
# 一、前言
在多核并发编程中,如果将互斥锁的争用比作 性能杀手 的话,那么伪共享则相当于 性能刺客。杀手 与 刺客 的区别在于杀手是可见的,遇到杀手时我们可以选择战斗、逃跑、绕路、求饶等多种手段去应付,但 刺客 却不同, 刺客 永远隐藏在暗处,伺机给你致命一击,防不胜防。具体到我们的并发编程中,遇到锁争用影响并发性能情况时,我们可以采取多种措施(如缩短临界区,原子操作等等)去提高程序性能,但是伪共享却是我们从所写代码中看不出任何蛛丝马迹的,发现不了问题也就无法解决问题,从而导致伪共享在暗处严重拖累程序的并发性能,但我们却束手无策。
# 二、缓存行
为了进行下面的讨论,我们需要首先熟悉缓存行的概念,学过操作系统课程存储结构这部分内容的同学应该对存储器层次结构的金字塔模型印象深刻,金字塔从上往下代表存储介质的成本降低、容量变大,从下往上则代表存取速度的提高。位于金字塔模型最上层的是 CPU 中的寄存器,其次是 CPU 缓存(L1,L2,L3),再往下是内存,最底层是磁盘,操作系统采用这种存储层次模型主要是为了解决 CPU 的高速与内存磁盘低速之间的矛盾,CPU 将最近使用的数据预先读取到 Cache 中,下次再访问同样数据的时候,可以直接从速度比较快的 CPU 缓存中读取,避免从内存或磁盘读取拖慢整体速度。
CPU 缓存的最小单位就是缓存行,缓存行大小依据架构不同有不同大小,最常见的有 64Byte 和 32Byte ,CPU 缓存从内存取数据时以缓存行为单位进行,每一次都取需要读取数据所在的整个缓存行,即使相邻的数据没有被用到也会被缓存到 CPU 缓存中。
# 三、缓存一致性
在单核 CPU 情况下,上述方法可以正常工作,可以确保缓存到 CPU 缓存中的数据永远是 干净 的,因为不会有其他 CPU 去更改内存中的数据,但是在多核 CPU 下,情况就变得更加复杂一些。多 CPU 中,每个 CPU 都有自己的私有缓存(可能共享 L3 缓存),当一个 CPU1 对 Cache 中缓存数据进行操作时,如果 CPU2 在此之前更改了该数据,则 CPU1 中的数据就不再是 干净 的,即应该是失效数据,缓存一致性就是为了保证多 CPU 之间的缓存一致。
Linux 系统中采用 MESI 协议处理缓存一致性,所谓 MESI 即是指 CPU 缓存的四种状态:
- M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有);
- E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
- S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝;
- I(无效,Invalid):缓存行失效, 不能使用。
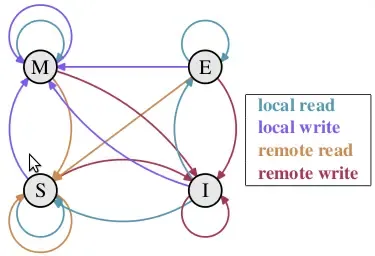
每个 CPU 缓存行都在四个状态之间互相转换,以此决定 CPU 缓存是否失效,比如 CPU1 对一个缓存行执行了写入操作,则此操作会导致其他 CPU 的该缓存行进入 Invalid 无效状态, CPU 需要使用该缓存行的时候需要从内存中重新读取。由此就解决了多 CPU 之间的缓存一致性问题。
# 四、伪共享
何谓伪共享?上面我们提过 CPU 的缓存是 以缓存行为单位 进行的,即除了本身所需读写的数据之外还会缓存与该数据在同一缓存行的数据,假设缓存行大小是 32 字节,内存中有 abcdefgh 八个 int 型数据,当 CPU 读取 d 这个数据时, CPU 会将 abcdefgh 八个 int 数据组成一个缓存行加入到 CPU 缓存中。假设计算机有两个 CPU:CPU1 和 CPU2 , CPU1 只对 a 这个数据进行频繁读写, CPU2 只对 b 这个数据进行频繁读写,按理说这两个 CPU 读写数据没有任何关联,也就不会产生任何竞争,不会有性能问题,但是由于 CPU 缓存是以缓存行为单位进行存取的,也是以缓存行为单位失效的,即使 CPU1 只更改了缓存行中 a 数据,也会导致 CPU2 中该缓存行完全失效,同理,CPU2 对 b 的改动也会导致 CPU1 中该缓存行失效,由此引发了该缓存行在两个 CPU 之间 乒乓 ,缓存行频繁失效,最终导致程序性能下降,这就是伪共享。
下面是维基百科的定义:
In computer science, false sharing is a performance-degrading usage pattern that can arise in systems with distributed, coherent caches at the size of the smallest resource block managed by the caching mechanism. When a system participant attempts to periodically access data that is not being altered by another party, but that data shares a cache block with data that is being altered, the caching protocol may force the first participant to reload the whole cache block despite a lack of logical necessity. The caching system is unaware of activity within this block and forces the first participant to bear the caching system overhead required by true shared access of a resource.
在计算机科学中,伪共享是一种性能降低的使用模式,可能出现在具有分布式、一致性缓存的系统中,缓存大小为缓存机制管理的最小资源块。当一个系统参与者试图定期访问未被其他方修改的数据,但该数据与正在被修改的数据共享一个缓存块时,缓存协议可能会强制第一个参与者重新加载整个缓存块,尽管在逻辑上没有必要。 缓存系统无法感知这个块内的活动,并强制第一个参与者承担由真正共享资源访问所需的缓存系统开销。
# 五、如何避免伪共享
避免伪共享主要有以下两种方式:
- 缓存行填充(Padding):为了避免伪共享就需要将可能造成伪共享的多个变量处于不同的缓存行中,可以采用在变量后面填充字节的方式达到该目的。
- 使用某些语言或编译器中强制变量对齐,将变量都对齐到缓存行大小,避免伪共享发生。
# 六、获取缓存行大小
在 C++11 中,可以使用 std::hardware_destructive_interference_size 和 std::hardware_constructive_interference_size 获取缓存行大小,前者获取的是缓存行大小,后者获取的是缓存行大小的两倍,即 2 * std::hardware_destructive_interference_size。
在 C 语言中,可以读取 coherency_line_size 文件获取缓存行大小,该文件位于 /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size ,该文件中存储的是缓存行大小的字节数,可以使用 cat 命令查看。也可以通过 long cache_line_size = sysconf(_SC_LEVEL1_DCACHE_LINESIZE) 的方式获取。
# 七、通过对齐解决伪共享
C 语言中可以使用 posix_memalign 函数来实现对齐,该函数的声明如下:
| |
# 总结
一般伪共享都很隐蔽,很难被发现,当伪共享真正构成性能瓶颈的时候,我们有必要去努力找到并解决它,但是在大部分对性能追求没有那么高的应用中,伪共享的存在对程序的危害很小,有时并不值得耗费精力和额外的内存空间(缓存行填充)去查找系统存在的伪共享。还是那句我们一直以来应该遵循的原则 “不要过度优化,不要提前优化。” 。