
本文欢迎非商业转载,转载请注明出处。
声明:仅用于收藏,便于阅读
― Savir, 知乎专栏:2. 比较基于传统以太网与 RDMA 技术的通信
本篇的目的是通过对比一次典型的基于 TCP/IP 协议栈的以太网和 RDMA 通信的过程,直观的展示 RDMA 技术相比传统以太网的优势,尽量不涉及协议和软件实现细节。
假设本端的某个应用想把自己内存中的数据复制到对端某个应用可以访问的内存中(或者通俗的讲,本端要给对端发送数据),我们来看一下以太网和 RDMA 的 SEND-RECV 语义都做了哪些操作。
# 传统以太网
在描述通信过程时的软硬件关系时,我们通常将模型划分为用户层 Userspace,内核 Kernel 以及硬件 Hardware。Userspace 和 Kernel 实际上使用的是同一块物理内存,但是处于安全考虑,Linux 将内存划分为用户空间和内核空间。用户层没有权限访问和修改内核空间的内存内容,只能通过系统调用陷入内核态,Linux 的内存管理机制比较复杂,本文不展开讨论。
一次典型的基于传统以太网的通信过程的可以如下图所示进行分层:
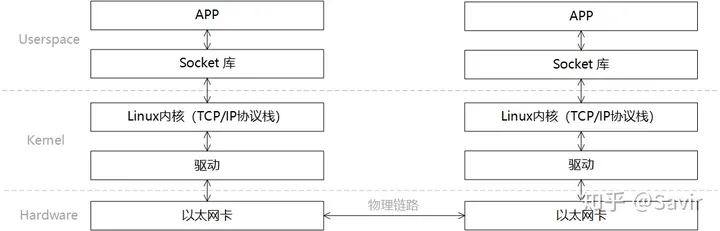
一次收-发过程的步骤如下:
- 发送端和接收端通过 Socket 库提供的接口建立链接(就是在两个节点间建立了一条逻辑上的道路,数据可以沿这条道路从一端发送到另一端)并分别在内存中申请好发送和接收 Buffer。
- 发送端 APP 通过 Socket 接口陷入内核态,待发送数据经过 TCP/IP 协议栈的一层层封装,最后被 CPU 复制到 Socket Buffer 中。
- 发送端通过网卡驱动,告知网卡可以发送数据了,网卡将通过 DMA 从 Buffer 中复制封装好的数据包到内部缓存中,然后将其发送到物理链路。
- 接收端网卡收到数据包后,将数据包放到接收 Buffer 中,然后 CPU 将通过内核中的 TCP/IP 协议栈对报文进行层层解析,取出有效的数据。
- 接收端 APP 通过 Socket 接口陷入内核态,CPU 将数据从内核空间复制到用户空间。
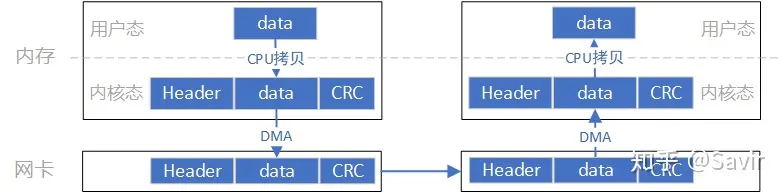
这个模型的数据流向大致是像上图这个样子,数据首先需要从用户空间复制一份到内核空间,这一次复制由 CPU 完成,将数据块从用户空间复制到内核空间的 Socket Buffer 中。内核中软件 TCP/IP 协议栈给数据添加各层头部和校验信息。最后网卡会通过 DMA 从内存中复制数据,并通过物理链路发送给对端的网卡。
而对端是完全相反的过程:硬件将数据包 DMA 拷贝到内存中,然后 CPU 会对数据包进行逐层解析和校验,最后将数据复制到用户空间。
上述过程中的关键点是需要 CPU 参与的把数据从用户空间拷贝到内核空间,以及同样需要 CPU 全程参与的数据包组装和解析,数据量大的情况下,这将对 CPU 将造成很大的负担。
下面我们看一下 RDMA 是如何将 CPU“解放”出来的。
# RDMA
同样是一端发送,一端接收的场景,我们将 RDMA 的分层模型分成两部分“控制通路”和“数据通路”,控制通路需要进入内核态准备通信所需的内存资源,而数据通路指的是实际数据交互过程中的流程。这一过程的分层关系如下图所示:
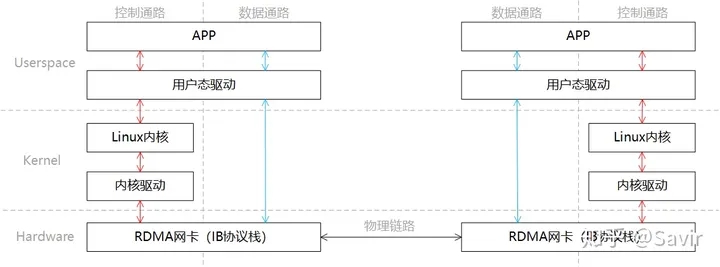
同 Socket 一样,我们简单描述下通信的过程:
- 发送端和接收端分别通过控制通路陷入内核态创建好通信所需要的内存资源。
- 在数据通路上,接收端 APP 通知硬件准备接收数据,告诉硬件将接收到的数据放在哪片内存中。
- 在数据通路上,发送端 APP 通知硬件发送数据,告诉硬件待发送数据位于哪片内存中。
- 发送端 RDMA 网卡从内存中搬移数据,组装报文发送给对端。
- 对端收到报文,对其进行解析并通过 DMA 将有效载荷写入内存。然后以某种方式通知上层 APP,告知其数据已接收并妥善存放到指定位置。
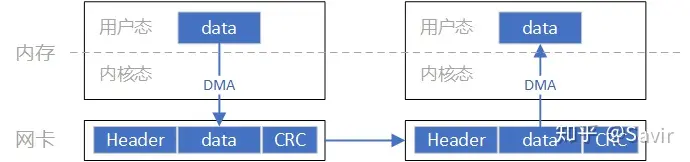
这一过程中的数据流向大致如上图所示。通过和 Socket 的对比,我们可以明显看到,数据收发绕过了内核并且数据交换过程并不需要 CPU 参与,报文的组装和解析是由硬件完成的。
通过上面的对比,我们可以明显的体会到 RDMA 的优势,既将 CPU 从数据包封装和解析中解放出来,又减少了 CPU 拷贝数据的功率和时间损耗。需要注意的是,本文只描述了 SEND-RECV 流程,而 RDMA 技术所独有的,效率更高的 WRITE/READ 语义将在后续文章中介绍。
下一篇我们将介绍一些 RDMA 技术中的重要且基本的概念。