
# 一、概述
在编程中我们通常会遇到如下问题:
- 程序运行慢,效率低
- 消耗了大量的内存
- segmentation fault
- 程序崩溃
- 程序运行结果不正确……
随着处理器复杂度的增加
- 我们不再能够轻松地跟踪代码段的执行
- 静态/动态分支预测、预取、顺序调度……
- 仅使用墙钟时间来衡量代码性能是不够的。
- 我们还需要了解到底发生了什么
- 我们不再能够轻松地跟踪代码段的执行
对于性能评估,有直接和间接两种方法
- 直接方法:需要某些形式的显示插装
- 追踪
- 为每个测量事件生成记录
- 只有在产生大量数据情况下,出现的性能异常数据才有用
- 聚合
- 减少数据在运行时平均/最小/最大测量
- 适用于应用程序和体系结构和描述和优化
- 追踪
- 间接方法:不需要插装,可不修改应用程序
- 事实上,直接和间接方法的界限有些模糊
- 聚合:如 gprof,可以不修改程序,但是需要重新编译链接
- 直接方法:需要某些形式的显示插装
实际编程中,常见的分析工具如下:
类型 工具 程序调试 gdb 程序调试 valgrind 程序优化 gprof 程序优化 perf 程序优化 Intel VTune Amplifier
# 二、程序调试分析工具简介
- 程序中的错误按其性质可以分为三种:
- 编译错误 :即语法错误,主要是程序代码中有不符合所用编程语言语法规则的错误。
- 运行时错误 :如对负数开平方、除数为 0、循环终止条件永远不能达到等。
- 逻辑错误 :这类错误往往是编程前对求解的问题理解不正确或算法不正确引起的,它们很难查找(数组越界、空指针)
- 程序调试就是查找程序中的错误,诊断其准确位置,并予以改正。
# 1. gdb
- GDB 是 GNU 开源组织发布的一个强大的 UNIX 下的程序调试工具
- GDB 具备如下 4 个方面的功能:
- 启动程序,可以按用户要求影响程序的运行行为
- 可以让被调试的程序在用户所指定的断点处暂停(断点可以是条件表达式)
- 当程序被暂停时,可以检查此时用户程序中所发生的事情
- 动态改变用户程序的执行环境,这样就可以先纠正一个错误的影响,然后再纠正其他错误
- 为了发挥 GDB 的全部功能,需要在编译源程序时使用
-g选项
| |
启动 GDB,以参数形式将可执行程序传递给 GDB
- gdb program
1gdb ./proc- gdb -p pid
1gdb -p `pidof proc`- gdb program core
1gdb ./proc core.xxx- gdb attach pid
1gdb attach 2313启动 gdb 后就显示其提示符:(gdb),并等待用户输入相应的内部命令
- 设置断点、设置运行参数和环境变量、跟踪调试命令、查看栈信息……
用户可以利用命令 quit 终止其执行,退出 gdb 环境
gdb 常用命令列表如下:
命令 解释 简写 file 装入想要调试的可执行文件 无 list 列出产生执行文件源代码的一部分 l next 执行一行源代码但不进入函数内部 n step 执行一行源代码而且进入函数内部 s run 执行当前被调试的程序 r continue 继续执行程序 c quit 终止 GDB q print 输出当前指定变量的值 p break 在代码里设置断点 b info break 查看设置断点的信息 ib delete 删除设置的断点 d watch 监视一个变量的值,一旦值有变化,程序停住 wa help GDB 中的帮助命令 h 设置断点:
- 编译源程序时需要使用
-g选项 - 在 GDB 中用 break 命令(其缩写形式为 b)设置断点:
- break linenum 在当前文件指定行 linenum 处设置断点,停在该行开头
- break linenum if condition 在当前文件指定行 linenum 处设置断点,但仅在条件表达式 condition 成立时才停止程序执行
- break function 在当前文件函数 function 的入口处设置断点
- break file:linenum 在源文件 file 的 linenum 行上设置断点
- break file:function 在源文件 file 的函数 function 的入口处设置断点
- break *address 运行程序在指定的内存地址 address 处停止
- break 不带任何参数,则表示在下一条指令处停止
- 断点应设置在可执行的行上,不应是变量定义之类的语句
- 编译源程序时需要使用
删除断点:
- delete [bkptnums]
显示断点:
- info breakpoints [num]
- info break [num]
运行程序:
- run [args]
程序的单步跟踪和
- step [N] 参数 N 表示每步执行的语句行数,进入被调用函数内部执行
- next [N] 参数 N 表示每步执行的语句行数,被调用函数被当做一条指令执行
- stepi(缩写为 si)或 nexti(缩写为 ni)命令一条一条地执行机器指令
程序的连续执行
- 利用 continue,c 或 fg 命令连续执行到下一个断点
显示源文件命令 list (l)
- list:没有参数,显示当前行之后或周围的 10 多行
- list -:显示之前的 10 行
- list [file]:num:显示源文件 file 中给定行号 num 周围的 10 行。如果缺少 file,则默认为当前文件。例如,list 100
- list start, end:显示从行号 start 至 end 之间的代码行。例如,list 20,38
- list [file:]fun:显示源文件 file 中指定函数 function 的代码行。如果缺少 file,则默认为当前文件。例如,list meng1.c:square
- set listsize linenum : 可以使用该命令设置一次显示的行数
查看运行时数据命令 print (p)
- 当被调试的程序停止时,可以用 print 命令或同义命令 inspect 来查看当前程序中运行的数据
- print 命令的一般使用格式:print [/fmt] exp
- print i (或 p i) 显示当前变量 i 的值
- print i*j (或 p i*j) 将根据程序当前运行的实际情况显示出 i*j 的值
- print 所支持的运算符:
- 取地址&符号
- @ 是一个与数组有关的双目运算符,使用形式如
- print array@10 打印从 array(数组名,即数组的基地址)开始的 10 个值
- print array[3]@5 打印从 array 第三个元素开始的 5 个数组元素的数值
- file::i 或 function ::i 表示文件或者函数中 i 的值
注释
GDB 使用示例
| |
- 编译带调试信息的可执行文件
| |
- 启动 GDB
| |
- 调试结果
| |
- 总的来说,GDB 调试的过程为:
- 编译带调试信息的可执行文件
- 启动 GDB,开始调试
- GDB 中查看文件
- 设置断点
- 查看断点情况
- 运行代码
- 跟踪变量值
- 删除所设断点
- 恢复程序运行
- 退出 GDB
# 2. Valgrind
- Valgrind 是一个 Linux 下灵活的调试和剖析工具
- 收集各种有用的运行时信息,可以帮助找到程序中潜在的 bug 和性能瓶颈
- Valgrind 包含多个工具:
| 工具 | 功能 |
|---|---|
| Memcheck | 这是 valgrind 应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存、使用已经释放了的内存、内存访问越界等 |
| Callgrind | 主要用来检查程序中函数调用过程中出现的问题 |
| Cachegrind | 主要用来检查程序中缓存使用出现的问题 |
| Helgrind | 主要用来检查多线程程序中出现的竞争问题 |
| Massif | 主要用来检查程序中堆栈使用中出现的问题 |
| Extensio | 可以利用 core 提供的功能,自己编写特定的内存调试工具 |
- Valgrind 使用需要先进行安装,在 ubuntu 下可以使用 apt-get 进行安装
| |
- 为了使 Valgrind 发现的错误更精确,建议在编译时加上
-g参数,编译优化选择O0,即:
| |
valgrind 命令格式为:
valgrind [options] prog-and-args [options]- [options]: 常用选项,适用于所有 Valgrind 工具
- –tool=<name>: 最常用的选项,运行 valgrind 中名为 toolname 的工具,默认 memcheck
- -h|–help:显示帮助信息
- –version:显示 valgrind 内核的版本,每个工具都有各自的版本
- -q|–quiet:安静地运行,只打印错误信息
- -v|–verbose:更详细的信息,增加错误数统计
- ……
Memcheck 内存错误检查:
- 可以检查出下列几种错误
- 使用已经释放的内存
- 内存块越界
- 使用未初始化的变量
- 内存泄漏
- 同一个内存块释放多次
- Memcheck 命令行选项:
- –leak-check=<no|summary|yes|full> [default: summary]
- summary 是给出最后 leak 的汇总,yes 或者 full 将会给出比较详细的 leak 信息
- –leak-resolution=<low|med|high> [default: high]
- 用于合并 leak 信息来源的 backtraces,low 是有两层匹配的时候就可以合并,med 是四层,high 必须完全比配。该选项不影响查找 leak 的能力,只影响结果的显示方式
- –leak-check=<no|summary|yes|full> [default: summary]
- 可以检查出下列几种错误
Cachegrind 缓存检查
- 通过模拟 cpu 的 1,3 级缓存,收集应用程序运行时关于 cpu 的一些统计数据,最后在将明细数据和汇总信息打印出来
- 执行方式:
- $ valgrind –tool=cachegrind your_application
- cachegrind 的结果也会以输出文件的方式输出更多的细节,输出文件的缺省文件名是 cachegrind.out.<pid>,其中<pid>是当前进程的 pid。该文件名可以通过–cachegrind-out-file 选择指定更可读的文件名,这个文件将会成为 cg_annotate 的输入
- $ valgrind –tool=cachegrind your_application
- Cachegrind 命令行选项:
- –cache-sim=no|yes [yes]
- 指定是否收集 cache accesses 和 miss counts
- –branch-sim=no|yes [no]
- 指定是否收集 branch instruction 和 misprediction counts
- –cache-sim=no|yes [yes]
Callgrind 函数调用分析
- Callgrind 收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行 cache 模拟。被分析的程序编译时要加
-g,编译优化选项建议选择-O2 - 执行方式:
- $ valgrind –tool=callgrind your_application
- 输出文件的缺省文件名是 callgrind.out.<pid> ,其中<pid>是当前进程的 pid
- $ valgrind –tool=callgrind your_application
- Cachegrind 命令行选项:
- –callgrind-out-file=<file>
- 指定 profile data 的输出文件,而不是缺省命名规则生成的文件
- –dump-line=<no|yes> [default: yes]
- 事件计数将以 source line 作为统计的粒度,但是源程序在编译的时候加入
-g选项
- 事件计数将以 source line 作为统计的粒度,但是源程序在编译的时候加入
- –callgrind-out-file=<file>
- Callgrind 收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行 cache 模拟。被分析的程序编译时要加
Helgrind 多线程分析器
- 主要用来检查多线程程序中出现的竞争问题
- 执行方式:
- $ valgrind –tool=helgrind your_application
Massif 堆栈分析
- 堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif 能帮助我们减少内存的使用
- 执行方式:
- $ valgrind –tool=massif your_application
- 输出文件:massif.<pid>.ps massif. <pid>.txt,其中<pid>是当前进程的 pid
- $ valgrind –tool=massif your_application
注释
Valgrind 使用示例 1:内存检查
| |
- 编译并运行:
| |
- 输出结果:
| |
- 可以看到:valgrind 检测到了两个错误,一个是内存越界,一个是内存泄漏
- Invalid write of size 4:提示了内存越界的错误
- 40 bytes in 1 blocks are definitely lost in loss record 1 of 1:提示了内存泄漏的错误
注释
Valgrind 使用示例 2:Cachegrind 缓存检查
| |
- 编译并运行:
| |
- 当前目录下会生成一个 cachegrind.out.<pid>文件,其中<pid>是当前进程的 pid,使用
ls命令查看:
| |
- 使用
cg_annnotate命令查看 cachegrind.out.<pid>文件的内容:
| |
- 可以看到,cachegrind.out.<pid>文件中记录了程序运行时的缓存信息,包括 I1 cache,D1 cache,LL cache 等,这些信息可以帮助我们分析程序的缓存使用情况
- cachegrind 输出的信息中,我们比较关注的是:
- Ir: 指令读取次数
- I1mr:指令读取 miss 次数
- ILmr:指令读取 miss 次数
- Dr:数据读取次数
- D1mr:数据读取 miss 次数
- DLmr:数据读取 miss 次数
- Dw:数据写入次数
- D1mw:数据写入 miss 次数
- DLmw:数据写入 miss 次数
注释
Valgrind 使用示例 3:Callgrind 调用图检查
| |
- 编译并运行:
| |
- 当前目录下会生成一个 callgrind.out.<pid>文件,其中<pid>是当前进程的 pid,使用
ls命令查看:
| |
- 使用
callgrind_annotate命令查看 callgrind.out.<pid>文件的内容:
| |
- 可以看到,callgrind.out.<pid>文件中记录了程序运行时的调用图信息,包括函数调用次数,函数调用路径等,这些信息可以帮助我们分析程序的调用图使用情况
- callgrind 输出的信息中,我们比较关注的是:
- Ir:指令读取次数
# 三、程序优化分析工具简介
- 运行缓慢的代码将消耗大量的 CPU 时间, 因此,我们必需评估代码的运行效率, 在整个代码的设计和实现周期里都需考虑性能。
- Amdahl 定律:在一个系统中,如果某部分的执行时间占总执行时间的比例为 p,那么优化这部分的执行时间,系统的整体执行时间至少降低 p 倍。
$$ \begin{array}{c}T_{new} = T_{old} \times (1-p) + \frac{T_{old} \times p}{k} \ = T_{old} \times (1-p + \frac{p}{k})\end{array} $$
- 根据 Amdahl 定律,对热点部分进行性能优化能够获得最大收益
- 常见的程序优化分析工具有:
- gprof
- perf
- Vtune
- ……
# 1. gprof
Gprof,又称 GNU profiler,是 Linux/Unix 系统上的性能 profiling 软件,其功能是获得程序各个函数运行时间,帮助找出耗时最多的函数,以及显示函数调用关系,包括调用次数,帮助分析程序运行流程。
基本原理为:
- 编译链接程序时,编译器在程序的每个函数中都加入了一个函数,程序里的每一个函数都会调用该函数, 该函数 会在内存中保存一张函数调用图,并通过函数调用堆栈的形式查找子函数和父函数的地址
- 调用图也保存了所有与函数相关的调用时间,调用次数等信息
Gprof 需要先使用
-pg编译和链接应用程序
| |
- 执行应用程序使之生成供 gprof 分析的数据,生成 gmon.out
| |
- 使用 gprof 程序分析应用程序生成的数据
| |
- gprof 的输出信息包括:
| 序号 | 列名 | 说明 |
|---|---|---|
| 1 | time | 函数执行时间占总执行时间的百分比 |
| 2 | cumulative seconds | 函数和上列函数累计执行的时间 |
| 3 | self seconds | 函数本身所执行的时间 |
| 4 | calls | 函数被调用次数 |
| 5 | self ms/call | 每一次调用花费在函数的时间 |
| 6 | total ms/call | 每一次调用,花费在函数及其衍生函数的平均时间 |
| 7 | name | 函数名 |
- gprof 常用的命令选项有:
| 选项 | 说明 |
|---|---|
| -b | 不再输出统计图表中每个字段的详细描述 |
| -p | 只输出函数的调用图 |
| -q | 只输出函数的时间消耗列表 |
| -e Name | 不再输出函数 Name 及其子函数的调用图 |
| -E Name | 不再输出函数 Name 及其子函数的调用图,在总时间和百分比时间计算中排除了由函数 Name 及其子函数所用的时间 |
| -f Name | 输出函数 Name 及其子函数的调用图 |
| -F Name | 输出函数 Name 及其子函数的调用图,类似于-f,但它在总时间和百分比时间计算中仅使用所打印的例程的时间 |
- 对于由多个源文件组成的程序,编译时需要在生成每个.o 文件的时候加上
-pg参数,同时在链接的时候也要加上-pg参数 -pg参数只能记录源代码中各个函数的调用关系,而不能记录库函数的调用情况- 要想记录每个库函数(如 memcpy、memset、sprintf 等函数)的调用情况,链接的时候必须指定库函数的动态(或者静态)链接库 libc_p.a,即加上-lc_p,而不是-lc
- $ gcc example1.c –pg -lc_p -o example1
- 若只有部分代码在编译时指定了
-pg参数,则生成的 gmon.out 文件中将缺少部分函数,也没有这些函数的调用关系,但是并不影响 gprof 对其它函数进行记录
注释
gprof 使用示例
| |
- 编译链接并运行程序
| |
- 在当前目录下生成 gmon.out 文件,使用 gprof 分析
| |
- gprof.out 文件内容如下
| |
- 可以看到:程序中只有两个函数,fast_multiply 和 slow_multiply,gprof 分析结果中也只有这两个函数,但是这两个函数的调用次数都是 6000 次,这是因为 gprof 默认的采样周期是 0.01 秒,而程序运行时间很短,所以两个函数的调用次数都是 6000 次,如果程序运行时间更长,那么两个函数的调用次数就会不一样了。
# 2. perf
Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具,基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析,常用于性能瓶颈的查找与热点代码的定位。
Perf 包含 22 种子工具的工具集,以下是最常用的 5 种:
- perf list:列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点
- perf top:类似于 Linux 的 top 命令,对系统性能进行实时分析
- perf stat:剖析某个特定进程的性能概况,包括 CPI、Cache 丢失率等
- perf record:收集采样信息,并将其记录在数据文件中
- perf report:读取 perf record 创建的数据文件,并给出热点分析结果
perf list
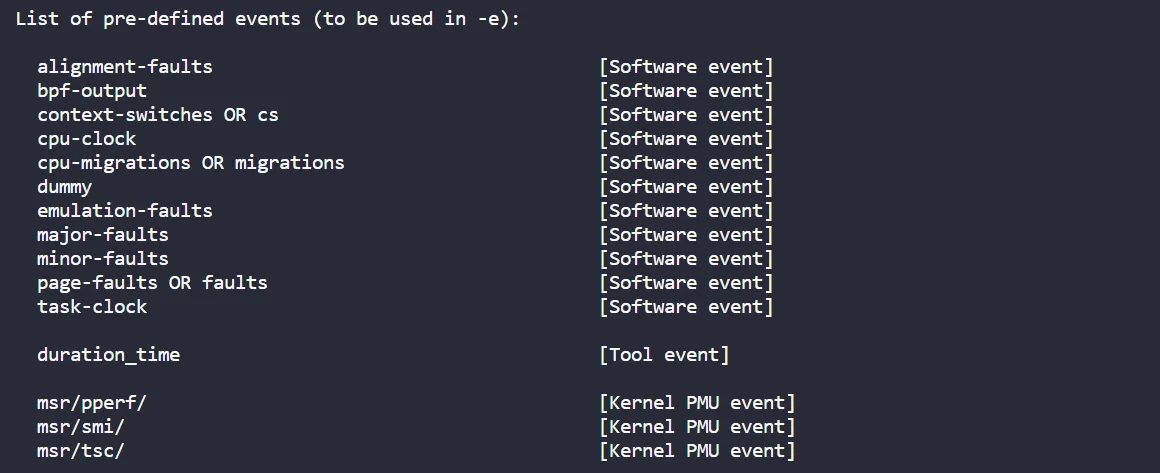
- 查看当前软硬件平台支持的性能事件列表
- 事件分为以下三种:
- Hardware Event: 由 PMU 硬件产生的事件,比如 cache 命中,当要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样
- Software Event: 内核软件产生的事件,比如进程切换、tick 数等
- Tracepoint event: 内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等
- 命令格式:
perf list [hw | sw | cache | tracepoint] - perf list 工具仅列出了具有字符描述的硬件性能事件
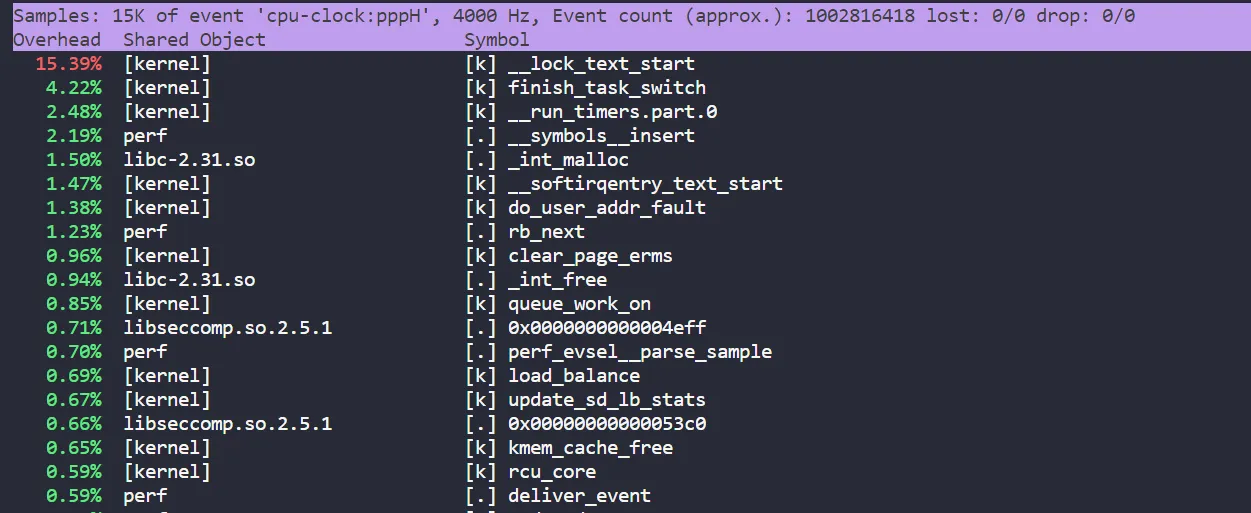
perf top
- 主要用于实时分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数、模块函数与内核函数,甚至能够定位到热点指令,默认的性能事件为 cpu cycles
- 命令格式:
perf top [<options>] - 常用命令行参数
- -e <event>:指明要分析的性能事件
- -p <pid>:仅分析目标进程及其创建的线程
- -k <path>:带符号表的内核映像所在的路径
- -K:不显示属于内核或模块的符号
- -U:不显示属于用户态程序的符号
- -d <n>:界面的刷新周期,默认为 2s
- -G:得到函数的调用关系图
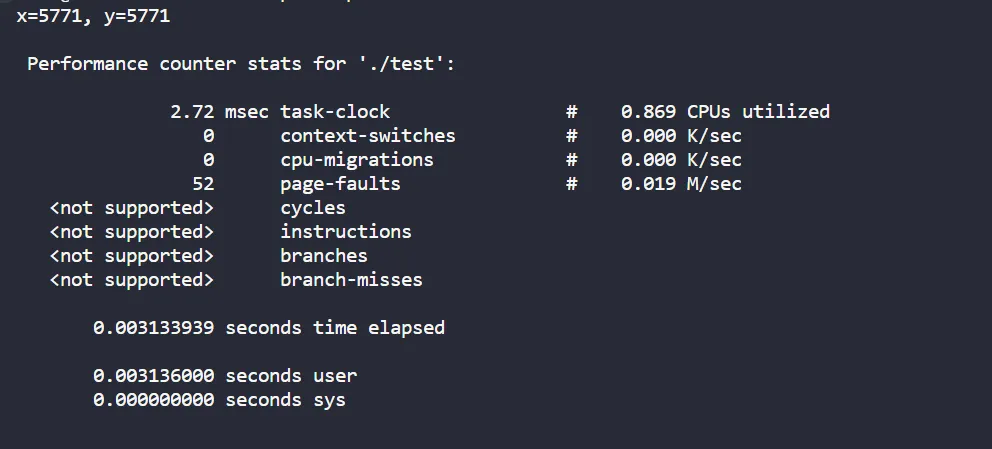
perf stat
- 用于分析指定程序的性能概况
- 命令格式:
perf stat [<options>] [<command>] - 常用命令行参数
- -p <pid>:仅分析目标进程及其创建的线程
- -a:从所有 CPU 上收集性能数据
- -r <n>:重复执行命令求平均
- -C <cpu>:从指定 CPU 上收集性能数据
- -v:显示更多性能数据
- -n:只显示任务的执行时间
- -x <separator>:指定输出列的分隔符
- -o <file>:指定输出文件。–append 指定追加模式,–pre <command>执行目标程序前先执行的程序,–post <command>执行目标程序后再执行的程序
perf record
- 收集采样信息,并将其记录在数据文件中
- 随后可以通过其它工具(perf report)对数据文件进行分析,结果类似于 perf top
- 命令格式:
perf record [<options>] [<command>]
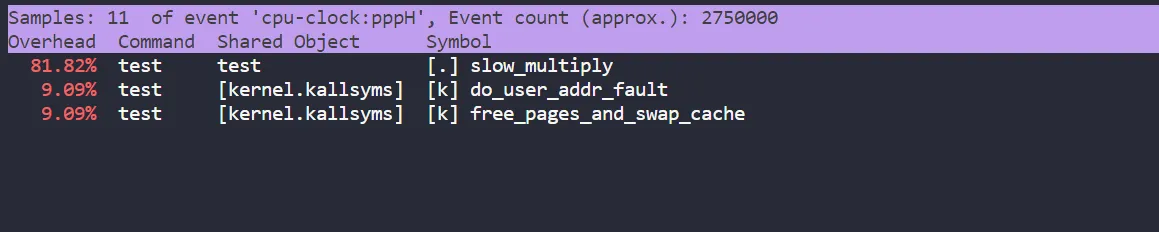
perf report
- 读取 perf record 创建的数据文件,并给出热点分析结果
- 命令格式:
perf report [<options>] [<datafile>]
注释
perf 使用示例
- apt-get 安装 perf
| |
- 使用 perf list 查看当前系统支持的性能事件
| |
- perf list 结果:
- 使用 perf top 查看当前系统的热点函数
| |
- perf top 结果:
使用 perf stat 查看测试程序的性能概况
使用在 gprof 时的程序代码 test.c
执行 perf stat
| |
- perf stat 结果:
- 使用 perf record 和 perf report 查看热点函数
| |
- perf report 结果:
进阶:火炬图 FlameGraph:基于 perf record 和 perf report 的结果绘制火炬图
下载 FlameGraph 工具:
1git clone https://github.com/brendangregg/FlameGraph.git收集性能数据:
1perf record -g ./test- 对可执行文件 test 进行采样,每秒 99 次,采样结果保存在 perf.data 文件中
使用 FlameGraph 生成火炬图:运行以下命令使用 FlameGraph 生成火炬图:
1 2perf script | ./FlameGraph/stackcollapse-perf.pl > out.perf-folded ./FlameGraph/flamegraph.pl out.perf-folded > perf.svg
FlameGrpah 绘制结果:
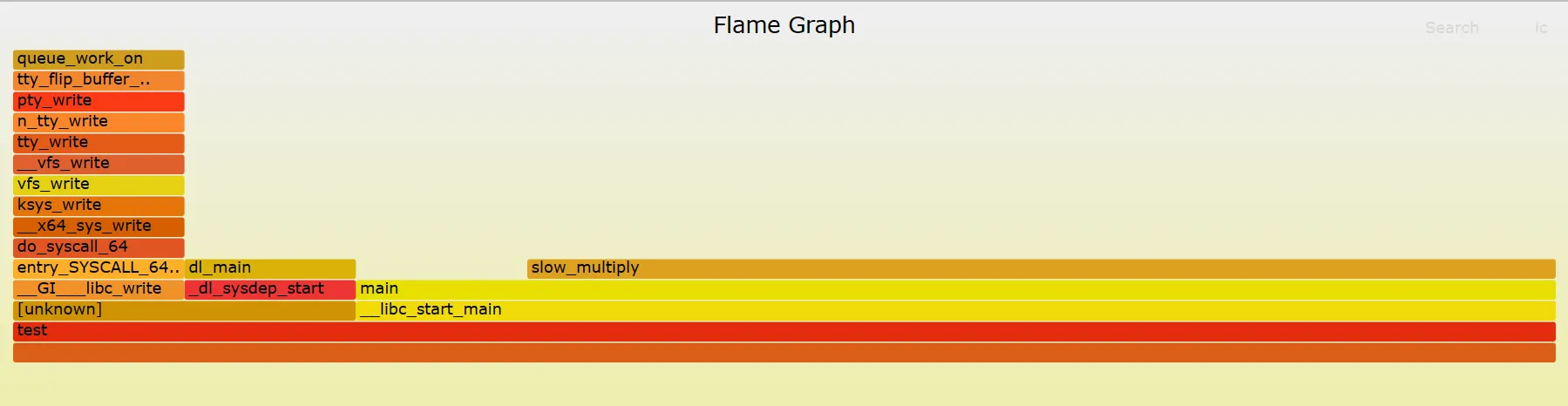
# 3. Vtune
- Intel VTune Amplifier XE 是 Intel 针对其处理器的性能测试分析工具,支持 Windows/Linux,提供图形用户界面和命令行接口,支持 C、C++、Fortran、C#、Java、.NET 等多种语言。
- Vtune 基于硬件性能监视部件(PMU)性能测试,获得微体系结构级数据
- 指令类型与数目
- 存储访问事件
- 指令流水线事件
- Vtune 性能分析粒度包括:进程、线程、子程序、代码行
- Vtune 可以帮助用户分析算法选择,标识出应用程序怎样更好的利用可用的硬件资源,可以帮助用户如下性能方面问题:
- 程序中或者整个系统中时间消耗最多的函数
- 没有有效利用处理器时间的代码片段
- 优化串行和线程化性能的最好代码片段
- 影响程序性能的同步对象
- 程序的 I/O 操作是否花费很多时间,以及在哪里、为什么花费时间
- 不同的同步方法,不同的线程数量或者不同算法对于性能的影响
- 线程活跃性和变迁
- 代码中硬件相关的瓶颈
- Vtune 还可以提供寻找热点、分析锁和等待以及标识硬件问题等功能
- Vtune 命令格式为:
| |
amplxe-cl:VTune Amplifier 命令行工具名称
<-action> :要执行的操作,如 collect 或 report。每个命令必须只有一个操作。如,一个命令中不能同时有收集数据和生成报表
[-action-option] :操作选项,用于修改特定操作的行为。每个操作可以有多个操作选项,操作选项使用不当会导致使用错误
[-global-option] :全局选项,用于以相同的方式修改所有操作的行为。每个操作可以有多个全局选项
[–] <target> :要分析的目标程序
[target-options] :目标程序参数选项
Actions:amplxe-cl 支持不同的命令选项
- collect:运行指定的分析类型并将数据收集到结果中
- collect-with:运行用户设置的基于事件的硬件采样或用户模式采样,并跟踪收集
- command:向正在运行的收集操作发出命令
- finalize:执行符号解析以完成或重新获得结果
- help: 显示命令行参数的简短解释
- import:导入一个或多个收集数据文件/目录
- report:从分析结果中生成指定类型的报表
- version:显示 amplxe-cl 版本信息
Action Options
- 定义适用于指定操作的行为,如“-result-dir”选项是指定收集操作结果的目录路径
- 若要访问操作的可用操作选项列表,请使用命令
amplxe-cl –help <action>,其中 <action> 是可用操作之一;要查看所有可用的操作, 请使用命令“amplxe-cl –help” - 如果在同一命令行上使用了相反的操作选项,则将应用最后的操作选项
- 忽略上下文中冗余或没有意义的操作选项
- 使用不适当的操作选项,会导致意外行为返回使用错误
Global Options
- 定义适用于所有操作的行为,如“-quiet”选项会取消所有操作的非必需消息。每个命令可能有一个或多个全局选项
注释
Vtune 使用示例:
同样使用在 gprof 时的程序代码 test.c,但是需要使用 icc 编译器编译,因为 Vtune 只支持 icc 编译器编译的程序
安装 icc 编译器:Intel C++ Compiler
- 注:icc 编译器是收费的,需要购买或者申请学生许可
安装 Vtune:Intel Vtune
Ubuntu 下 apt 安装 Vtune
| |
- 编译程序:
| |
- 激活 vtune 环境:
| |
- 收集 hosspot 数据:
| |
# 总结
本文介绍了几种常用的程序调试与优化分析工具,这些工具在软件开发过程中发挥着重要的作用。调试工具如 gdb 和 Valgrind 帮助开发人员快速定位和解决程序中的错误和问题,保障了代码的质量和稳定性。而优化分析工具,如 gprof、perf 和 Vtune,则专注于提升程序性能,帮助开发人员找到性能瓶颈并进行优化。
通过合理使用这些工具,开发人员可以更高效地开发和维护代码,减少调试时间,提高软件性能,并且为用户提供更好的使用体验。在今后的软件开发过程中,了解和掌握这些工具将是提高开发技能和水平的重要一步。同时,不断了解新的调试与优化工具也是跟上技术发展的必要途径。
# 参考资料
[1] gdb 官方网站
[2] valgrind 官方网站
[3] gprof 官方文档
[4] perf 文档