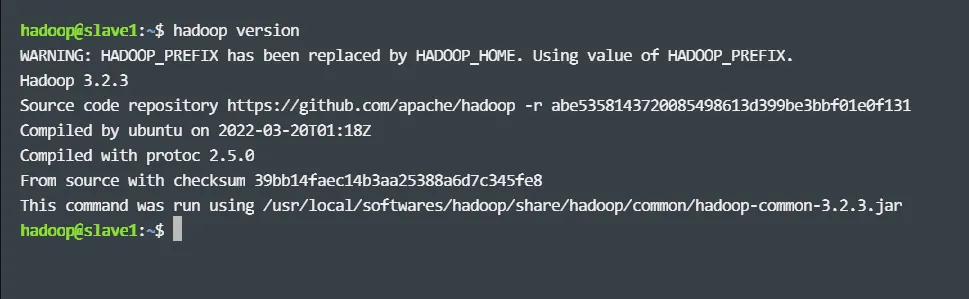
如果返回如下信息,则说明安装成功:
# 安装 Zookeeper
先执行以下命令下载压缩包。
| |
然后,使用如下命令解压缩:
| |
接下来,将 Zookeeper 中的 conf 文件夹里的 zoo_sample.cfg 文件复制一份,改名为 zoo.cfg,然后编辑这个文件,其他的部分不用动,需要修改 dataDir 这一行。dataDir 是 ZooKeeper 的数据文件夹的位置,在我的机器上我用的是/data/zookeeper,你们可以设置成你们的目录。此外,需要在末尾加上所有节点的信息(数字与 myid 要对应):
| |
然后再修改 bin/zkEnv.sh,添加以下日志输出文件夹配置:
| |
最后,需要在每一个节点上的 dataDir 目录下手动创建一个文件,命名为 myid,并写入这台服务器的 Zookeeper ID。这个 ID 数字可以自己随便写,取值范围是 1~255,在这里我将 master、slave1 和 slave2 分别取值为 1,2,3。配置完成以上全部后,分别使用 zkServer.sh start 命令启动集群,ZooKeeper 会自动根据配置把所有的节点连接成一个集群。启动后使用 jps 命令可以查看到 QuorumPeerMain 进程已经启动成功。
# 配置环境变量
配置环境变量后可以在任意目录中直接使用 hadoop、hdfs 等命令。配置方法也比较简单。首先执行命令:
| |
然后,在该文件最上面的位置加入下面内容:
| |
保存后执行如下命令使配置生效:
| |
# 配置 HA 模式集群分布式环境
# 修改文件 workers
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),在本实验中,master 和 slave1、slave2 都充当 datanode,所以该文件内容配置如下:
| |
# 修改文件 core-site.xml
在一般集群模式中,fs.defaultFS 配置为 hdfs://master:9000,即名称节点所在的主机名加上端口号,但需要注意的是,在 HA 模式下分别有一个 active 和 standby 的名称节点,需要将该属性设置为集群 id,这里写的 ha-cluster 需要与 hdfs-site.xml 中的配置一致,所以将该文件修改为如下内容:
| |
# 修改文件 hdfs-site.xml
对以下属性进行配置:
| |
# 修改文件 hadoop-env.sh
在文件开头添加以下变量
| |
# 在所有节点上创建数据文件夹和日志文件夹
| |
# 在所有节点上分别启动 journalnode
| |
# 格式化 namenode 节点
在第一个 namenode 上进行格式化并启动 hdfs:
1 2hdfs namenode -format; hdfs --daemon start namenode在第二个 namenode 上进行备用初始化
1hdfs namenode -bootstrapStandby在第一个 namenode 上进行 journalnode 的初始化
1hdfs namenode -initializeSharedEdits
# 分别在 namenode 节点上启动 zkfc
| |
# 在主节点上启动所有 datanode 节点
| |
# 实验结果
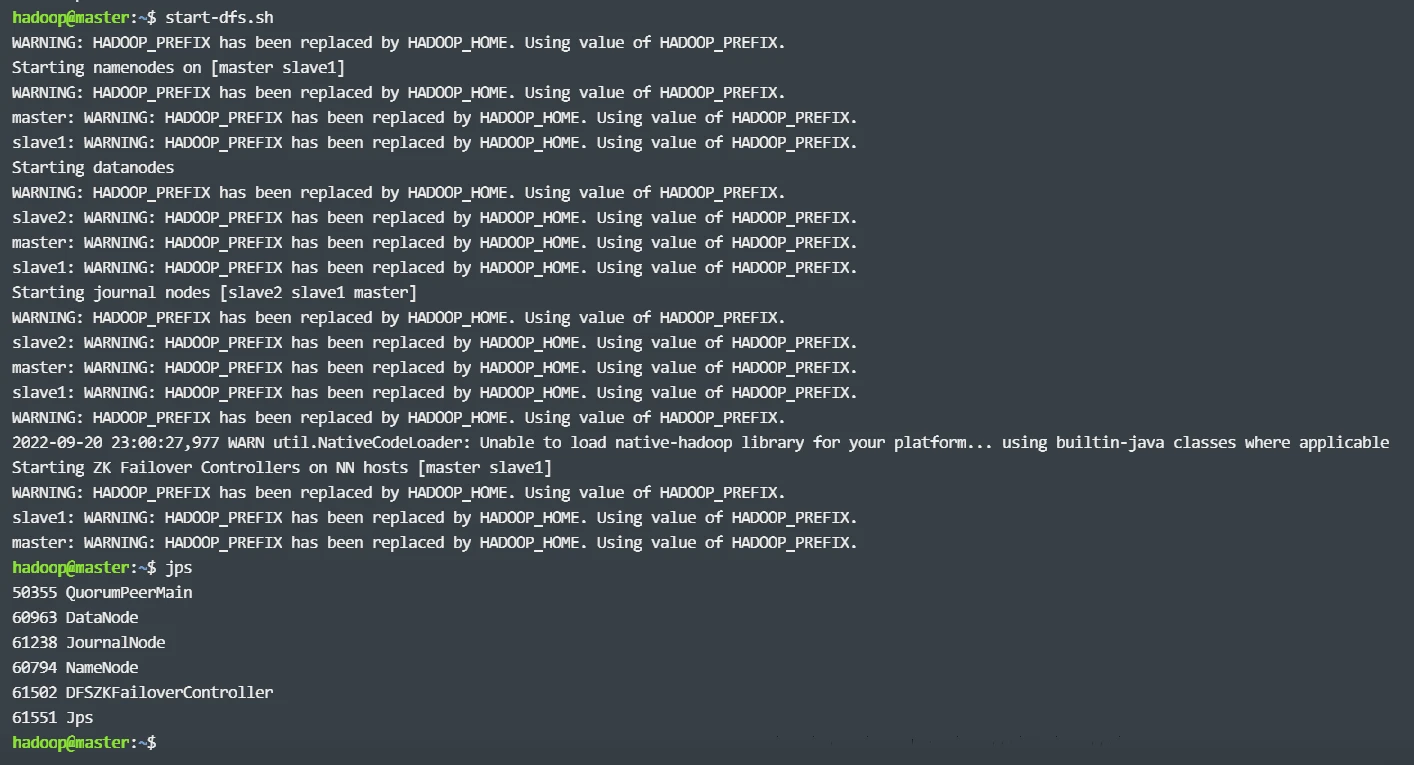
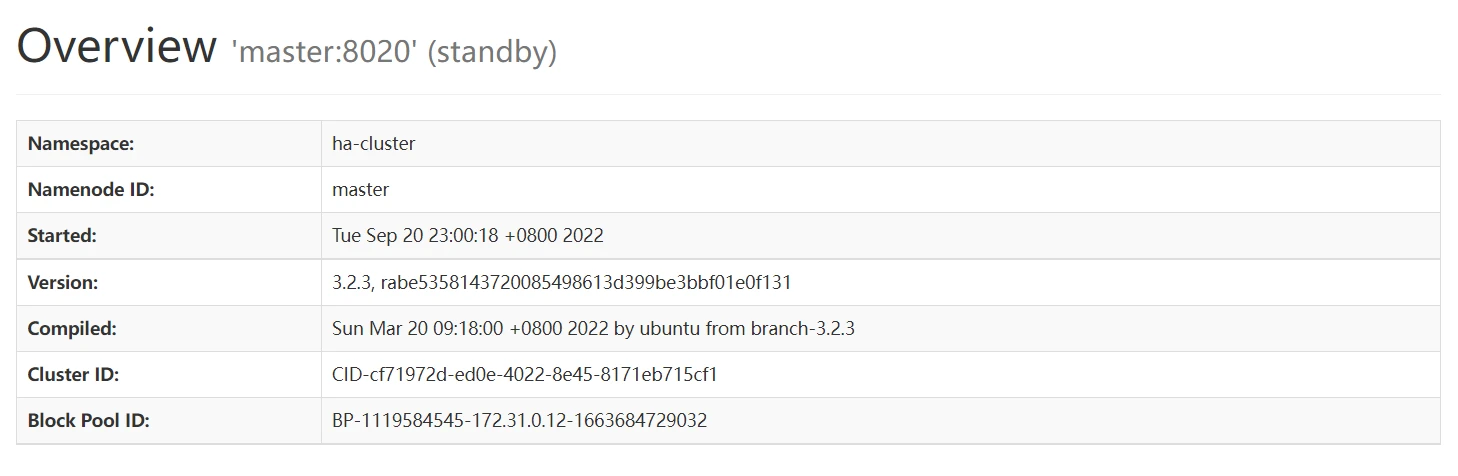
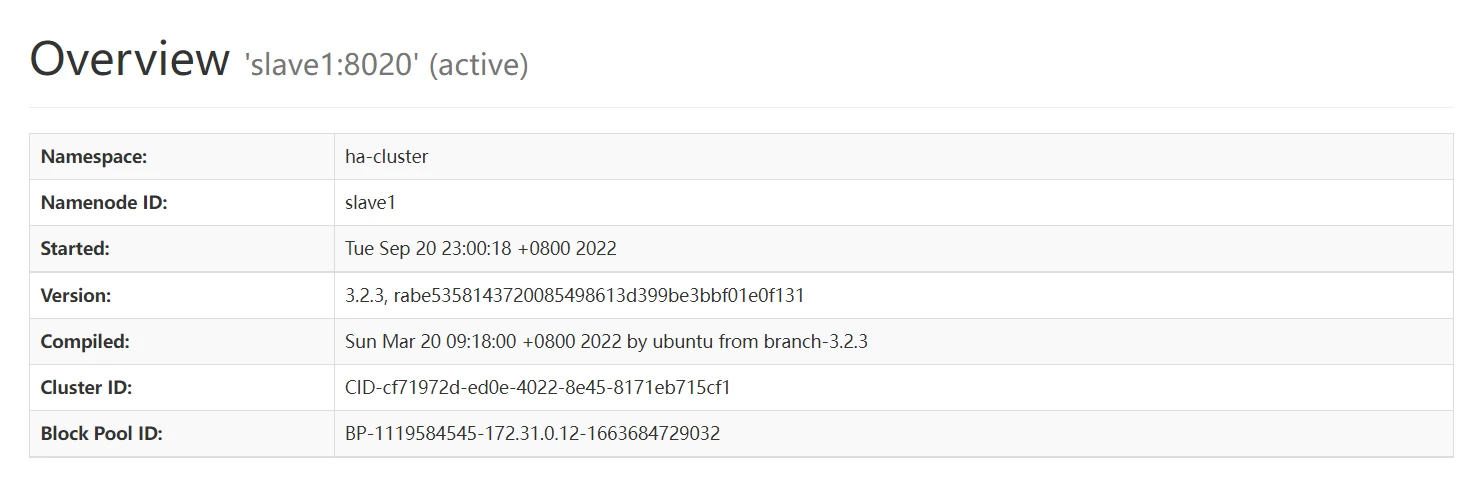
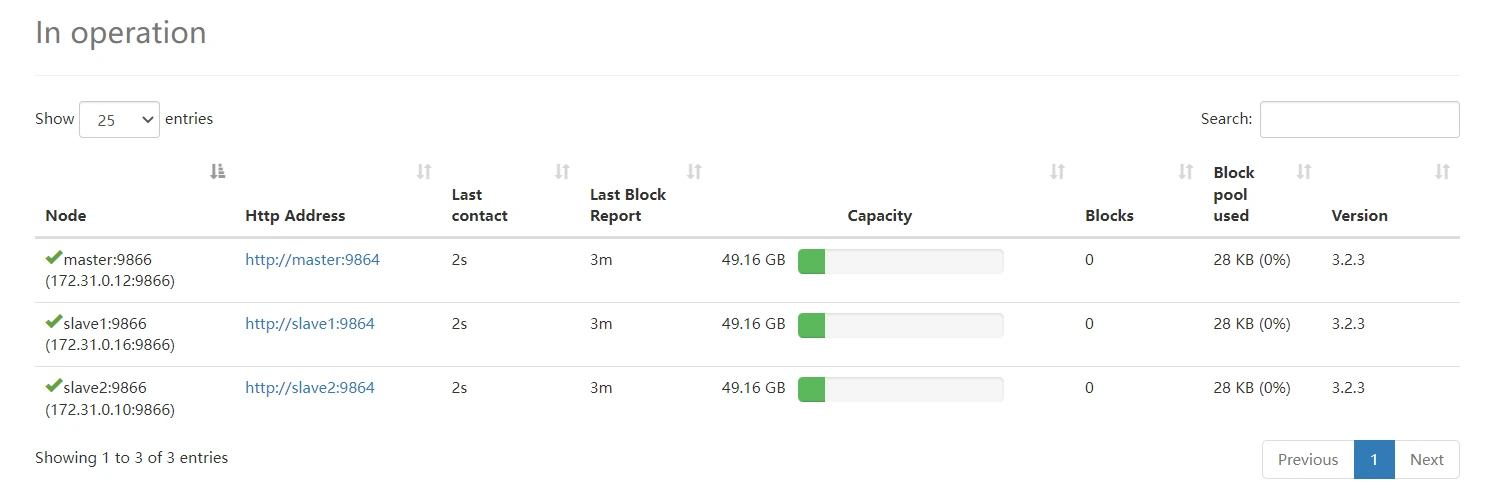
# 实例运行
首先创建 HDFS 上的用户目录,命令如下:
| |
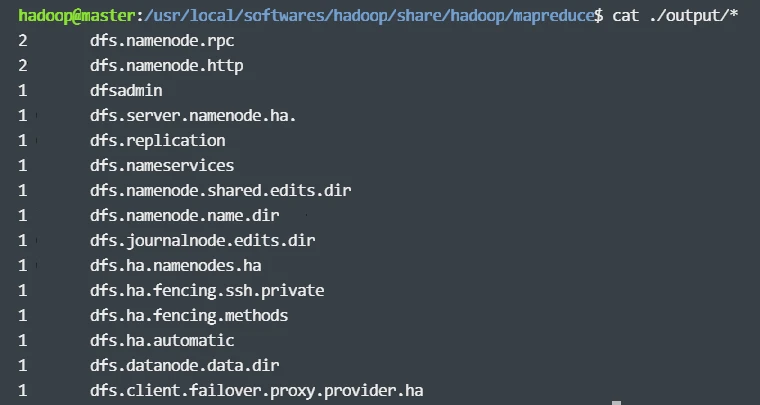
然后,在 HDFS 中创建一个 input 目录,并将“/usr/local/softwares/hadoop/etc/hadoop”目录中的配置文件作为输入文件复制到 input 目录中,命令如下:
| |
接着就可以运行 MapReduce 作业了,命令如下:
| |
运行结果如下:
# 补充:可选配置
# HDFS Web UI 配置认证
HDFS 带有一个可视化的端口号默认为 9870 的 Web UI 界面,这个界面如果没有做防火墙限制的话会暴露在公网上。而该界面又存在着大量的日志和配置信息,直接暴露在公网上不利于系统的安全,所以在这里可以配置一个简单的系统认证功能。步骤如下:
安装 httpd 或安装 httpd-tools
1sudo apt-get install httpd安装 nginx:这部分内容较多,不是重点,网上有大量的教程,跟着其中一个进行就行。
通过 htpasswd 命令生成用户名和密码数据库文件
1htpasswd -c passwd.db [username]查看生成的 db 文件内容
1cat passwd.db通过 nginx 代理并设置访问身份验证
1 2# nginx 配置文件 vim nginx.conf1 2 3 4 5 6 7 8 9 10 11server { # 使用 9871 端口替代原有的 9870 端口 listen 9871; server_name localhost; location / { auth_basic "hadoop authentication"; auth_basic_user_file /home/hadoop/hadoop/passwd.db proxy_pass http://127.0.0.1:9870 } }重新加载 nginx 配置
1 2cd /usr/local/lighthouse/softwares/nginx/sbin ./nginx -s reload启动 nginx
1systemctl start nginx到此为止,HDFS Web UI 界面认证设置完成,效果如下:.