
内存的访问和管理是所有编程语言的重要部分。在现代加速器中,内存管理对高性能计算有着很大的影响。
因为多数工作负载被加载和存储数据的速度所限制,所以有大量低延迟、高带宽的内存对性能是十分有利的。然而,大容量、高性能的内存造价高且不容易生产。因此,在现有的硬件存储子系统下,必须依靠内存模型获得最佳的延迟和带宽。CUDA 内存模型结合了主机和设备的内存系统,展现了完整的内存层次结构,能显式地控制数据布局以优化性能。
# 一、内存层次结构的优点
程序具有局部性特点,包括:
- 时间局部性:如果一个数据被访问,那么它在不久的将来也会被访问。
- 空间局部性:如果一个数据被访问,那么它附近的数据也会被访问。
现代计算机的内存结构主要如下:
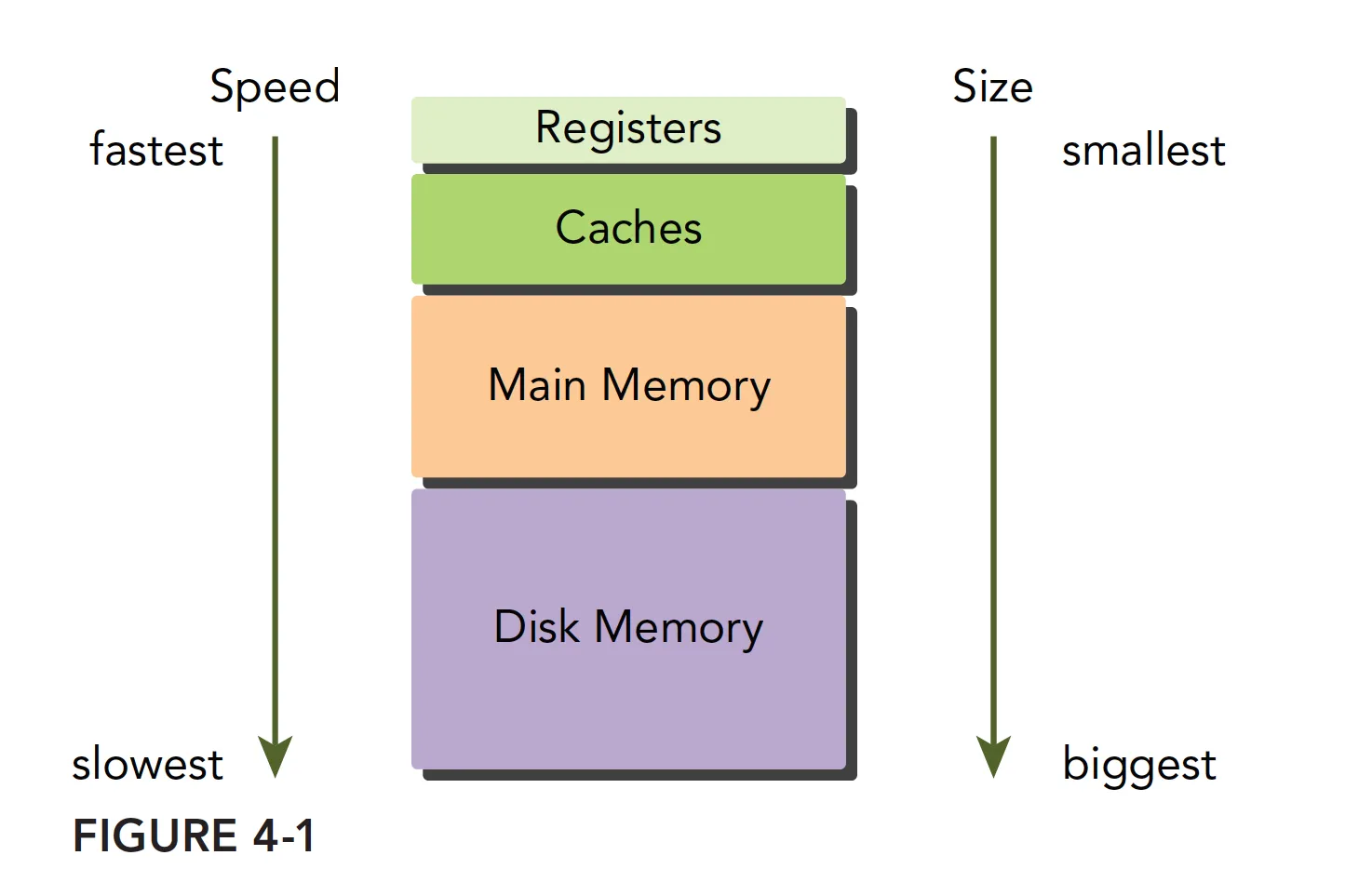
一个内存层次结构由具有不同延迟、带宽和容量的多级内存组成。通常,随着从处理器到内存延迟的增加,内存的容量也在增加。
CPU 和 GPU 的主存都采用的是 DRAM(动态随机存取存储器),而低延迟内存(如 CPU 一级缓存)使用的则是 SRAM(静态随机存取存储器)。内存层次结构中最大且最慢的级别通常使用磁盘或闪存驱动来实现。在这种内存层次结构中,当数据被处理器频繁使用时,该数据保存在低延迟、低容量的存储器中;而当该数据被存储起来以备后用时,数据就存储在高延迟、大容量的存储器中。这种内存层次结构符合大内存低延迟的设想。
GPU 和 CPU 的内存设计有相似的准则和模型。但它们的主要区别是,CUDA 编程模型能将内存层次结构更好地呈现给用户,能让我们显式地控制它的行为。
# 二、CUDA 内存模型
对于程序员来说,一般有两种类型的存储器:
- 可编程的:你需要显式地控制哪些数据存放在可编程内存中
- 不可编程的:你不能决定数据的存放位置,程序将自动生成存放位置以获得良好的性能
CPU 内存结构中,一级二级缓存都是不可编程(完全不可控制)的存储设备。另一方面,CUDA 内存模型相对于 CPU 来说更为丰富,提出了多种可编程内存的类型:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
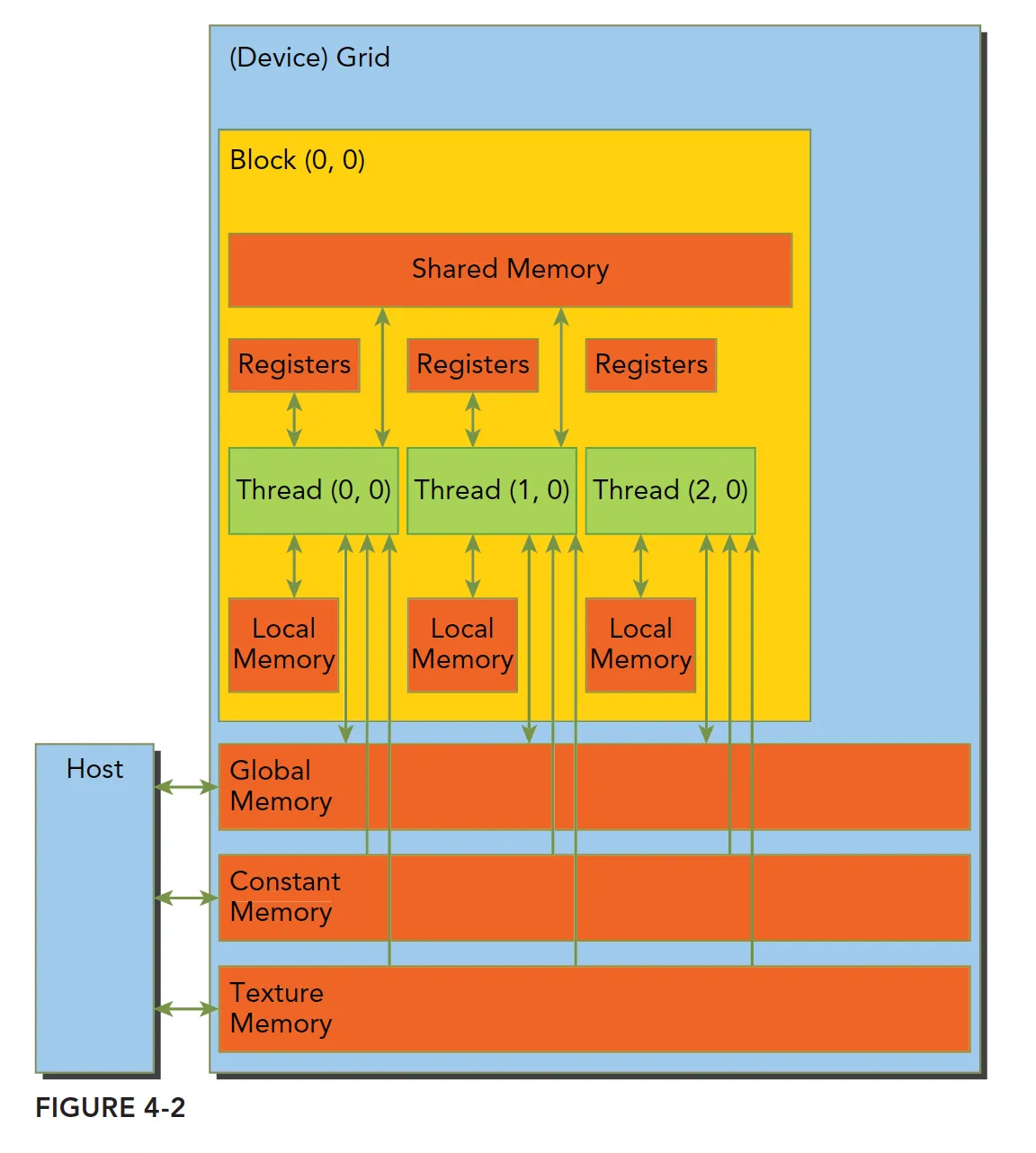
下图所示为这些内存空间的层次结构,每种都有不同的作用域、生命周期和缓存行为。一个核函数中的线程都有自己私有的本地内存。一个线程块有自己的共享内存,对同一线程块中所有线程都可见,其内容持续线程块的整个生命周期。所有线程都可以访问全局内存。所有线程都能访问的只读内存空间有:常量内存空间和纹理内存空间。全局内存、常量内存和纹理内存空间有不同的用途。纹理内存为各种数据布局提供了不同的寻址模式和滤波模式。对于一个应用程序来说, 全局内存、常量内存和纹理内存中的内容具有相同的生命周期。
# 1. 寄存器
寄存器无论是在 CPU 还是在 GPU 都是速度最快的内存空间,但是和 CPU 不同的是 GPU 的寄存器储量要多一些,而且当我们在核函数内不加修饰的声明一个变量,此变量就存储在寄存器中,但是 CPU 运行的程序有些不同,只有当前在计算的变量存储在寄存器中,其余在主存中,使用时传输至寄存器。在核函数声明的数组中,如果用于引用该数组的索引是常量且能在编译时确定,那么该数组也存储在寄存器中。
寄存器变量对于每个线程来说都是私有的,一个核函数通常使用寄存器来保存需要频繁访问的线程私有变量。寄存器变量与核函数的生命周期相同。一旦核函数执行完毕,就不能对寄存器变量进行访问了。
寄存器是 SM 中的稀缺资源,Fermi 架构中每个线程最多 63 个寄存器。Kepler 结构扩展到 255 个 寄存器,一个线程如果使用更少的寄存器,那么就会有更多的常驻线程块,SM 上并发的线程块越多,效率越高,性能和使用率也就越高。
那么问题就来了,如果一个线程里面的变量太多,以至于寄存器完全不够呢?这时候寄存器发生溢出,本地内存就会过来帮忙存储多出来的变量,这种情况会对效率产生非常负面的影响,所以,不到万不得已,一定要避免此种情况发生。
为了避免寄存器溢出,可以在核函数的代码中配置额外的信息来辅助编译器优化,比如:
| |
这里面在核函数定义前加了一个 关键字 lauch_bounds ,然后它后面对应了两个变量:
- maxThreadaPerBlock:线程块内包含的最大线程数,线程块由核函数来启动
- minBlocksPerMultiprocessor:可选参数,每个 SM 中预期的最小的常驻内存块参数。注意,对于一定的核函数,优化的启动边界会因为不同的结构而不同 也可以在编译选项中加入 -maxrregcount=32 来指定每个线程使用的最大寄存器数。
# 2. 本地内存
核函数中符合存储在寄存器中但不能进入被该核函数分配的寄存器空间中的变量将溢出到本地内存中。编译器可能存放到本地内存中的变量有:
- 在编译时使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地结构体或数组
- 任何不满足核函数寄存器限定条件的变量
本地内存实质上是和全局内存一样在同一块存储区域当中的,其访问特点——高延迟,低带宽。对于计算能力 2.0 以上的设备,本地内存存储在每个 SM 的一级缓存,或者设备的二级缓存上。
# 3. 共享内存
在核函数中使用 __shared__ 修饰符修饰的变量存放在共享内存中。
因为共享内存是片上内存,所以与本地内存或全局内存相比,它具有更高的带宽和更低的延迟。它的使用类似于 CPU 一级缓存,但它是可编程的。
每一个 SM 都有一定数量的由线程块分配的共享内存。因此,必须非常小心不要过度使用共享内存,否则将在不经意间限制活跃线程束的数量。
共享内存在核函数的范围内声明,其生命周期伴随着整个线程块。当一个线程块执行结束后,其分配的共享内存将被释放并重新分配给其他线程块。
共享内存是线程之间相互通信的基本方式。因为共享内存是块内线程可见的,所以就有竞争问题的存在,也可以通过共享内存进行通信,当然,为了避免内存竞争,可以使用同步语句:
| |
此语句相当于在线程块执行时各个线程的一个障碍点,当块内所有线程都执行到本障碍点的时候才能进行下一步的计算,这样可以设计出避免内存竞争的共享内存使用程序。但是,该语句频繁使用会影响内核执行效率。SM 中的一级缓存和共享内存都使用 64KB 的片上内存,它通过静态划分,但在运行时可以通过如下指令进行动态配置:
| |
这个函数在每个核函数的基础上配置了片上内存划分,为 func 指定的核函数设置了配置。支持的缓存配置如下:
| |
Fermi 架构支持前三种,后面的设备都支持。
# 4. 常量内存
常量内存驻留在设备内存中,每个 SM 都有专用的常量内存缓存,常量内存使用 __constant__ 修饰符修饰。
常量变量必须在全局空间内和所有核函数之外进行声明。对于所有计算能力的设备,都只可以声明 64kB 的常量内存,常量内存是静态声明的,并对同一编译单元中的所有核函数可见。
核函数只能从常量内存中读取数据(只读)。因此,常量内存必须在主机端使用下面的函数来初始化:
| |
这个函数将 count 个字节从 src 指向的内存复制到 symbol 指向的内存中,这个变量存放在设备的全局内存或常量内存中。在大多数情况下这个函数是同步的。
线程束中的所有线程从相同的内存地址中读取数据时,常量内存表现最好。举个例子,数学公式中的系数就是一个很好的使用常量内存的例子,因为一个线程束中所有的线程使用相同的系数来对不同数据进行相同的计算。如果线程束里每个线程都从不同的地址空间读取数据,并且只读一次,那么常量内存中就不是最佳选择,因为每从一个常量内存中读取一次数据,都会广播给线程束里的所有线程。
# 5. 纹理内存
纹理内存驻留在设备内存中,并在每个 SM 的只读缓存中缓存。纹理内存是一种通过指定的只读缓存访问的全局内存。只读缓存包括硬件滤波的支持,它可以将浮点插入作为读过程的一部分来执行。纹理内存是对二维空间局部性的优化所以线程束里使用纹理内存访问二维数据的线程可以达到最优性能。对于一些应用程序来说,这是理想的内存,并由于缓存和滤波硬件的支持所以有较好的性能优势。然而对于另一些应用程序来说,与全局内存相比,使用纹理内存更慢。
总的来说纹理内存设计目的应该是为了 GPU 本职工作显示设计的,但是对于某些特定的程序可能效果更好,比如需要滤波的程序,可以直接通过硬件完成。
# 6. 全局内存
全局内存是 GPU 中最大、延迟最高并且最常使用的内存。 global 指的是其作用域和生命周期。它的声明可以在任何 SM 设备上被访问到,并且贯穿应用程序的整个生命周期。一个全局内存变量可以被静态声明或动态声明。可以使用 __device__ 修饰符在设备代码中静态地声明一个变量。
默认通过 cudaMalloc 声明的所有在 GPU 上访问的内存都是全局内存,也就是没有对内存进行任何优化。因为全局内存的性质,当有多个核函数同时执行的时候,如果使用到了同一全局变量,应注意内存竞争。
全局内存访问是对齐,也就是一次要读取指定大小 $(32,64,128)$ 整数倍字节的内存,所以当线程束执行内存加载/存储时,需要满足的传输数量通常取决与以下两个因素:
- 跨线程的内存地址分布
- 内存事务的对齐方式
在一般情况下,用来满足内存请求的事务越多,未使用的字节被传输回的可能性就越高,这就造成了数据吞吐率的降低。
对于一个给定的线程束内存请求,事务数量和数据吞吐率是由设备的计算能力来确定的。对于计算能力为 1.0 和 1.1 的设备,全局内存访问的要求是非常严格的。对于计算能力高于 1.1 的设备,由于内存事务被缓存,所以要求较为宽松。缓存的内存事务利用数据局部性来提高数据吞吐率。
# 7. GPU 缓存
与 CPU 缓存类似, GPU 缓存是不可编程的内存。在 GPU 上有 4 种缓存:
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个 SM 都有一个一级缓存,所有的 SM 共享一个二级缓存。一级和二级缓存都被用来在存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。对 Fermi GPU 和 Kepler K40 或其后发布的 GPU 来说,CUDA 允许我们配置读操作的数据是使用一级和二级缓存,还是只使用二级缓存。
在 CPU 上,内存的加载和存储都可以被缓存。但是,在 GPU 上只有内存加载操作可以被缓存,内存存储操作不能被缓存。
每个 SM 也有一个只读常量缓存和只读纹理缓存,它们用于在设备内存中提高来自于各自内存空间内的读取性能。
# 8. CUDA 变量声明总结
用表格进行总结:
| 修饰符 | 变量名 | 存储器 | 作用域 | 生命周期 |
|---|---|---|---|---|
| 无 | float var | 寄存器 | 线程 | 线程 |
| 无 | float var[100] | 本地 | 线程 | 线程 |
| __shared__ | float var* | 共享内存 | 块 | 块 |
| __device__ | float var* | 全局内存 | 全局 | 应用程序 |
| __constant__ | float var* | 常量内存 | 全局 | 应用程序 |
设备存储器的重要特征:
| 存储器 | 片上/片外 | 缓存 | 存取 | 范围 | 生命周期 |
|---|---|---|---|---|---|
| 寄存器 | 片上 | n/a | R/W | 一个线程 | 线程 |
| 本地 | 片外 | 1.0 以上有 | R/W | 一个线程 | 线程 |
| 共享 | 片上 | n/a | R/W | 块内所有线程 | 块 |
| 全局 | 片外 | 1.0 以上有 | R/W | 所有线程+主机 | 主机配置 |
| 常量 | 片外 | 有 | R | 所有线程+主机 | 主机配置 |
| 纹理 | 片外 | 有 | R | 所有线程+主机 | 主机配置 |
# 9. 静态全局内存
CPU 内存有动态分配和静态分配两种类型,从内存位置来说,动态分配在堆上进行,静态分配在站上进行,在代码上的表现是一个需要 new,malloc 等类似的函数动态分配空间,并用 delete 和 free 来释放。在 CUDA 中也有类似的动态静态之分,需要 cudaMalloc 的就是动态分配,静态分配与动态分配相同是,也需要显式的将内存 copy 到设备端。下面代码是一个静态分配的例子:
| |
运行结果为:
| |
唯一要注意的就是这一句:
| |
设备上的变量定义和主机变量定义的不同,设备变量在代码中定义的时候其实就是一个指针,这个指针指向何处,主机端是不知道的,指向的内容也不知道,想知道指向的内容,唯一的办法还是通过显式的办法即 cudaMemcpyToSymbol 传输过来。
此外还需要注意的是:
- 在主机端,devData 只是一个标识符,不是设备全局内存的变量地址
- 在核函数中,devData 就是一个全局内存中的变量。主机代码不能直接访问设备变量,设备也不能访问主机变量,这就是 CUDA 编程与 CPU 多核最大的不同之处
一方面,是无法使用 cudaMemcpy 来给静态变量赋值的,除非:
| |
另一方面,主机端不可以对设备变量进行取地址操作,该操作是非法的。想要得到 devData 的地址可以用下面方法:
| |
当然也有一个例外,可以直接从主机引用 GPU 内存——CUDA 固定内存。
CUDA 运行时 API 能访问主机和设备变量,但这取决于你给正确的函数是否提供了正确的参数,使用运行时 API ,如果参数填错,尤其是主机和设备上的指针,结果是无法预测的。
# 参考资料
[1] CUDA C 编程权威指南,机械工业出版社,(美)程润伟(John Cheng) 等著