
# 一、 引言
# 1. Linux 原生 aio 接口
在 Linux 中,有很多方法可以进行基于文件的 I/O。最早的和最基本的就是系统调用 read(2)和 write(2)。后来增加了允许传入偏移量的 pread(2)和 pwrite(2),以及基于 vector 的 preadv(2)和 pwrite(2)。再后来,Linux 提供了 preadv2(2)和 pwritev2(2)。它们进一步扩展了 API 以允许修饰符标志。抛开这些系统调用的不同点不谈,它们有一个共同的特点:都是同步接口。这意味着当数据准备好读(或写入)时,系统调用才会返回。对于某些场景,这远远不够,因此还需要异步接口。POSIX 提供了 aio_read(3)和 aio_write(3)来满足这种需求,但是它们的实现通常性能不佳。Linux 原生 aio 接口是 Linux 内核中提供的一种异步 I/O 接口,它使用 io_submit(2)、io_getevents(2)等系统调用来提交和获取 I/O 请求,并使用 struct iocb 来描述每个 I/O 请求。它支持 O_DIRECT(或非缓冲)访问的异步 I/O,并且可以使用信号或回调函数来通知 I/O 完成事件。
然而,Linux 原生 aio 接口存在着许多的限制与不足之处:
- 最大的限制是它只能支持 O_DIRECT(或非缓冲)访问的异步 I/O。由于 O_DIRECT 的限制(缓存绕过和大小/对齐限制),这使得原生 aio 接口在大多数情况下都无法使用。对于普遍的缓冲 I/O,接口会以同步方式运行。
- 即使满足了 I/O 异步的所有约束条件,有时也会出现阻塞。I/O 提交可能会通过多种方式导致阻塞:
- 如果执行 I/O 时需要元数据,提交就会阻塞,等待元数据。
- 对于存储设备,有固定数量的请求槽可用。如果这些插槽目前都在使用中,提交就会阻塞,等待有一个插槽可用。
- I/O 请求元数据开销大:每次 I/O 提交都需要复制 64 + 8 字节的数据,而每次完成则需要复制 32 字节的数据。这意味着对于所谓的零拷贝 I/O 来说,每次操作都需要复制 104 字节的内存。根据 I/O 的大小不同,这种内存复制的开销可能是明显可见的。而且,暴露的完成事件环缓冲区实际上会妨碍完成操作的速度,并且很难(甚至不可能)从应用程序中正确地使用。这可能意味着使用这个 API 进行 I/O 操作时,完成操作的效率会受到影响。此外,在 Spectre/Meltdown 漏洞修复后,I/O 总是需要至少两个系统调用(提交+等待完成),这会导致严重的性能下降。这可能是因为在修复这些漏洞后,系统对于系统调用的处理变得更加复杂和缓慢。
- IOPOLL 支持不好。
随着时间的推移,尽管有一些努力试图解决这些限制,但没有成功。随着具备亚 10 微秒延迟和非常高 IOPS 的设备的出现,这个接口开始显现出其性能缺陷。对于这些类型的设备来说,慢速和非确定性的提交延迟是一个很大的问题,而且单个核心无法提供足够的性能。此外,由于前面提到的限制,可以说原生的 Linux aio 接口用途并不广泛。它被限制在应用程序的一小部分领域中,并且伴随着一些问题。
# 2. io_uring 接口
io_uring 是 Linux 内核中的一种新的异步 I/O 接口,旨在提供高效和可扩展的 I/O 操作。它通过使用一对环形队列(提交队列和完成队列)作为应用程序和内核之间的通信通道,实现了零拷贝的 I/O 操作。
io_uring 的设计目标是在提供高性能的同时解决传统异步 I/O 接口的一些限制和问题。它避免了内存复制和内存方向性,通过共享数据结构和内存来优雅地实现应用程序和内核之间的协调。这种设计使得 io_uring 能够更高效地处理 I/O 请求,并且不需要频繁的系统调用来同步和通信。
通过 io_uring,应用程序可以作为生产者将 I/O 请求提交到提交队列,而内核作为消费者处理这些请求。一旦请求完成,内核会生成相应的完成事件,并将其放入完成队列中,应用程序可以从完成队列中消费这些事件。这种异步的方式使得应用程序能够更好地利用系统资源,提高 I/O 操作的效率和性能。
io_uring 的优势主要在于:
- 使用方便:简单且强大的系统调用,提供三个系统调用,liburing 用户态库编程友好 (io_uring_setup, io_uring_enter, io_uring_register)。
- 通用性强:提供内核统一的异步编程框架,既支持传统 I/O (Buffer I/O + Direct I/O),也支持类 epoll 型编程。
- 特性丰富:支持非常多的高级特性。
- 高性能:I/O 请求 overhead 小。
# 3. liburing 库
liburing 是一个基于 io_uring 接口的用户空间库,它是 Linux 内核开发者 Axboe 于 2019 年发布的一个开源项目。io_uring 是一种新的 Linux 异步 I/O 接口,它通过使用一对环形缓冲区(ring buffer)来实现用户空间和内核空间之间的通信,从而避免了传统异步 I/O 接口(如 AIO)所需的系统调用、信号、回调等机制。这样,用户空间可以直接向内核提交 I/O 请求,并从内核获取 I/O 结果,而无需等待或切换上下文。这大大提高了异步 I/O 操作的效率和性能。
liburing 是对 io_uring 接口的封装和扩展,它提供了一套简洁和灵活的 API,让开发者可以方便地使用 io_uring 的功能,而无需关心底层的细节和复杂性。liburing 主要包括以下几个组件:
- liburing.h:定义了 liburing 库的主要数据结构和函数
- liburing.a:提供了 liburing 库的静态链接版本
- liburing.so:提供了 liburing 库的动态链接版本
- liburing/io_uring.h:定义了 io_uring 接口相关的数据结构和常量
- liburing/compat.h:提供了一些兼容性相关的宏定义
# 二、io_uring 的核心数据结构与原理
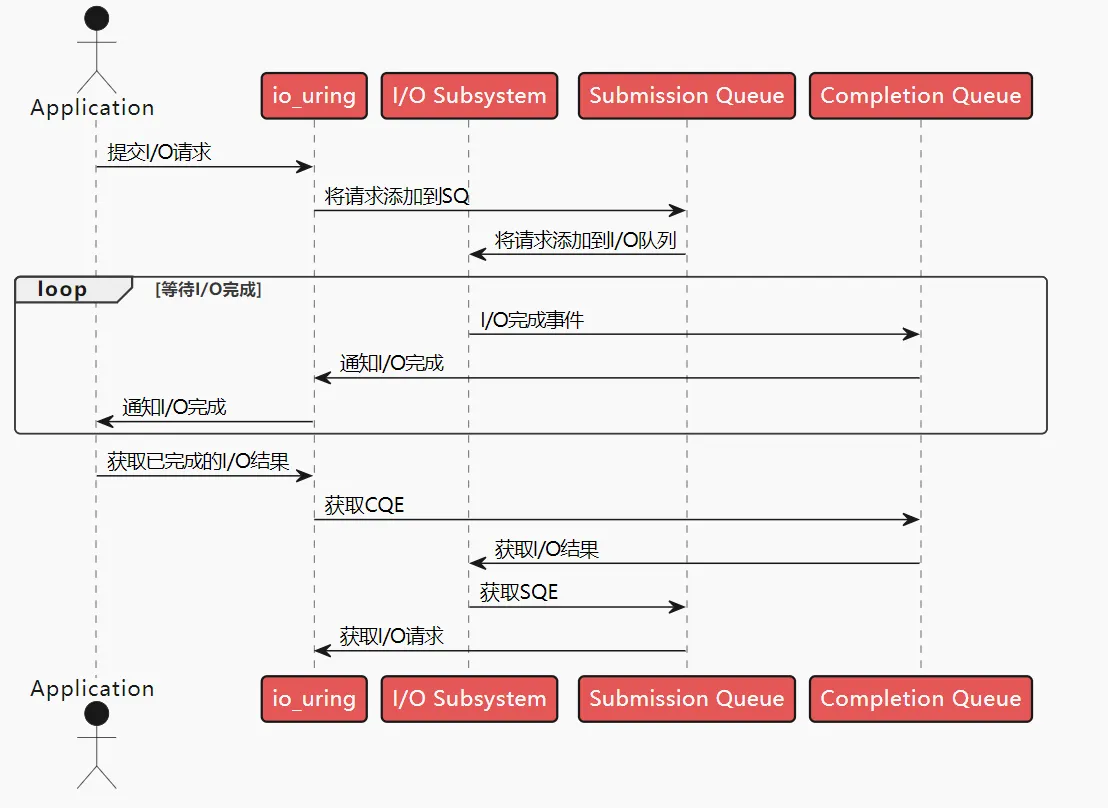
# 1. io_uring 的核心数据结构
- 每个 io_uring 实例都有两个环形队列(称为 ring),在内核和应用程序之间共享:
- 提交队列:submission queue( SQ )
- 完成队列:completion queue( CQ )
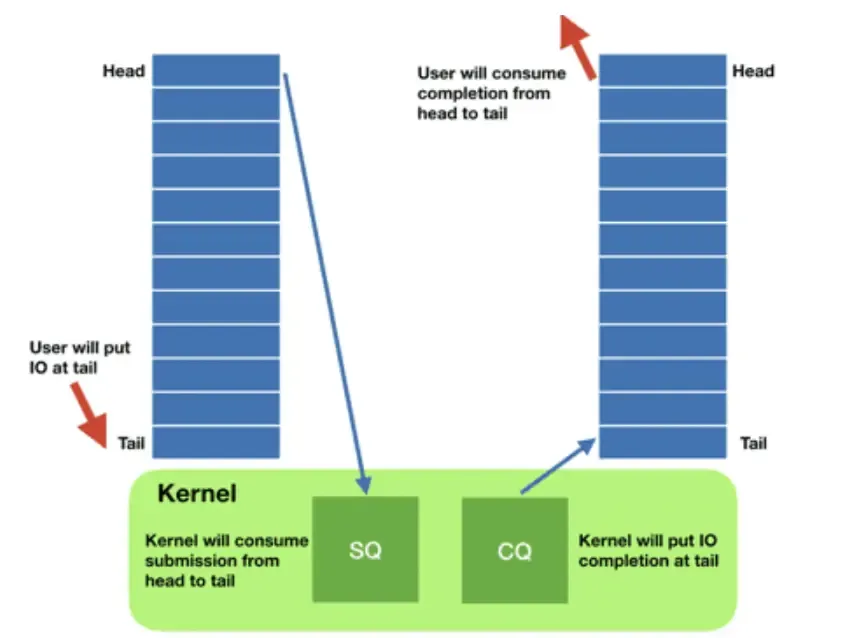
- 这两个队列:
- 都是单生产者、单消费者的队列,size 为 2 的幂次方。
- 提供无锁接口,内部使用内存屏障来进行同步。
- 请求时:
- 应用创建 SQ Entries (SQE),更新 SQ tail
- 内核消费 SQE,更新 SQ head
- 完成后:
- 内核为完成的一个或多个请求创建 CQ Entries (CQE),更新 CQ tail
- 应用消费 CQE,更新 CQ head
- 完成事件可能以任意顺序到达,到总是与特定的 SQE 相关联的
- 消费 CQE 过程无需切换内核态
- 这样做的好处在于:
- 原本需要多次系统调用,现在变成批处理一次提交
- 此外,io_uring 使异步 I/O 的使用场景也不再仅限于数据库应用, 普通的非数据库应用也能用
# 2. io_uring 的三种工作模式:
- 中断驱动模式 (interrupt-driven)
- 默认模式, 可通过 io_uring_enter()提交 I/O 请求,然后直接检查 CQ 状态判断是否完成。
- 轮询模式 (polling)
- Busy waiting for I/O completion,而不是通过异步 IRQ(Interrupt Request)来接收通知
- 这种模式需要文件系统和块设备支持轮询功能。相比中断驱动模式,这种方式延迟更低,但是 CPU 占用率可能会更高。
- 目前,只有指定了 O_DIRECT 标志打开的文件描述符才能使用这种模式。当一个读或写请求提交给轮询上下文之后,应用必须调用 io_uring_enter()来轮询 CQ 队列,判断请求是否完成。
- 对于一个 io_uring 实例来说,不支持混合使用轮询和非轮询模式。
- 内核轮询模式 (kernel polling)
- 这种模式会创建一个内核线程来执行 SQ 的轮询工作。
- 使用这种模式的 io_uring 实例,应用无需切到内核态就能触发 I/O 操作。通过 SQ 来提交 SQE,以及监控 CQ 的完成状态,应用无需任何系统调用,就能提交和收割 I/O。
- 如果内核线程的空闲事件超过了用户的配置值,它会通知应用,然后进入 idle 状态。这种情况下,应用必须调用 io_uring_enter()来唤醒内核线程。如果 I/O 一直很繁忙,内核线程是不会 sleep 的。
# 3. io_uring 的系统调用 API
io_uring 的系统调用 API 有三个,分别是:
- io_uring_setup(2)
- io_uring_register(2)
- io_uring_enter(2)
首先是 io_uring_setup(2):
1int io_uring_setup(unsigned entries, struct io_uring_params *p);- 用于创建一个 io_uring 实例,返回一个文件描述符,用于后续的 io_uring 系统调用。
- 参数:
- entries:SQ 和 CQ 的大小,必须是 2 的幂次方
- params:io_uring 的参数,包括 flags、sq_thread_cpu 等
- 返回值:
- 成功:返回一个文件描述符
- 失败:返回-1,并设置 errno
- 创建一个 SQ 和一个 CQ,它们的大小都是 entries。如果 entries 是 0,那么 SQ 和 CQ 的大小都是默认值(4096)。SQ 和 CQ 在应用和内核之间共享,避免了在初始化和完成 I/O 时拷贝数据
io_uring_register(2):
1int io_uring_register(int fd, unsigned int opcode, const void *arg, unsigned int nr_args);- 注册用于异步 I/O 的文件或用户缓冲区,使内核能长时间持有对该文件在内核内部的数据结构引用,或创建应用内存的长期映射,这个操作只会在注册时执行一次,而不是每个 I/O 操作都会处理,因此减少了 per-I/O 的 overhead 开销。
- 参数:
- fd:文件描述符
- opcode:操作码,用于指定注册的类型,如 IORING_REGISTER_BUFFERS、IORING_REGISTER_FILES 等
- arg:指向一个数组,数组中的每个元素都是一个指向用户缓冲区或文件描述符的指针
- nr_args:arg 数组的大小
- 返回值:
- 成功:返回 0
- 失败:返回-1,并设置 errno
- 注册的缓冲区将会被锁定到内存中,并计入用户的 RLIMIT_MEMLOCK 限制。如果注册的是文件描述符,那么内核会增加对该文件的引用计数,直到应用调用 io_uring_unregister(2)来注销它。
- 每个缓冲区有 1GB 的大小限制。
- 缓冲区必须是匿名的、非文件后端的内存,例如 malloc(3)或带 MAP_ANONYMOUS 标识的 mmap(2)返回的内存。
- Huge pages 也是支持的。整个 Huge page 都会被 pin 到内核,即使只使用其中一部分。
- 已经注册的缓冲区无法调整大小,想调整只能先 unregister,再重新注册。
io_uring_enter(2):
1int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);- 这个系统调用用于初始化和完成(initiate and complete)I/O,使用共享的 SQ 和 CQ。单次调用同时执行:
- 提交新的 I/O 请求
- 等待 I/O 完成
- 参数:
- fd:io_uring 实例的文件描述符
- to_submit:SQ 中提交的 I/O 请求数量
- min_complete:最少完成的 I/O 请求数量
- flags:用于指定 I/O 请求的类型,如 IORING_ENTER_GETEVENTS、IORING_ENTER_SQ_WAKEUP 等
- sig:用于指定信号集,如果 flags 指定了 IORING_ENTER_GETEVENTS,那么 sig 必须是一个有效的信号集
- 在默认模式下,如果指定了 min_complete,那么 io_uring_enter(2)会等待至少 min_complete 个 I/O 请求完成,然后返回。如果没有指定 min_complete,那么 io_uring_enter(2)会等待 SQ 中所有的 I/O 请求完成,然后返回。在 polling 模式下,如果指定了 min_complete,如果 min_complete 为 0,则要求内核返回当前以及完成的所有 events,无阻塞;如果 min_complete 大于 0,如果有事件完成,内核仍然立即返回;如果没有完成事件,内核会 poll,等待指定的次数完成,或者这个进程的时间片用完。
- 这个系统调用用于初始化和完成(initiate and complete)I/O,使用共享的 SQ 和 CQ。单次调用同时执行:
# 4. io_uring 的高级特性
- io_uring 还提供了一些用于特殊场景的高级特性
- File registration(文件注册):每次发起一个指定文件描述的操作,内核都需要花费一些时钟周期(cycles)文件描述符映射到内部表示。对于那些 针对同一文件进行重复操作 的场景,io_uring 支持提前注册这些文件,后面直接查找就行了。
- Buffer registration(缓冲区注册):与 file registration 类似,Direct I/O 场景中,内核需要 map/unmap memory areas。io_uring 支持提前注册这些缓冲区(buffers)。
- Poll ring(轮询环形缓冲区):对于非常快是设备,处理中断的开销是比较大的。io_uring 允许用户关闭中断,使用轮询模式。
- Linked operations(链接操作):允许用户发送串联的请求。这两个请求同时提交,但后面的会等前面的处理完才开始执行。
# 三、io_uring 的使用示例
liburing 提供了一个简单的高层 API, 可用于一些基本场景,应用程序避免了直接使用更底层的系统调用。此外,这个 API 还避免了一些重复操作的代码,如设置 io_uring 实例。
# 1. 在项目中引入 liburing
- apt-get 安装 liburing
- 在 ubuntu 系统下安装 liburing 十分简单,只需要执行以下命令即可 (注意:ubuntu 版本需要大于等于 20.04,因为内核版本需要大于等于 5.4)
1sudo apt-get install liburing-dev - 在项目中引入 liburing 的头文件
1#include "liburing.h" - 在项目中引入 liburing 的库文件
1-luring
- 在 ubuntu 系统下安装 liburing 十分简单,只需要执行以下命令即可 (注意:ubuntu 版本需要大于等于 20.04,因为内核版本需要大于等于 5.4)
- 手动安装
- 下载 liburing 的源码
1git clone https://github.com/axboe/liburing.git - 编译 liburing
1 2 3 4cd liburing ./configure make -j sudo make install - 在项目中引入 liburing 的头文件
1#include "liburing.h" - 在项目中引入 liburing 的库文件
1-luring
- 下载 liburing 的源码
# 2. 代码示例
- 使用 4 个 SQE,从输入文件中读取最多 16KB 的数据。
| |
- link-cp:使用 io_uring 高级特性 SQE chaining 实现复制文件功能,将创建一个长度为 2 的 SQE 链,第一个 SQE 用于读,第二个 SQE 用于写。
| |
- copy_file():高层复制循环逻辑;它会调用 queue_rw_pair(ring, this_size, offset) 来构造 SQE pair;并通过一次 io_uring_submit() 调用将所有构建的 SQE pair 提交。 这个函数维护了一个最大 DQ 数量的 inflight SQE,只要数据 copy 还在进行中;否则,即数据已经全部读取完成,就开始等待和收割所有的 CQE。
- queue_rw_pair() 构造一个 read-write SQE pair. read SQE 的 IOSQE_IO_LINK flag 表示开始一个 chain,write SQE 不用设置这个 flag,标志着这个 chain 的结束。用户 data 字段设置为同一个 data 描述符,并且在随后的 completion 处理中会用到。
- handle_cqe() 从 CQE 中提取之前由 queue_rw_pair() 保存的 data 描述符,并在描述符中记录处理进展(index)。 如果之前请求被取消,它还会重新提交 read-write pair。 一个 CQE pair 的两个 member 都处理完成之后(index==2),释放共享的 data descriptor。最后通知内核这个 CQE 已经被消费。
# 3. 最佳实践
io_uring 是一个高性能的异步 I/O 框架,它在 Linux 内核中引入了一种新的 I/O 模型,可以显著提高 I/O 操作的吞吐量和响应速度。然而,要充分发挥 io_uring 的优势,需要注意一些优化和最佳实践。
| 优化 | 说明 |
|---|---|
| 批量提交(Batch Submission) | io_uring 支持批量提交多个 I/O 请求,以减少系统调用的开销。通过一次性提交多个请求,可以减少上下文切换和系统调用的次数,提高效率。建议根据系统的负载和性能需求,合理选择批量提交的数量。 |
| 预分配 I/O 请求(Pre-allocate I/O Requests) | 在使用 io_uring 之前,可以预先分配一定数量的 I/O 请求,避免在运行时动态分配请求的开销。这样可以减少内存分配和释放的次数,提高性能。 |
| 使用 I/O 链接(I/O Linking) | io_uring 支持将多个 I/O 请求链接在一起,形成一个链表。这样可以减少上下文切换的开销,提高效率。在链接 I/O 请求时,需要注意保持请求的顺序和正确处理链接的完成。 |
| 使用 I/O 向量(I/O Vector) | io_uring 支持使用 I/O 向量来进行批量的读写操作。通过使用 I/O 向量,可以减少系统调用的次数,提高效率。在使用 I/O 向量时,需要注意正确设置每个向量的偏移量和长度。 |
| 使用事件完成通知(Event Completion Notification) | io_uring 支持使用事件完成通知来提高效率。通过使用事件完成通知,可以避免轮询等待 I/O 完成,而是在 I/O 完成时立即得到通知。这样可以减少 CPU 的占用和响应时间。 |
| 合理设置 I/O 队列深度(I/O Queue Depth) | io_uring 的性能受到 I/O 队列深度的影响。较大的队列深度可以提高并发性能,但也会增加内存开销。建议根据系统的负载和性能需求,合理设置 I/O 队列深度。 |
| 使用合适的内存分配策略 | io_uring 的性能也受到内存分配策略的影响。建议使用高效的内存分配器,如 jemalloc 或 tcmalloc,来减少内存分配和释放的开销。 |
| 避免阻塞操作 | io_uring 是一个异步 I/O 框架,应尽量避免在 io_uring 的上下文中进行阻塞操作。阻塞操作会导致 io_uring 的性能下降,甚至可能引起死锁。 |
| 使用合适的文件描述符(File Descriptor) | io_uring 支持对文件、套接字和管道等不同类型的文件描述符进行操作。在使用 io_uring 时,需要根据实际情况选择合适的文件描述符类型,并正确设置相关的参数。 |
| 注意错误处理 | 在使用 io_uring 时,需要注意正确处理错误。io_uring 的错误码可能是负数,可以使用 errno.h 中定义的错误码来进行解析和处理。 |
通过遵循上述优化和最佳实践,可以充分发挥 io_uring 的性能优势,提高系统的 I/O 性能和响应速度。然而,需要根据具体的应用场景和需求,进行合理的调优和配置。在实际使用中,可以通过性能测试和监测来评估和优化 io_uring 的性能。
# 结论
io_uring 是一个高性能的异步 I/O 框架,通过在 Linux 内核中引入新的 I/O 模型,它能够显著提高 I/O 操作的吞吐量和响应速度。本章节我们深入探讨了 io_uring 的优化和最佳实践,以帮助开发者充分发挥其性能优势。
在使用 io_uring 时,我们可以采取一系列优化措施来提高性能。首先,批量提交多个 I/O 请求可以减少系统调用的开销,提高效率。此外,预分配 I/O 请求、使用 I/O 链接和 I/O 向量等技术也能够减少内存分配和系统调用的次数,进一步提升性能。
除了以上的优化技巧,我们还介绍了一些最佳实践。合理设置 I/O 队列深度、使用事件完成通知和选择合适的文件描述符类型等都能够对性能产生积极影响。此外,避免阻塞操作和正确处理错误也是使用 io_uring 时需要注意的事项。
通过遵循这些优化和最佳实践,开发者可以充分发挥 io_uring 的性能优势,提高系统的 I/O 性能和响应速度。然而,需要根据具体的应用场景和需求,进行合理的调优和配置。在实际使用中,可以通过性能测试和监测来评估和优化 io_uring 的性能。
io_uring 作为一个新兴的异步 I/O 框架,具有很大的潜力和广阔的应用前景。它已经在许多领域得到了广泛的应用,如数据库、网络服务器和存储系统等。随着对 io_uring 的进一步研究和优化,相信它将在未来发挥更大的作用,并成为开发者们的首选工具之一。
# 参考文献
[1] io_uring 官方文档:https://kernel.dk/io_uring.pdf
[2] How io_uring and eBPF Will Revolutionize Programming in Linux[1], ScyllaDB
[3] 2020 An Introduction to the io_uring Asynchronous I/O Framework[2], Oracle, 2020
[4] liburing GitHub 仓库:https://github.com/axboe/liburing