
# 1. SVE 介绍
继固定 128 位向量长度指令集的 Neon 架构扩展之后,Arm 设计了可伸缩向量扩展 (SVE) 作为 AArch64 的下一代 SIMD 扩展。SVE 引入可伸缩概念,允许灵活的向量长度实现,并在 CPU 实现中提供一系列可能的值。向量长度可以从最小 128 位到最大 2048 位不等,以 128 位为增量。SVE 设计保证相同的应用程序可以在支持 SVE 的不同实现上运行,而无需重新编译代码。SVE 提高了该架构对高性能计算 (HPC) 和机器学习 (ML) 应用程序的适用性,这些应用程序需要非常大量的数据处理。SVE2 是 SVE 和 Neon 的超集。SVE2 允许在数据级并行中使用更多功能域。SVE2 继承了 SVE 的概念、向量寄存器和操作原理。SVE 和 SVE2 定义了 32 个可伸缩向量寄存器。芯片合作伙伴可以选择合适的向量长度设计实现,硬件可在 128 位到 2048 位之间(以 128 位为增量)变化。SVE 和 SVE2 的优势在于,只有一个向量指令集使用可伸缩变量。
SVE 设计理念使开发人员能够编写和构建一次软件,然后在具有各种 SVE 向量长度实现的不同 AArch64 硬件上运行相同的二进制文件。二进制文件的可移植性意味着开发人员不必知道其系统的向量长度实现。消除了重建二进制文件的需求,使软件更容易移植。除了可伸缩向量之外,SVE 和 SVE2 还包括:
- per-lane predication
- Gather Load/Scatter Store
- 推测性向量化
这些特性有助于在处理大型数据集时对循环进行向量化和优化。
SVE2 和 SVE 的主要区别在于指令集的功能覆盖范围。SVE 专为 HPC 和 ML 应用而设计。SVE2 扩展了 SVE 指令集,使其能够加速 HPC 和 ML 以外领域的数据处理。SVE2 指令集还可以加速以下应用中使用的常见算法:
- 计算机视觉
- 多媒体
- LTE 基处理
- 基因组学
- 内存数据库
- Web 服务
- 通用软件
SVE 和 SVE2 都支持收集和处理大量数据。SVE 和 SVE2 不是 Neon 指令集的扩展。相反,SVE 和 SVE2 经过重新设计,以提供比 Neon 更好的数据并行性。但是,SVE 和 SVE2 的硬件逻辑覆盖了 Neon 硬件的实现。当微架构支持 SVE 或 SVE2 时,它也支持 Neon。要使用 SVE 和 SVE2,在该微架构上运行的软件必须首先支持 Neon。
# 2. SVE 架构基础
本节介绍 SVE 和 SVE2 共享的基本架构特性。与 SVE 一样,SVE2 也基于可扩展向量。除了 Neon 提供的现有寄存器库之外,SVE 和 SVE2 还添加了以下寄存器:
- 32 个可伸缩向量寄存器,
Z0-Z31 - 16 个可伸缩 Predicate 寄存器,
P0-P15- 1 个 首故障 Predicate 寄存器,
FFR
- 1 个 首故障 Predicate 寄存器,
- 可伸缩向量系统控制寄存器,
ZCR_ELx
# 2.1 可伸缩向量寄存器
可伸缩向量寄存器 Z0-Z31 可以在微架构中实现为 128-2048 位。最低的 128 位与 Neon 的固定 128 位向量 V0-V31 共享。
下图显示了可伸缩向量寄存器 Z0-Z31:
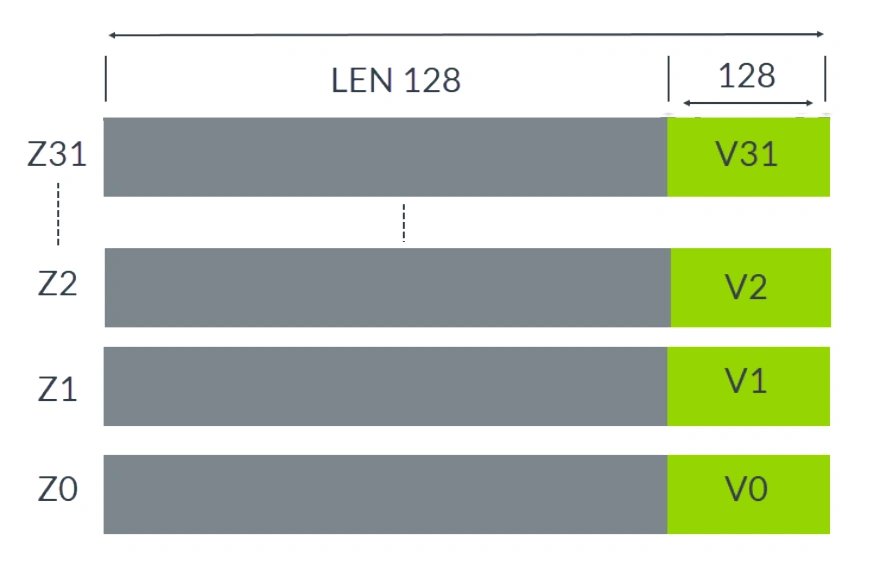
可伸缩向量寄存器 Z0-Z31
可伸缩向量:
- 可以容纳 64、32、16 和 8 位元素
- 支持整数、双精度、单精度和半精度浮点元素
- 可以针对每个异常级别(EL)配置向量长度
# 2.2 可伸缩 Predicate 寄存器
为了控制哪些活动元素参与运算,Predicate 寄存器(简称为 P 寄存器)在许多 SVE 指令中用作掩码,这也为向量运算提供了灵活性。下图显示了可伸缩 Predicate 寄存器 P0-P15 :
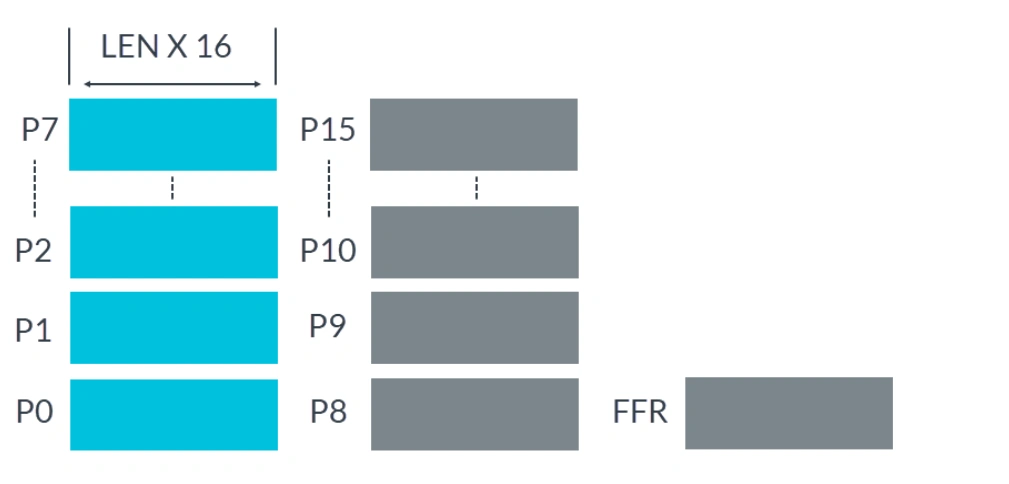
可伸缩 Predicate 寄存器 P0-P15
P 寄存器通常用作数据操作的位掩码:
- 每个 P 寄存器是 Z 寄存器长度的 1/8
P0-P7用于加载、存储和算术运算P8-P15用于循环管理- FFR 是一个特殊的 P 寄存器,由 first-fault vector load 指令和 store 指令设置,用于指示每个元素的加载和存储操作的成功情况。FFR 旨在支持推测性内存访问,这使得在许多情况下向量化更容易和更安全。
# 2.3 可伸缩向量系统控制寄存器
下图展示了可伸缩向量系统控制寄存器 ZCR_ELx :

可伸缩向量系统控制寄存器 ZCR_Elx
可伸缩向量系统控制寄存器指示 SVE 实现特性:
ZCR_Elx.LEN字段用于当前和较低异常级别的向量长度。- 大多数位当前保留供将来使用。
# 2.4 SVE 汇编语法
SVE 汇编语法格式由操作码、目标寄存器、P 寄存器(如果指令支持 Predicate 掩码)和输入操作数组成。以下指令示例将详细说明此格式。
示例 1:
| |
其中:
<Zt>是 Z 寄存器,Z0-Z31<Zt>.D 和<Zm>.D指定目标和操作数向量的元素类型,不需要指定元素的数量。<Pg>是 P 寄存器,P0-P15<Pg>/Z是对 P 寄存器归零。<Zm>指定 Gather Load 地址模式的偏移量。
示例 2:
| |
其中:
<Pg>/M是合并 P 寄存器。<Zdn>既是目标寄存器,也是输入操作数之一。指令语法在两个位置都显示<Zdn>,是为了方便起见。在汇编编码中,为了简化,它们只被编码一次。
示例 3:
| |
S是 P 寄存器条件标志NZCV的新解释。<Pg>控制 P 寄存器在示例操作中充当位掩码。
# 2.5 SVE 架构特性
SVE 包括以下关键架构特性:
- per-lane predication
为了允许对所选元素进行灵活的操作,SVE 引入了 16 个 P 寄存器, P0-P15 ,用于指示对向量活动通道的有效操作。例如:
| |
活动元素 Z0 和 Z1 相加并将结果放入 Z0 中,P0 指示操作数的哪些元素是活动的和非活动的。P0 后面的 M 表示 Merging ,表示将非活动元素合并,因此 Z0 的非活动元素在 ADD 操作后将保持其初始值。如果 P0 后面是 Z ,则非活动元素将被清零,目标寄存器的非活动元素将在操作后归零。
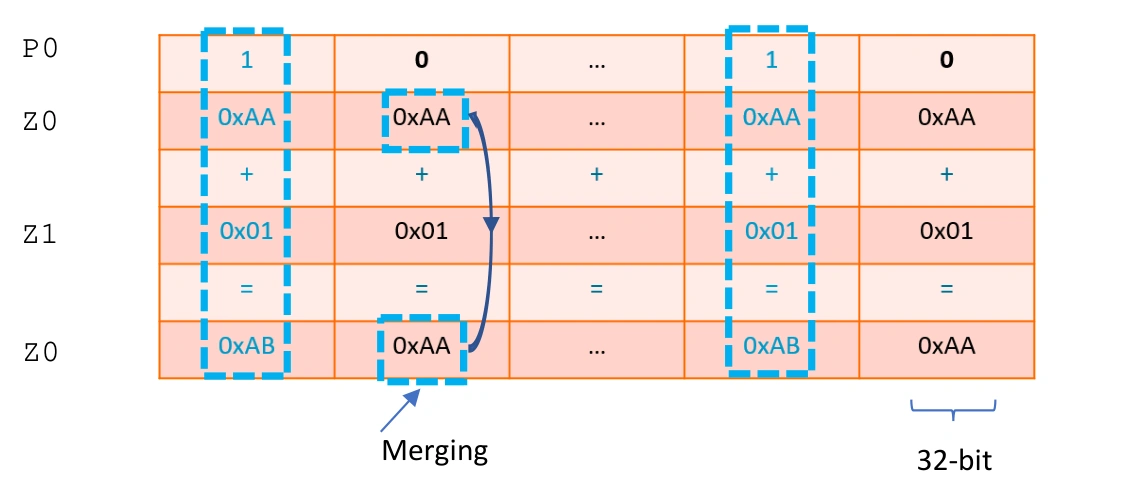
Per-lane predication merging
如果使用的是 \Z ,则非活动元素将被清零,目标寄存器的非活动元素将在操作后归零。例如
| |
表示将有符号整数 0xFF 复制到 Z0 的活动通道中,而非活动通道将被清零。

Per-lane predication zeroing
注释
并非所有指令都具有 Predicate 选项。此外,并非所有 Predicate 操作都同时具有合并和清零选项。您必须参考 AArch64 SVE Supplement 以了解每个指令的规范细节。
- Gather Load 和 Scatter Store
SVE 中的寻址模式允许将向量用作 Gather Load 和 Scatter Store 指令中的基地址和偏移量,这使得能够访问非连续的内存位置。例如:
| |
以下示例显示了加载操作 LD1SB Z0.S, P0/Z, [Z1.S] ,其中 P0 包含所有真元素,Z1 包含分散的地址。加载后,Z0.S 的每个元素的低位字节将用从分散内存位置获取的数据更新。
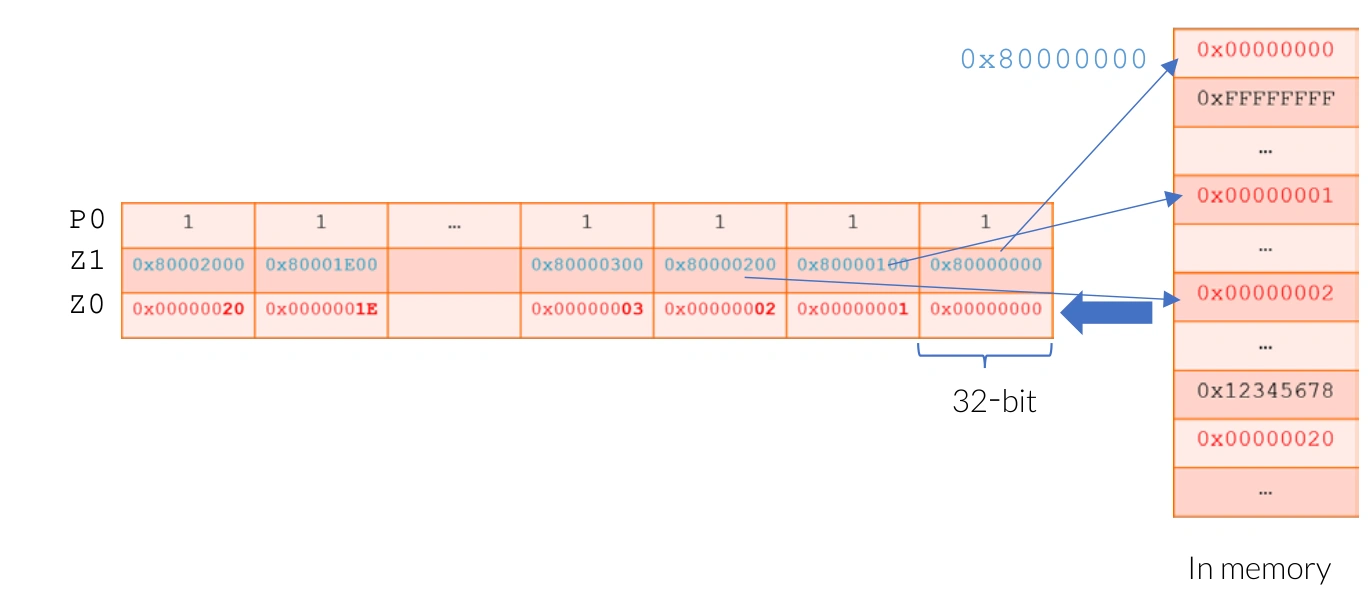
Gather-load 与 Scatter-store 示例
- P 寄存器驱动的循环控制和管理
作为 SVE 的一项关键特性,P 寄存器不仅可以灵活地控制向量运算的各个元素,还可以实现 P 寄存器驱动的循环控制。P 寄存器驱动的循环控制和管理使循环控制高效且灵活。此功能通过在 P 寄存器中注册活动和非活动元素索引,消除了处理部分向量的额外循环头和尾的开销。P 寄存器驱动的循环控制和管理意味着,在接下来的循环迭代中,只有活动元素才会执行预期的操作。例如:
| |
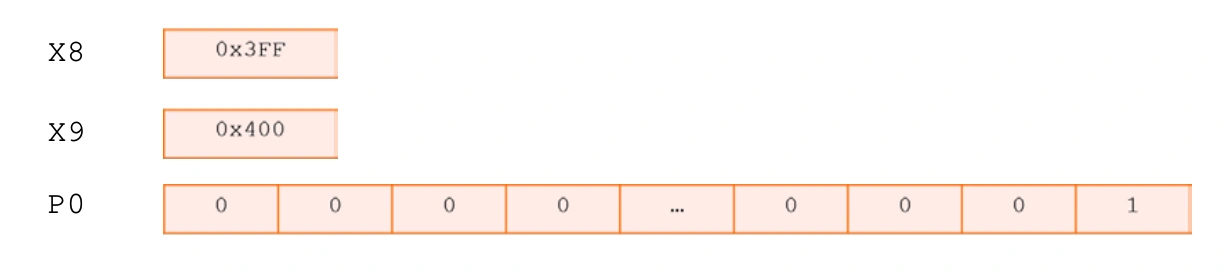
P 寄存器驱动的循环控制和管理示例
- 用于软件管理推测的向量分区
推测性加载可能会给传统向量的内存读取带来挑战,如果在读取过程中某些元素发生错误,则难以逆转加载操作并跟踪哪些元素加载失败。Neon 不允许推测性加载。为了允许对向量进行推测性加载(例如 LDRFF),SVE 引入了 first-fault vector load 指令。为了允许向量访问跨越无效页面,SVE 还引入了 FFR 寄存器。使用 first-fault vector load 指令加载到 SVE 向量时,FFR 寄存器会更新每个元素的加载成功或失败结果。当发生加载错误时,FFR 会立即注册相应的元素,将其余元素注册为 0 或 false,并且不会触发异常。通常,RDFFR 指令用于读取 FFR 状态。当第一个元素为假时,RDFFR 指令结束迭代。如果第一个元素为真,RDFFR 指令继续迭代。FFR 的长度与 P 向量相同。可以使用 SETFFR 指令初始化该值。以下示例使用 LDFF1D 从内存中读取数据,FFR 会相应地更新:
| |
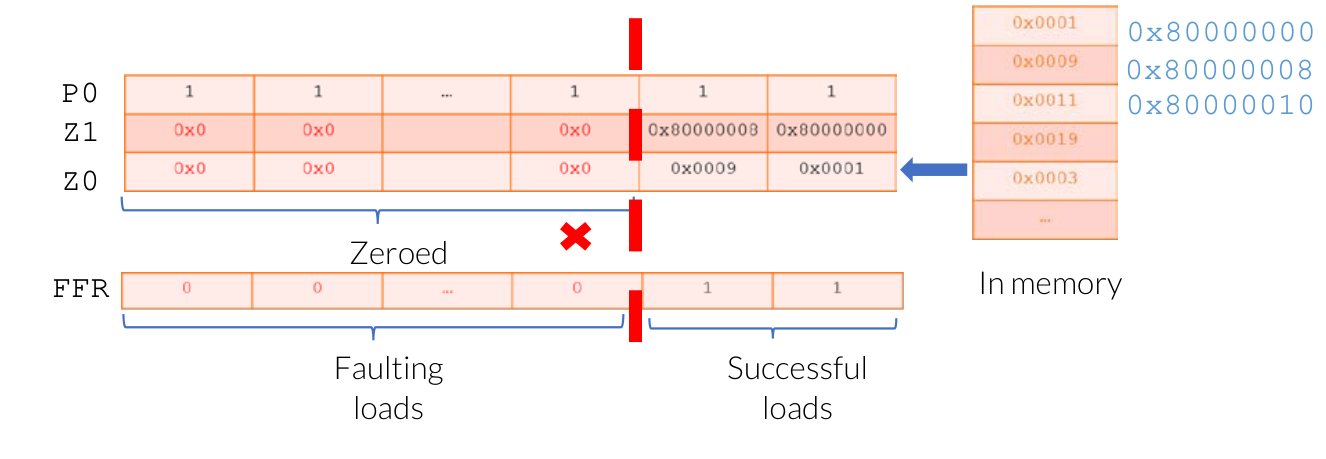
用于软件管理推测的向量分区示例
- 扩展的浮点和水平规约
为了允许在向量中进行高效的归约操作,并满足对精度的不同要求,SVE 增强了浮点和水平归约操作。这些指令可能具有顺序(从低到高)或基于树(成对)的浮点归约顺序,其中操作顺序可能会导致不同的舍入结果。这些操作需要在可重复性和性能之间进行权衡。例如:
| |
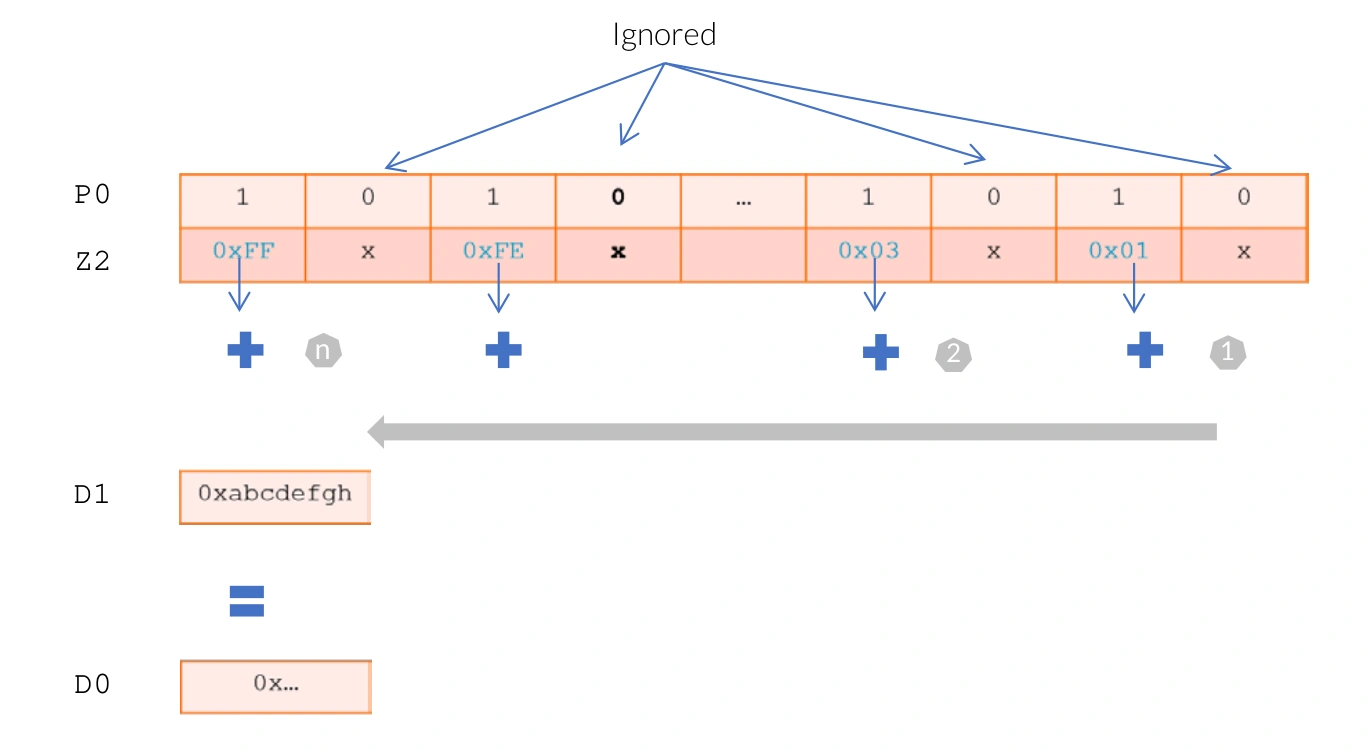
扩展的浮点和水平规约示例
# 3. SVE2 新增特性
本节介绍 SVE2 为 Arm AArch64 架构新增的特性。为了实现可伸缩的性能,SVE2 基于 SVE 构建,允许向量实现高达 2048 位。
在 SVE2 中,添加了许多复制 Neon 中现有指令的指令,包括:
- 转换后的 Neon 整数运算,例如,带符号绝对差累加 (SAB) 和带符号减半加法 (SHADD)。
- 转换后的 Neon 扩展、缩小和成对运算,例如,无符号长加法 - 底部 (UADDLB) 和无符号长加法 - 顶部 (UADDLT)。
元素处理顺序发生了变化。SVE2 对交错的偶数和奇数元素进行处理,而 Neon 对窄或宽操作的低半部分和高半部分元素进行处理。下图说明了 Neon 和 SVE2 处理之间的区别:
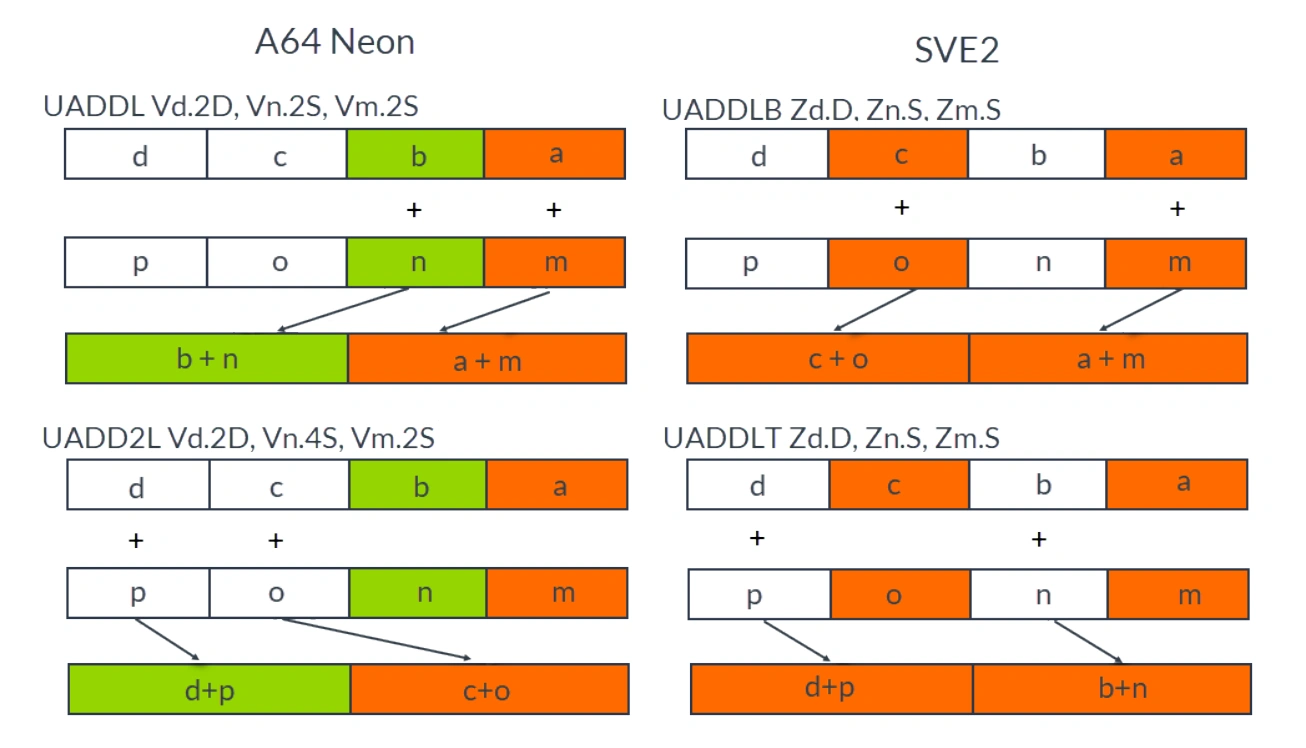
转换后的 Neon 窄或宽操作对比
- 复数操作,例如带旋转的复整数乘加 (CMLA)。
- 多精度运算,用于大整数运算和密码学,例如,带进位长加法 - 底部 (ADCLB)、带进位长加法 - 顶部 (ADCLT) 以及 SM4 加密和解密 (SM4E)。
为了向后兼容,最新架构中需要 Neon 和 VFP。虽然 SVE2 包含 SVE 和 Neon 的一些功能,但 SVE2 并不排除 Neon 在芯片上的存在。
SVE2 支持针对 HPC 市场以外的新兴应用进行优化,例如,在机器学习 (ML)(UDOT 指令)、计算机视觉(TBL 和 TBX 指令)、基带网络(CADD 和 CMLA 指令)、基因组学(BDEP 和 BEXT 指令)和服务器(MATCH 和 NMATCH 指令)中。
SVE2 增强了通用处理器大量数据操作的整体性能,而无需其他片外加速器。
# 4. 使用 SVE 编程
本节介绍支持 SVE2 应用程序开发的软件工具和库。本节还介绍了如何为支持 SVE2 的目标开发应用程序,在支持 SVE2 的硬件上运行该应用程序,以及在任何 Armv8-A 硬件上模拟该应用程序。
# 4.1 软件和库支持
要构建 SVE 或 SVE2 应用程序,你必须选择支持 SVE 和 SVE2 功能的编译器。
- GNU 工具 8.0+ 版本支持 SVE。
- Arm Compiler for Linux 18.0+ 版本支持 SVE,20.0+ 版本支持 SVE 和 SVE2。
- GNU 和 Arm Compiler for Linux 编译器都支持优化 C/C++/Fortran 代码。
- LLVM(开源 Clang)5 及更高版本包括对 SVE 的支持,9 及更高版本包括对 SVE2 的支持。要了解 LLVM 工具的每个版本支持哪些 SVE 或 SVE2 功能,请参阅 LLVM 工具链 SVE 支持页面 。
Arm Performance Libraries 针对数学例程进行了高度优化,可以链接到你的应用程序。Arm Performance Libraries 19.3+ 版本支持 SVE 的数学库。
Arm Compiler for Linux 是 Arm Allinea Studio 的一部分,包含 Arm C/C++ 编译器、Arm Fortran 编译器和 Arm Performance Libraries。
# 4.2 如何使用 SVE2 编程
编写或生成 SVE 和 SVE2 代码的方法有多种。在本小节中,我们将探讨其中的一些方法。
要编写或生成 SVE 和 SVE2 代码,你可以:
- 编写 SVE 汇编代码
- 使用 SVE 内部函数编程
- 自动向量化
- 使用 SVE 优化库
让我们更详细地了解这四种选择。
# 4.2.1 编写 SVE 汇编代码
你可以将 SVE 指令作为内联汇编编写到 C/C++ 代码中,或者作为完整的函数编写到汇编源代码中。例如:
| |
如果你混合使用高级语言和汇编语言编写的函数,则必须熟悉针对 SVE 更新的应用程序二进制接口 (ABI) 标准。Arm 架构过程调用标准 (AAPCS) 指定了数据类型和寄存器分配,并且与汇编编程最相关。AAPCS 要求:
Z0-Z7和P0-P3用于传递可伸缩向量参数和结果。Z8-Z15和P4-P15是被调用者保存的。- 所有其他向量寄存器(
Z16-Z31)都可能被被调用函数破坏,调用函数负责在需要时备份和恢复它们。
# 4.2.2 使用 SVE instruction 函数(Intrinsics)
SVE 内部函数是由编译器支持的函数,可以替换为相应的指令。程序员可以直接在 C 和 C++ 等高级语言中调用指令函数。SVE 的 ACLE(Arm C 语言扩展)定义了哪些 SVE 指令函数可用、它们的参数以及它们的功能。支持 ACLE 的编译器可以在编译期间将内部函数替换为映射的 SVE 指令。要使用 ACLE 内部函数,你必须包含头文件 arm_sve.h,其中包含可在 C/C++ 中使用的向量类型和指令函数(针对 SVE)列表。每种数据类型都描述了向量中元素的大小和数据类型:
svint8_t svuint8_tsvint16_t svuint16_t svfloat16_tsvint32_t svuint32_t svfloat32_tsvint64_t svuint64_t svfloat64_t
例如,svint64_t 表示 64 位有符号整数向量,svfloat16_t 表示半精度浮点数向量。
以下示例 C 代码已使用 SVE 内部函数进行了手动优化:
| |
包含 arm_sve.h 头文件的源代码可以使用 SVE 向量类型,就像数据类型可以用于变量声明和函数参数一样。要使用 Arm C/C++ 编译器编译代码并以支持 SVE 的 Armv8-A 架构为目标,请使用:
| |
此命令生成以下汇编代码:
| |
# 4.2.3 自动向量化
C/C++/Fortran 编译器(例如,适用于 Arm 平台的原生 Arm Compiler for Linux
和 GNU 编译器)支持使用 SVE 或 SVE2 指令对 C、C++ 和 Fortran 循环进行向量化。要生成 SVE 或 SVE2 代码,请选择适当的编译器选项。例如,使用 armclang 启用 SVE2 优化的一个选项是 -march=armv8-a+sve2 。如果要使用 SVE 版本的库,请将 -march=armv8-a+sve2 与 -armpl=sve 结合使用。
# 4.2.4 使用 SVE/SVE2 优化库
使用针对 SVE/SVE2 高度优化的库,例如 Arm Performance Libraries
和 Arm Compute Libraries。Arm Performance Libraries 包含针对 BLAS、LAPACK、FFT、稀疏线性代数和 libamath 优化的数学函数的高度优化实现。要能够链接任何 Arm Performance Libraries 函数,您必须安装 Arm Allinea Studio 并在代码中包含 armpl.h。要使用 Arm Compiler for Linux 和 Arm Performance Libraries 构建应用程序,您必须在命令行中指定 -armpl=<arg> 。如果您使用 GNU 工具,则必须使用 -L<armpl_install_dir>/lib 将 Arm Performance Libraries 安装路径包含在链接器命令行中,并指定与 Arm Compiler for Linux -armpl=<arg> 选项等效的 GNU 选项,即 -larmpl_lp64 。有关更多信息,请参阅 Arm Performance Libraries 入门指南。
# 4.3 如何运行 SVE/SVE2 程序
如果您无法访问 SVE 硬件,则可以使用模型或仿真器来运行代码。你可以选择以下几种模型和仿真器:
- QEMU: 交叉编译和原生模型,支持在具有 SVE 的 Arm AArch64 平台上进行建模。
- Fast Models: 跨平台模型,支持在基于 x86 的主机上运行的具有 SVE 的 Arm AArch64 平台进行建模。支持 SVE2 的 架构包络模型 AEM 只对主要合作伙伴可用。
- Arm Instruction Emulator (ArmIE): 直接在 Arm 平台上运行。支持 SVE,并从 19.2+ 版本开始支持 SVE2。
# 5. ACLE Intrinsics
# 5.1 ACLE 简介
ACLE (Arm C 语言扩展) 是在 C 和 C++ 代码中利用内部函数和其他特性来支持 Arm 的功能。
- ACLE (ARM C 语言扩展) 通过特定于 Arm 的特性扩展了 C/C++ 语言。
- 预定义宏:
__ARM_ARCH_ISA_A64、__ARM_BIG_ENDIAN等。 - 内部函数:
__clz(uint32_t x)、__cls(uint32_t x)等。 - 数据类型:SVE、NEON 和 FP16 数据类型。
- 预定义宏:
- 用于 SVE 的 ACLE 支持使用 ACLE 进行可变长度向量 (VLA) 编程。
- 几乎每个 SVE 指令都有一个对应的内部函数。
- 数据类型用于表示 SVE 内部函数所使用的无大小向量。
- 适用于以下用户的场景:
- 希望手动调整 SVE 代码的用户。
- 希望适配或手动优化应用程序和库的用户。
- 需要对 Arm 目标进行底层访问的用户。
# 5.2 如何使用 ACLE
- 引入头文件
arm_acle.h:核心 ACLEarm_fp16.h:添加 FP16 数据类型。- 目标平台需支持 FP16,即
march=armv8-a+fp16。
- 目标平台需支持 FP16,即
arm_neon.h:添加 NEON Intrinsics 和数据类型。- 目标平台需支持 NEON,即
march=armv8-a+simd。
- 目标平台需支持 NEON,即
arm_sve.h:添加 SVE Intrinsics 和数据类型。- 目标平台需支持 SVE,即
march=armv8-a+sve。
- 目标平台需支持 SVE,即
# 5.3 SVE ACLE
- 首先需要做的是引入头文件
| |
- VLA 数据类型
svfloat64_t,svfloat16_t,svuint32_t等。- 命名规则:
sv<datatype><datasize>_t
- Predication
- 合并:
_m - 置零:
_z - 不确定:
_x - P 寄存器的数据类型:
svbool_t
- 合并:
- 使用泛型做函数重载,比如函数
svadd会根据参数类型自动选择对应的函数。 - 函数命名规则:
svbase[disambiguator][type0][type1]...[predication]- base 指的是基本操作,比如
add、mul、sub等。 - disambiguator 用于区分相同基本操作的不同变体。
- typeN 指定了向量和 P 寄存器的类型。
- predication 指定了非活动元素的处理方式。
- 例如:
svfloat64_t svld1_f64,svbool_t svwhilelt_b8,svuint32_t svmla_u32_z,svuint32_t svmla_u32_m
- base 指的是基本操作,比如
# 5.4 SVE 常用 Intrinsics
- Predicate
- Predicate 是一个 bool 类型的向量,用于控制计算过程中向量中对应位置是否参与运算
svbool_t pg = svwhilelt_b32(i, num)产生 (i, i + 1, i + 2, …, i + vl - 1) < num 的 predicatesvbool_t pg = svptrue_b32()产生一个全为 true 的 predicate- 其中,b32 对应处理 32 位数据(int/float),此外还有 b8, b16, b64 对应的 intrinsic
- 内存数据存取
svld1(pg, *base): 从地址 base 中加载连续向量。svst1(pg, *base, vec): 将向量 vec 存储到地址 base 中。svld1_gather_index(pg, *base, vec_index): 从地址 base 中加载向量索引对应的数据。svst1_scatter_index(pg, *base, vec_index, vec): 将向量 vec 中数据存储到向量索引对应的位置。
- 基础计算
svadd_z(pg, sv_vec1, sv_vec2)svadd_m(pg, sv_vec1, sv_vec2)svadd_x(pg, sv_vec1, sv_vec2)svadd_x(pg, sv_vec1, x)- 其中,
_z表示将 pg 为 false 的位置置零,_m表示保留原值,_x表示不确定(什么值都有可能)。 - 第二个操作数可以为标量数据。
svmul,svsub,svsubr,svdiv,svdivr:其中,svsubr相比svsub交换了减数与被减数的位置。
- 其它
svdup_f64(double x): 生成一个所有元素都为 x 的向量。svcntd():返回 64-bit 数据的向量长度:svcntb对应 8 位,svcnth对应 16 位,svcntw对应 32 位。
# 5.5 SVE 结构体 Intrinsics
对应结构体数据,SVE 提供了一些特殊的 Intrinsics,比如:svld3, svget3, svset3, svst3 等。这些 Intrinsics 用于处理结构体数据。
例如,对于粒子结构体:
| |
可以使用 svld3 加载结构体中全部的数据为 3 个向量的组,然后使用 svget3 从 3 个向量的组中提取一个向量, index 的值为 0, 1, 2 分别对应 x, y, z。
| |
svld3(pg, *base): 加载结构体中全部的数据为 3 个向量的组;其中,base 是 3 个元素结构体数组的地址。svget3(tuple, index): 从 3 个向量的组中提取一个向量;index 的值为 0、1 或 2。svset3(tuple, index, vec): 设置 3 个向量的组中的一个向量;index 的值为 0、1 或 2。svst3(pg, *base, vec): 将 3 个向量的组存储到结构体中;其中,base 是 3 个元素结构体数组的地址。
# 5.6 SVE 条件选择
SVE 中提供了 svcmplt、svcompact、svcntp_b32 等方法,可以根据条件选择保留向量中的元素。
例如,对于无向量化的代码:
| |
该代码的作用是从 provided 数组中选择小于 mark 的元素,存储到 selected 数组中,直到 selected 数组满。
用 SVE Intrinsic 改写:
| |
svcmplt(pg, vec1, vec2):比较两个向量的大小,返回一个 predicate,表示 vec1 中小于 vec2 的位置。svcompact(pg, sv_tmp):压缩向量,将 pg 为 active 的数据按序移动到向量低位,其余位置置零。svcntp_b32(pg, pg2):返回 pg2 中 active 的元素个数- 这段代码先将 provided 数组中的数据加载到 sv_tmp 中,然后使用
svcmplt生成一个 predicate,表示小于 mark 的位置。接着使用svcompact压缩 sv_tmp,得到小于 mark 的数据,再通过svst1存储到 selected 数组中。最后,使用svcntp_b32统计 active 的元素个数,更新 count。
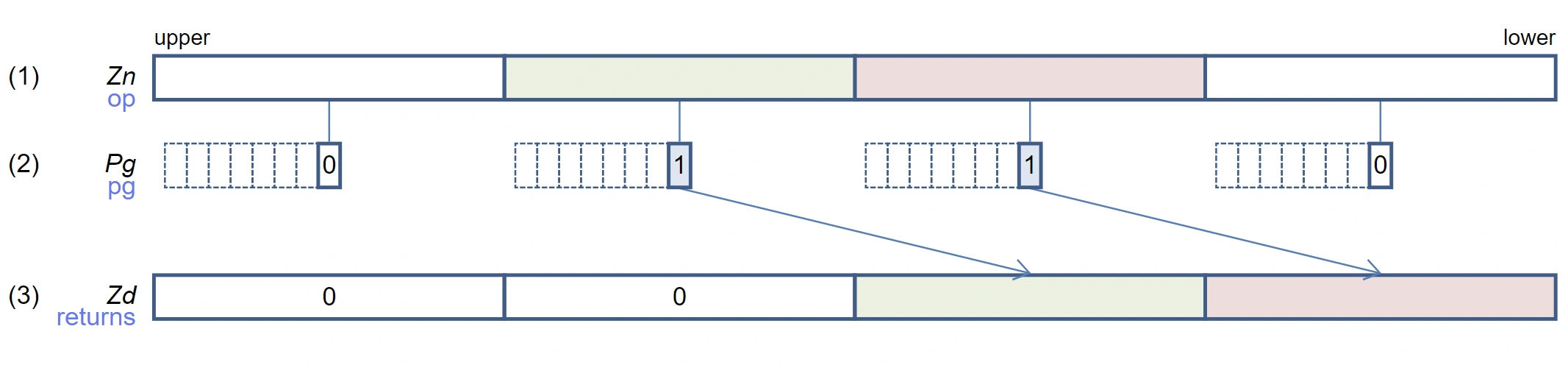
svcompact 示意图(256-bit 向量)
由于进行了 compact 操作,所以 selected 数组从 count 位置连续存储新的小于 mark 的数据,剩下的位置被置零。
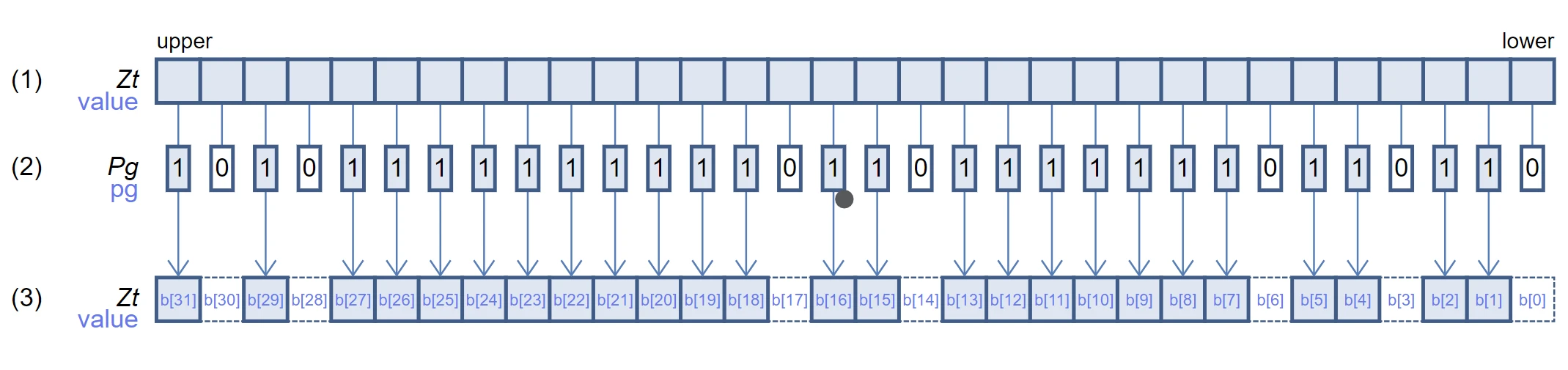
svst1 示意图(256-bit 向量)
# 5.7 SVE 向量化循环交织
SVE Intrinsic 实现的向量化循环交织,相比编译器自动向量化能大大减少读取向量的次数。
例如,对于无向量化的代码:
| |
编译器对该代码进行自动向量化后,每次迭代需读取五次不同向量的数据,效率较低。
用 SVE Intrinsic 改写:
| |
svmad_x(pg, vec1, vec2, vec3):计算 vec1 * vec2 + vec3,返回一个向量。- 这段代码每次迭代只需读取一个向量,大大减少向量读取的次数。