
大多数设备端数据访问都是从全局内存开始的,并且多数 GPU 应用程序容易受内存带宽的限制。因此,最大限度地利用全局内存带宽是调控核函数性能的基本。如果不能正确地调控全局内存的使用,其他优化方案很可能也收效甚微。
为了在读写数据时达到最佳的性能,内存访问操作必须满足一定的条件。CUDA 执行模型的显著特征之一就是指令必须以线程束为单位进行发布和执行。存储操作也是同样。在执行内存指令时,线程束中的每个线程都提供了一个正在加载或存储的内存地址。在线程束的 32 个线程中,每个线程都提出了一个包含请求地址的单一内存访问请求,它并由一个或多个设备内存传输提供服务。根据线程束中内存地址的分布,内存访问可以被分成不同的模式。
# 一、对齐与合并访问
全局内存通过缓存实现加载和存储的过程如下图所示:
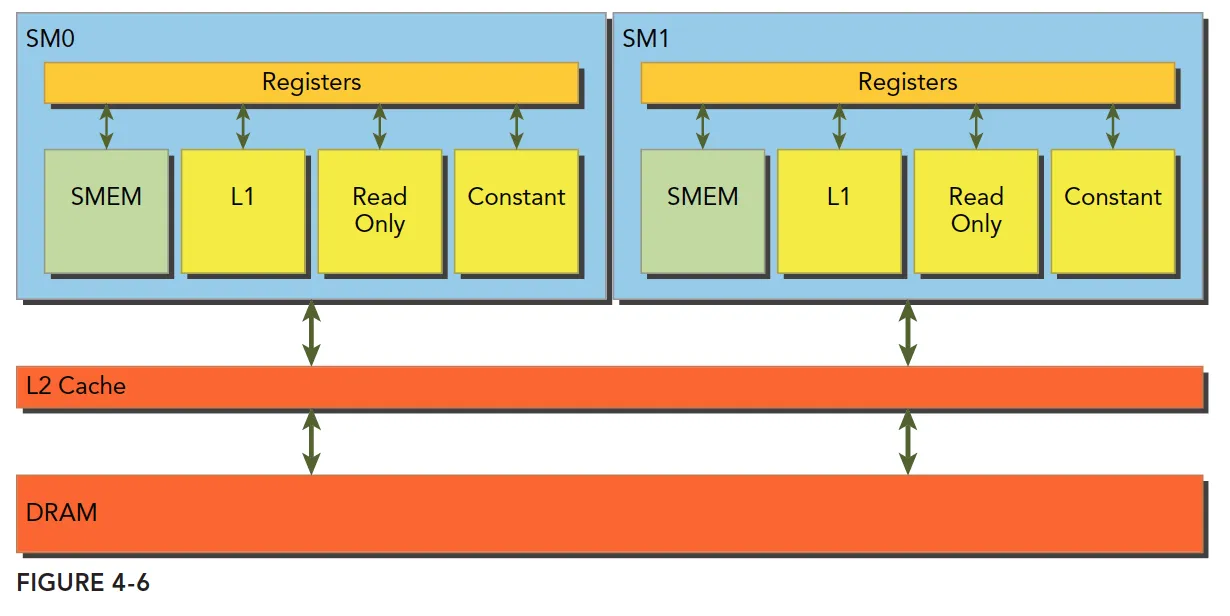
全局内存是一个逻辑内存空间,用户可以通过核函数访问它。所有应用程序数据最初存在于 DRAM 上,即物理设备内存中。核函数的内存请求通常是在 DRAM 设备和片上内存间以 128 字节或 32 字节内存事务来实现。
所有对全局内存的访问都会通过二级缓存,也有许多访问会通过一级缓存,这取决于访问类型和 GPU 架构。如果这两级缓存都被用到,那么内存访问是由一个 128 字节的内存事务实现的。如果只使用二级缓存,那么这个内存访问是由一个 32 字节的内存事务来实现的。对全局内存缓存其架构,如果允许使用一级缓存,那么可以在编译时选择启用或禁用一级缓存。
一行一级缓存是 128 字节,它映射到设备内存中一个 128 字节 的对齐段。如果线程束中的每个线程请求一个 4 字节的值,那么每次请求就会获取 128 字节的数据,这恰好与缓存行和设备内存段的大小相契合。
因此在优化应用程序时,需要注意设备内存访问的两个特性:
- 对齐内存访问
- 合并内存访问
我们把一次内存请求:也就是从核函数发起请求,到硬件响应返回数据这个过程称为一个内存事务(加载和存储都行)。
当一个内存事务的首个访问地址是缓存粒度(32 或 128 字节)的偶数倍的时候:比如二级缓存 32 字节的偶数倍 64,128 字节的偶数倍 256 的时候,这个时候被称为对齐内存访问,非对齐访问就是除上述的其他情况,非对齐的内存访问会造成带宽浪费。
当一个线程束内的线程访问的内存都在一个内存块里的时候,就会出现合并访问。
对齐合并访问的状态是理想化的,也是最高速的访问方式,当线程束内的所有线程访问的数据在一个内存块,并且数据是从内存块的首地址开始被需要的,那么对齐合并访问出现了。为了最大化全局内存访问的理想状态,尽量将线程束访问内存组织成对齐合并的方式,这样的效率是最高的。下面看一个例子。
一个线程束加载数据,使用一级缓存,并且这个事务所请求的所有数据在一个 128 字节的对齐的地址段上,如下图所示:
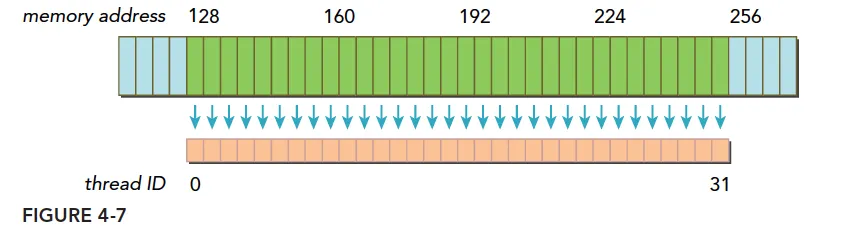
上面蓝色表示全局内存,下面橙色是线程束要的数据,绿色就是对齐的地址段。
而如果一个事务加载的数据分布在不一个对齐的地址段上,就会有以下两种情况:
- 连续的,但是不在一个对齐的段上,比如,请求访问的数据分布在内存地址 1
128 ,那么 0127 和 128~255 这两段数据要传递两次到 SM 。 - 不连续的,也不在一个对齐的段上,比如,请求访问的数据分布在内存地址 0
63 和 128191 上,明显这也需要两次加载。
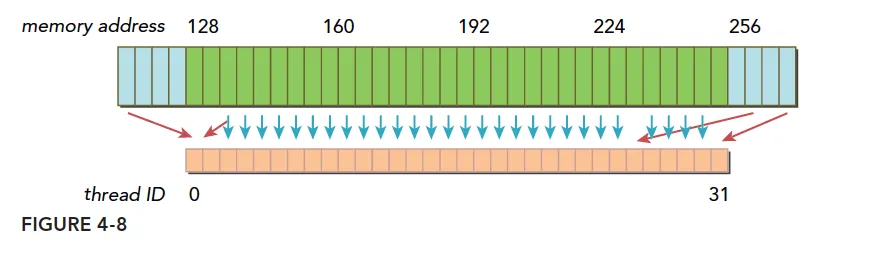
上图就是典型的一个线程束,数据分散开了,thread 0 的请求在 128 之前,后面还有请求在 256 之后,所以需要三个内存事务,而利用率,也就是从主存取回来的数据被使用到的比例,只有 $\frac{128}{128 \times 3}$ 的比例。这个比例低会造成带宽的浪费,最极端的表现,就是如果每个线程的请求都在不同的段,也就是一个 128 字节的事务只有 1 个字节是有用的,那么利用率只有 $\frac{1}{128}$ 。
这里总结一下内存事务的优化关键:用最少的事务次数满足最多的内存请求。事务数量和吞吐量的需求随设备的计算能力变化。
# 二、全局内存读取
在 SM 中,数据通过以下 3 种缓存 / 缓冲路径进行传输,具体使用何种方式取决于引用了哪种类型的设备内存:
- 一级和二级缓存
- 常量缓存
- 只读缓存
一 / 二级缓存是默认路径。想要通过其它两种路径传输数据需要应用程序显式说明,但想要提升性能还要取决于使用地访问模式。全局内存加载操作是否会通过一级缓存取决于两个因素:
- 设备的计算能力:比较老的设备可能没有一级缓存
- 编译器选项
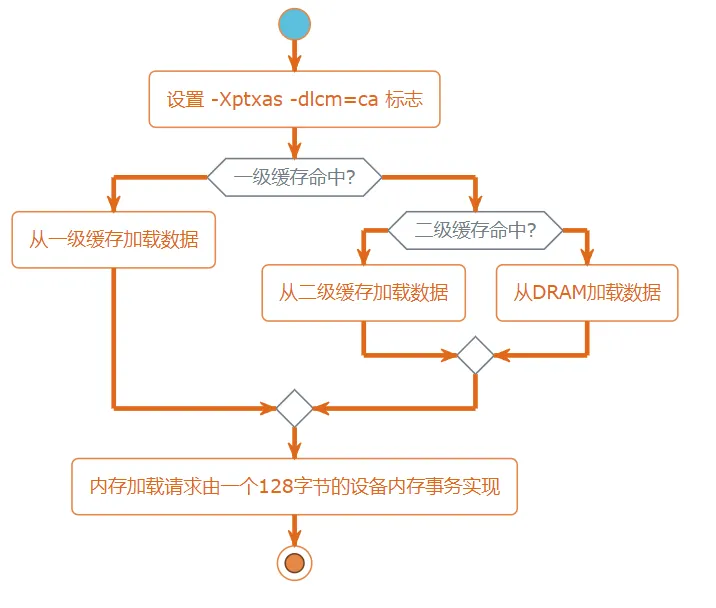
在 Fermi GPU 和 Kepler K40 及以后的 GPU (计算能力为 3.5 及以上)中,可以通过编译器标志启用或禁用全局内存负载的一级缓存。默认情况下,在 Fermi 设备上对于全局内存加载可以使用一级缓存,在 K40 及以上 GPU 中禁用。以下标志通知编译器禁用一级缓存:
| |
如果一级缓存被禁用,所有对全局内存的加载请求将直接进入到二级缓存;如果二级缓存缺失,则由 DRAM 完成请求。每一次内存事务可由一个、两个或四个部分执行,每个部分有 32 个字节。一级缓存也可以使用下列标识符直接启用:
| |
设置这个标志后,全局内存加载请求首先尝试通过一级缓存。如果一级缓存缺失,该请求转向二级缓存。如果二级缓存缺失,则请求由 DRAM 完成。在这种模式下,一个内存加载请求由一个 128 字节的设备内存事务实现。
在 Kepler K10、K20 和 K20X GPU 中一级缓存不用来缓存全局内存加载。一级缓存专门用于缓存寄存器溢出到本地内存中的数据。
内存加载可以分为两类:
- 缓存加载
- 没有缓存的加载
内存访问有以下特点:
- 是否使用缓存:一级缓存是否介入加载过程
- 对齐与非对齐的:如果访问的第一个地址是 32 的倍数
- 合并与非合并,访问连续数据块则是合并的
# 1. 缓存加载
下面是使用一级缓存的加载过程
- 对齐合并的访问,总线利用率 $100\%$

- 对齐的,但是不是连续的,每个线程访问的数据都在一个块内,但是位置是交叉的,总线利用率 $100\%$

- 连续非对齐的,线程束请求一个连续的非对齐的,32 个 4 字节数据,那么会出现,数据横跨两个块,但是没有对齐,当启用一级缓存的时候,就要两个 128 字节的事务来完成,总线利用率为 $50\%$

- 线程束所有线程请求同一个地址,那么肯定落在一个缓存行范围内,那么如果按照请求的是 4 字节数据来说,总线利用率是 $\frac{4}{128}=3.125\% $

- 比较坏的情况,前面提到过最坏的,就是每个线程束内的线程请求的都是不同的缓存行内,这里比较坏的情况就是,所有数据分布在 $N$ 个缓存行,其中 $1\leq N \leq 32$ ,那么请求 32 个 4 字节的数据,就需要 $N$ 个事务来完成,总线利用率也是 $\frac{1}{N}$

CPU 和 GPU 的一级缓存有显著的差异, GPU 的一级缓存可以通过编译选项等控制,CPU 不可以,而且 CPU 的一级缓存是的替换算法是有使用频率和时间局部性的, GPU 则没有。
# 2. 没有缓存的加载
没有缓存的加载是指的没有通过一级缓存,二级缓存则是不得不经过的。
当不使用一级缓存的时候,内存事务的粒度变为 32 字节,更细粒度的加载可以为非对齐或非合并的内存访问带来更好的总线利用率。
- 对齐合并访问 128 字节,不用说,还是最理想的情况,使用 4 个段,总线利用率 $100\%$

- 对齐不连续访问 128 字节,都在四个段内,且互不相同,这样的总线利用率也是 $100\%$

- 连续不对齐,一个段 32 字节,所以,一个连续的 128 字节的请求,即使不对齐,最多也不会超过五个段,总线利用率至少为 $\frac{4}{5}=80\%$

- 所有线程访问一个 4 字节的数据,那么此时的总线利用率是 $\frac{4}{32} = 12.5\%$ ,在这种情况下,非缓存加载性能也是优于缓存加载的性能。

- 最坏的情况:所有目标数据分散在内存的各个角落,那么需要 $N$ 个内存段,由于请求的 128 个字节最多落在 $N$ 个 32 字节的内存分段内而不是 $N$ 个 128 字节的缓存行内,所以相比于缓存加载,即便是最坏的情况也有所改善。需要注意这里比较的前提是$N$ 不变,然而在实际情况下,当使用大粒度的缓存行时,$N$ 有可能会减少。

# 3. 只读缓存
只读缓存最初是预留给纹理内存加载用的。对计算能力为 3.5 及以上的 GPU 来说,只读缓存也支持使用全局内存加载代替一级缓存。
只读缓存的加载粒度是 32 个字节。通常,对分散读取来说,这些更细粒度的加载要优于一级缓存。
有两种方式可以指导内存通过只读缓存进行读取:
- 使用函数 __ldg
- 在间接引用的指针上使用修饰符
例如:
| |
然后就能强制使用只读缓存了。
也可以将常量 restrict 修饰符应用到指针上。这些修饰符帮助 nvcc 编译器识别无别名指针(即专门用来访问特定数组的指针)。nvcc 将自动通过只读缓存指导无别名指针的加载。
| |
# 三、全局内存写入
内存的存储操作相对简单。一级缓存不能用在 Fermi 或 Kepler GPU 上进行存储操作,在发送到设备内存之间存储操作只通过二级缓存。存储操作在 32 个字节段的粒度上被执行。内存事务可以同时被分为一段、两段或四段。例如,如果两个地址同属于一个 128 字节区域,但是不属于一个对齐的 64 字节区域,则会执行一个四段事务(也就是说,执行一个四段事务比执行两个一段事务效果更好)。
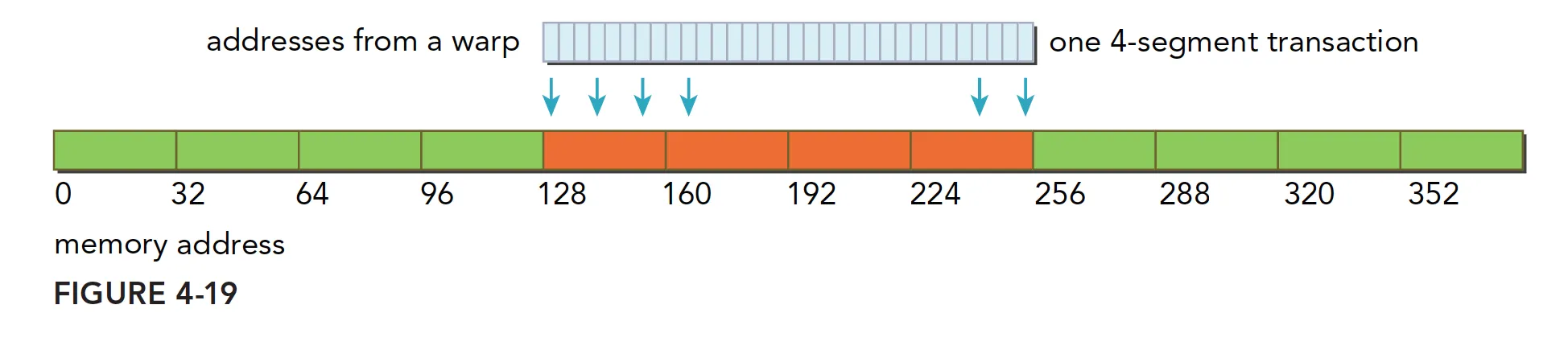
- 对齐的,访问一个连续的 128 字节范围。存储操作使用一个四段事务完成:
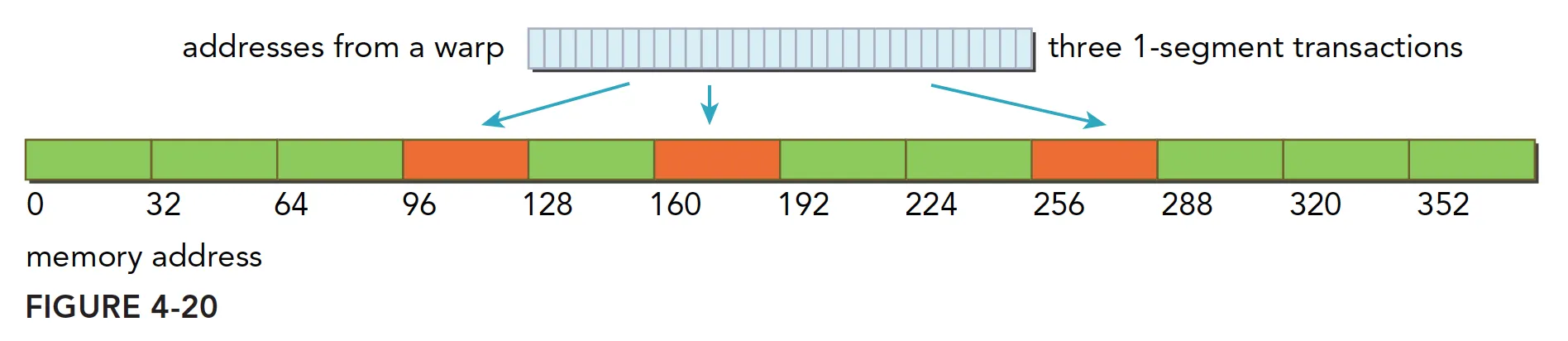
- 分散在一个 192 字节的范围内,不连续,使用 3 个一段事务完成:
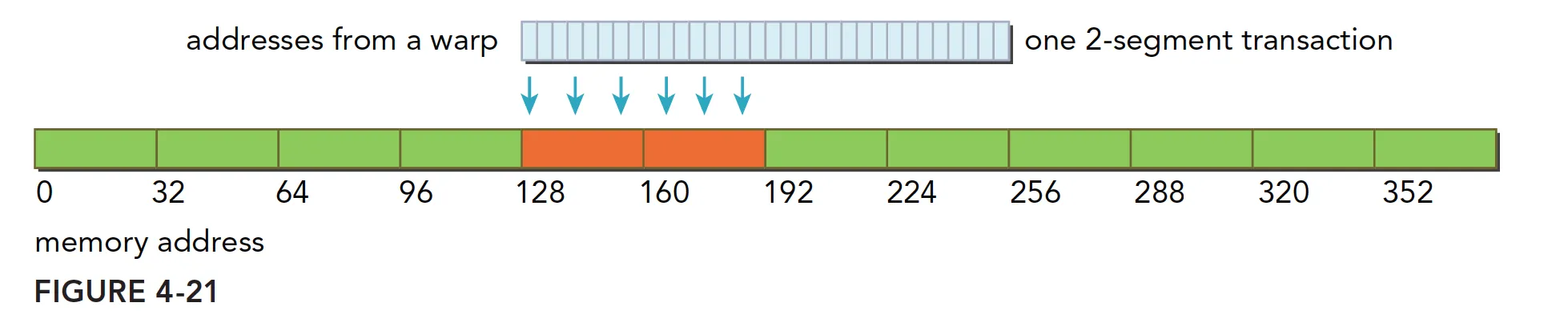
- 对齐的,在一个 64 字节的范围内,使用一个两段事务完成:
- 非对齐写入示例与读取情况类似,且更简单,因为始终不经过一级缓存,这里就略过了。
# 四、结构体数组与数组结构体
数组结构体(AoS)和结构体数组(SoA)是 C 语言中常见的两种数组组织方式。当存储结构化数据集时,它们代表了可以采用的两种强大的数据组织方式(结构体和数组)。
下面是存储成对的浮点数据数据集的例子。首先,考虑这些成对数据元素集如何使用 AoS 方法进行存储。如下定义一个结构体,命名为 innerStruct :
| |
然后,按照下面的方法定义这些结构体数组。这是利用 AoS 方式来组织数据的。它存储的是空间上相邻的数据,这在 CPU 上会有良好的缓存局部性。
| |
接下来,考虑使用 SoA 方法来存储数据:
| |
这里,在原结构体中每个字段的所有值都被分到各自的数组中。这不仅能将相邻数据点紧密存储起来,也能将跨数组的独立数据点存储起来。可以使用如下结构体定义一个变量:
| |
下图说明了 AoS 和 SoA 方法的内存布局。用 AoS 模式在 GPU 上存储示例数据并执行一个只有 $x$ 字段的应用程序,将导致 $50\%$ 的带宽损失,因为 $y$ 值在每 32 个字节段或 128 个字节缓存行上隐式地被加载。 AoS 格式也在不需要的 $y$ 值上浪费了二级缓存空间。
用 SoA 模式存储数据充分利用了 GPU 的内存带宽。由于没有相同字段元素的交叉存取, GPU 上的 SoA 布局提供了合并内存访问,并且可以对全局内存实现更高效的利用。
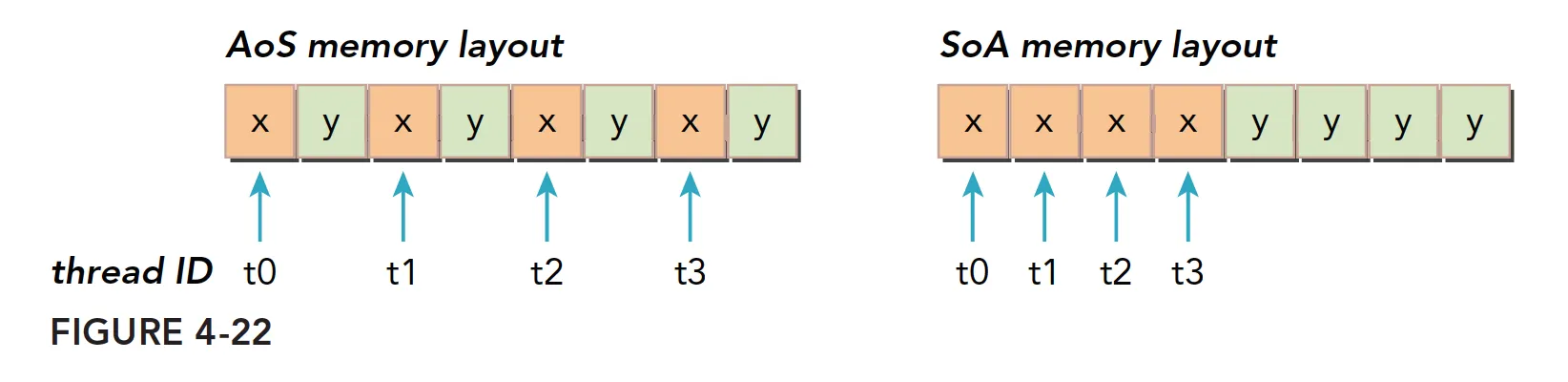
当 32 个线程同时访问的时候, SoA 的访问就是连续的,而 AoS 则是不连续的。
对比 AoS 和 SoA 的内存布局,我们能得到下面结论:
- 并行编程范式,尤其是 SIMD(单指令多数据)对 SoA 更友好。 CUDA 中普遍倾向于 SoA 因为这种内存访问可以有效地合并。
# 五、性能调整
优化设备内存带宽利用率有两个目标:
- 对齐及合并内存访问,以减少带宽的浪费
- 足够的并发内存操作,以隐藏内存延迟
实现并发内存访问量最大化是通过以下方式得到的:
- 增加每个线程中执行独立内存操作的数量
- 对核函数启动的执行配置进行试验,已充分体现每个 SM 的并行性
按照这个思路对程序进行优化,则有两种方法:展开技术和增大并行性。
# 1. 展开技术
包含了内存操作的展开循环增加了更独立的内存操作。考虑如下 readOffsetUnroll4 核函数,每个线程都执行 4 个独立的内存操作。因为每个加载过程都是独立的,所以可以调用更多的并发内存访问:
| |
启用一级缓存编译选项:
| |
结果表明,展开技术对性能有非常好的影响,甚至比地址对齐还要好。对于 I/O 密集型的核函数,充分说明内存访问并行有很高的优先级。
# 2. 增大并行性
可以通过调整块的大小来实现并行性调整:
- 线程块最内层维度的大小对性能起着关键的作用
- 在所有其它情况下,线程块的数量越多,一般性能越高。因此,增大并行性仍然是性能优化的一个重要因素。
# 参考资料
[1] CUDA C 编程权威指南,机械工业出版社,(美)程润伟(John Cheng) 等著