# 1. SME 简介
可伸缩矩阵扩展 SME (Scalable Matrix Extension) SME 是在可伸缩向量扩展(Scalable Vector Extensions, SVE 和 SVE2)的基础上建立的,并增加了有效处理矩阵的能力,主要功能包括:
- 计算 SVE 向量的外积(Outer product)
- 矩阵块(tile) 存储
- tile 向量的加载、存储、插入和提取(包括动态转置)
- Streaming SVE 模式
下表总结了 SME、SVE 和 SVE2 的主要功能:
| SME | SVE | SVE2 |
|---|---|---|
| Streaming SVE 模式 | NEON DSP++ | 可伸缩向量 |
| 动态矩阵转置 | 多精度算术 | per-lane predication |
| 向量外积 | 匹配检测和直方图 | Gather-load 与 Scatter-store |
| 加载、存储、插入和提取矩阵向量 | 非时间性 scatter/gather | 预测向量化 |
| 按位置换(bitwise permute) | ML 扩展(FP16 + DOT) | |
| AE、SHA3、SM4、Crypto | V8.6 BF16, FP 与 Int8 支持 |
SME 定义了以下新功能:
- 新的架构状态,可以用来存储二维矩阵 tile
- Streaming SVE 模式,支持执行向量长度与 tile 长度匹配的 SVE2 指令。
- 将两个向量的外积累加(或累减)到一个矩阵 tile 中的新指令。
- 新的加载、存储和移动指令:可以将向量写入到矩阵 tile 的一行或一列,也可以将矩阵 tile 的一行或一列读取到向量。
与 SVE2 类似,SME 也是一种支持可伸缩向量长度的扩展,可实现向量长度无关性 (VLA)、per-lane predication、predication 驱动的循环控制和管理功能。
# 2. Streaming SVE 模式
SME 引入了 Streaming SVE 模式,该模式实现了 SVE2 指令集的一个子集,并增加了新的 SME 专用指令。
Streaming SVE 模式支持对大型数据集进行高吞吐量地流式数据处理,流式数据通常具有简单的循环控制流和有限的条件性。
在 Non-streaming SVE 模式下,支持完整的 SVE2 指令集,通常处理复杂的数据结构和复杂的判断。
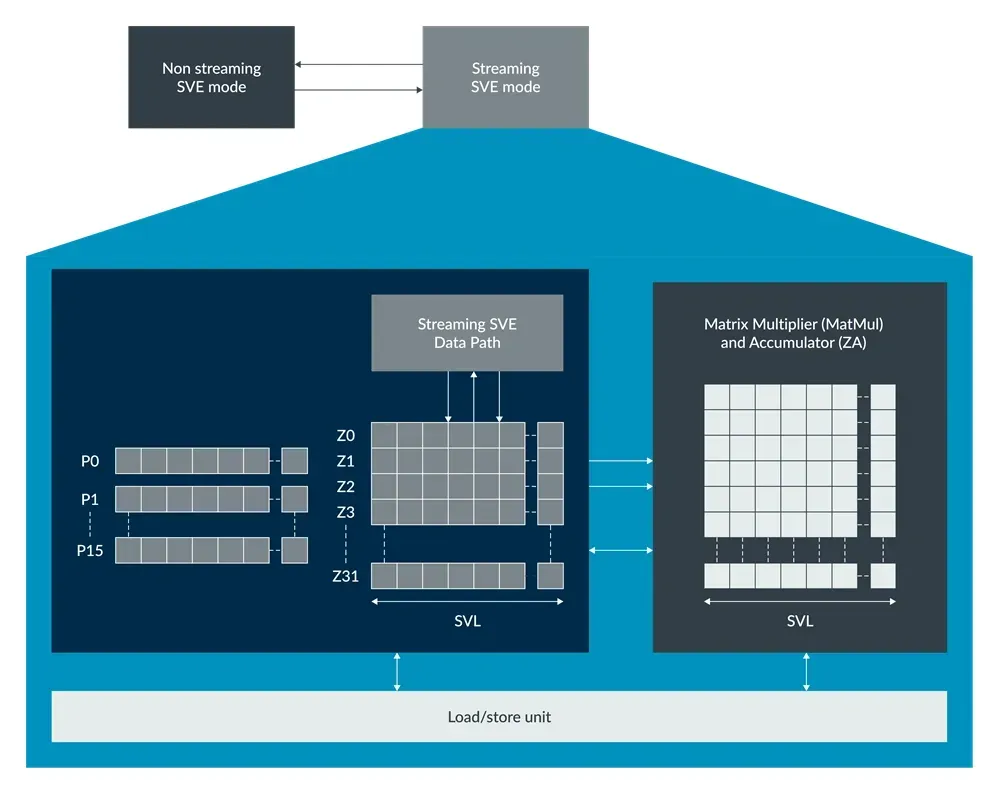
Streaming SVE 模式与 Non-streaming SVE 模式
大多数 SME 指令仅在 Streaming SVE 模式下可用。Streaming SVE 模式下的流向量长度(SVL)可能与非流向量长度(NSVL)不同。
预期是:SVL 要比 NSVL 更长或是相同,也就是 SVL >= NSVL。例如,NSVL 的长度可以为 128-bit , 而 SVL 的长度可以为 512-bit 。
SME 的 SVL 可以是 128-bit , 256-bit , 512-bit, 1024-bit 或是 2048-bit 。SVL 需要是 2 的次幂,而 NSVL 需要是 128 的整数倍。
与 SVE2 类似,软件可以控制 SMCR_ELx.LEN 寄存器位来设置 EL1, EL2, EL3 想用的有效 SVL 长度(可以设置为比硬件支持的 SVL 更短)。
有关 Streaming SVE 模式的更多信息,请参阅《Arm 架构参考手册》第 B1.4.6 节(A-profile 架构)。
# 3. 切换 Non-streaming 和 Streaming SVE 模式
如果 CPU 硬件实现既支持 Streaming SVE 模式的 SME ,又支持 Non-streaming SVE 模式的 SVE2 ,应用程序可以根据自己的需求动态切换这两个操作模式。
为 SME 提供一个独立的操作模式,使 CPU 硬件实现可以为同一应用提供不同的向量长度。比如 CPU 硬件实现可以选择支持一个更长的 Streaming SVE 模式向量长度,并针对适用于高吞吐量的流操作对硬件进行优化。
应用程序很容易在 Streaming SVE 模式和 Non-streaming SVE 模式之间动态切换。SME 引入的 PSTATE.{SM, ZA} 位可以可启用和禁用 Streaming SVE 模式和 SME ZA 存储:
- SM: 启用与禁用 Streaming SVE 模式
- ZA:启用和禁用 ZA 存储访问
可以通过 MSR/MRS 指令操作 Streaming Vector Control Register (SVCR) 来设置和读取 PSTATE.{SM, ZA} 位,具体操作如下:
MSR SVCRSM, #<imm> MSR SVCRSM,#MSR SVCRZA, #<imm>MSR SVCRSMZA, #<imm>
SMSTART 指令是设置 PSTATE.SM 和 PSTATE.ZA 的 MSR 指令的别名
SMSTART:同时启用 Streaming SVE 模式和 ZA 存储访问SMSTART SM:启用 Streaming SVE 模式SMSTART ZA:启用 ZA 存储访问
SMSTOP 指令则是清除 PSTATE.SM 和 PSTATE.ZA 的 MSR 指令的别名。
SMSTOP:同时禁用 Streaming SVE 模式和 ZA 存储访问SMSTOP SM:禁用 Streaming SVE 模式SMSTOP ZA:禁用 ZA 存储访问
下图展示了应用程序是如何在 Streaming SVE 模式和 Non-streaming SVE 模式之间切换的:
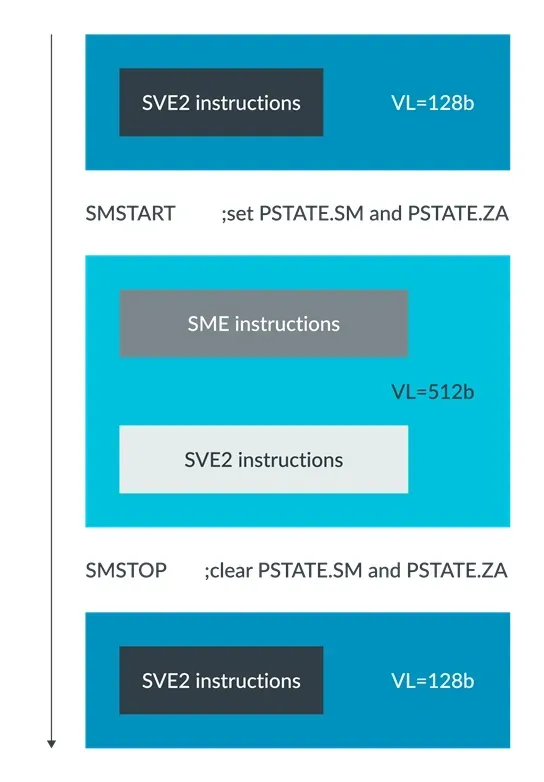
应用程序切换 Streaming SVE 模式和 Non-streaming SVE 模式
有关使用 SMSTART 和 SMSTOP 在 Streaming SVE 模式和 Non-Streaming SVE 模式之间切换的更多信息,请参阅《Arm 架构参考手册》中有关 A-profile 架构的 C6.2.327 和 C6.2.328 节。
# 4. SME 架构状态
与 SVE2 类似,在 Streaming SVE 模式,它有 Z0-Z31 向量寄存器,和 P0-P15 Predicate 寄存器。
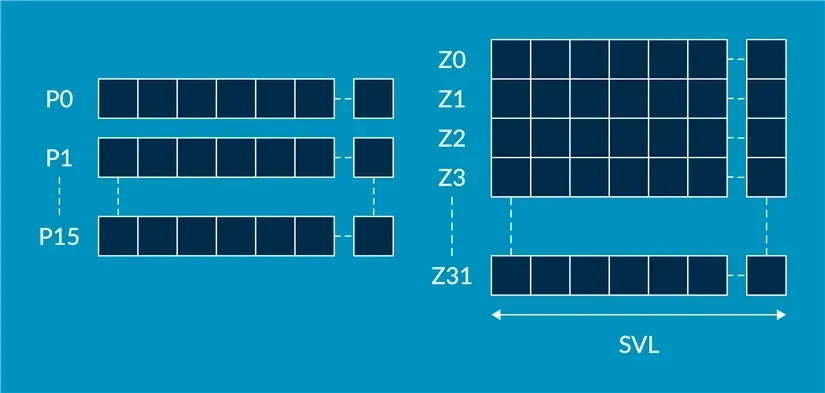
SVE 向量寄存器的最低编号位 Zn 也保存着固定长度的 Vn、Qn、Dn、Sn、Hn 和 Bn 寄存器。
进入 Streaming SVE 模式( PSTATE.SM 由 0 变为 1)或退出 Streaming SVE 模式( PSTATE.SM 由 1 变为 0)时,所有这些寄存器都将置零。
大多数 Non-streaming SVE2 指令可用于 Streaming SVE 模式,但可能使用不同的向量长度(流模式使用 VSL 长度,非流模式使用 NVSL 长度)。可以使用 RDSVL 指令读取当前的有效向量长度 VL。
| |
注释
因为 SME 支持 Vector Length Agnostic (VLA) ,在 Streaming SVE 模式下,软件很少需要明确读 SVL 向量长度。在 Non-streaming SVE 模式下,通常使用 RDSVL 指令来确定 SVL 的值。
# 5. ZA array
SME 新引入的 ZA (Z Array, ZA Storage) 是一个二维(2D)正方形数组,大小是 SVL x SVL。之所以叫 Z Array,也是因为它行与列的长度与 Streaming SVE 模式下的 Zn 寄存器一致。

ZA array
例如:如果 Streaming SVE 模式下的向量长度为 256-bit,即 Zn 寄存器的长度为 256-bit,那么 ZA 的大小为 (256/8 bytes) x (256/8 bytes) 。
ZA array 可以通过以下方式访问:
- ZA array vector 访问
- ZA tiles
- ZA tile slices
# 5.1 ZA array vector 访问
ZA array 的一行可以当成一个 SVL 长度的向量来访问,这个向量可以放数据类型长度为 8-bit, 16-bit, 32-bit, 64-bit 或 128-bit 的元素,比如 32-bit 的 fp32 浮点数。
| |
其中 B,H,S,D,Q 分别表示 8-bit , 16-bit , 32-bit , 64-bit , 128-bit。
ZA array vector 的数量与 SVL 中的字节数相同,例如,如果 SLV 是 256-bit ,那么 ZA array vector 的数量是 32 个,N 的范围是 0 到 31。
为了支持上下文切换,SME 引入了新的 LDR 和 STR 指令,用于从内存加载和存储一个 ZA array vector。
| |
# 5.2 ZA tiles
ZA tile 是在 ZA 中的正方形的二维子矩阵。ZA tile 的宽度始终是 SVL,与 ZA array 的宽度相同。
ZA 可以分成多少个可用的 ZA tile 是由元素的数据类型大小决定的:
| 元素数据类型大小 | tile 数量 | tile 名称 |
|---|---|---|
| 8-bit | 1 | ZA0.B |
| 16-bit | 2 | ZA0.H-ZA1.H |
| 32-bit | 4 | ZA0.S-ZA3.S |
| 64-bit | 8 | ZA0.D-ZA7.D |
| 128-bit | 16 | ZA0.Q-ZA15.Q |
- 当元素数据类型为 8-bit 时,ZA 只能作为一个 ZA tile (ZA0.B) 被访问。
- 当元素数据类型为 16-bit 时,ZA 可以作为 2 个 ZA tile (ZA0.H 和 ZA1.H) 被访问。
- 当元素数据类型为 32-bit 时,ZA 可以作为 4 个 ZA tile (ZA0.S 到 ZA3.S) 被访问。
- 当元素数据类型为 64-bit 时,ZA 可以作为 8 个 ZA tile (ZA0.D 到 ZA7.D) 被访问。
- 当元素数据类型为 128-bit 时,ZA 可以作为 16 个 ZA tile (ZA0.Q 到 ZA15.Q) 被访问。
例如,如果 SVL 为 256-bit,元素数据类型大小为 8-bit,则 ZA 可以视为 ZA0.B,也可视为 32 个向量(32 行,每行大小为 32 x 8-bit,即每行 32 个元素)。

如果 SVL 为 256-bit,元素数据类型大小为 16-bit,则 ZA 可以视为 2 个 ZA tile (ZA0.H 和 ZA1.H),每个 tile 视为 16 个向量(16 行,每行大小为 16 x 16-bit,即每行 16 个元素)。
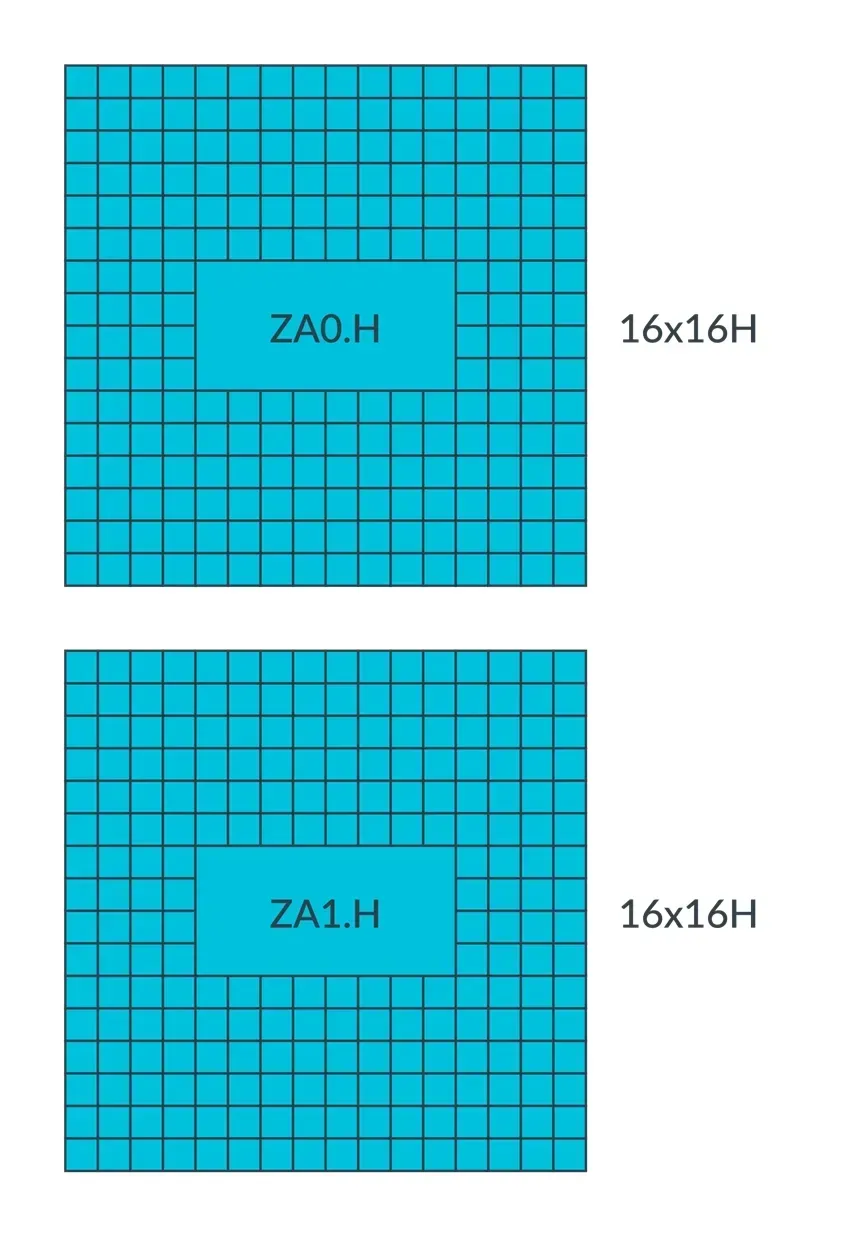
这样做的好处是充分利用了 ZA storage,在实际应用中,比如说当 SVL 为 256-bit,元素数据类型大小为 32-bit,ZA 的大小为 256-bit x 256-bit 时,要对两个 Z 寄存器里的向量做外积运算,计算得到的外积结果是 8 x 8 的二维浮点数数组,这个外积只需要 ZA 的 1/4 的存储空间。将 ZA 分成 4 个 ZA tile,这样就可以充分利用 ZA storage。
# 5.3 ZA tile slices
一个 ZA tile 可以作为一个整体来访问,也可以以一个个 ZA tile slice 的方式访问。
当作为一个整体访问时,指令可以使用 tile 的名字访问:
| |
一个 ZA tile slice 是由其 ZA tile 中水平方向或是垂直方向的连续元素组成的一维数组,即在 ZA tile 中的一行或是一列。
对一个 ZA tile 的向量访问即是读写一个 ZA tile slice :
- 水平或垂直方向的 ZA tile slice 访问,由 ZA tile 名字后的
H或V后缀来表示。 - 具体的 ZA tile slice 由一个索引来表示,由 ZA tile 名字后的切片索引
[N]来表示。
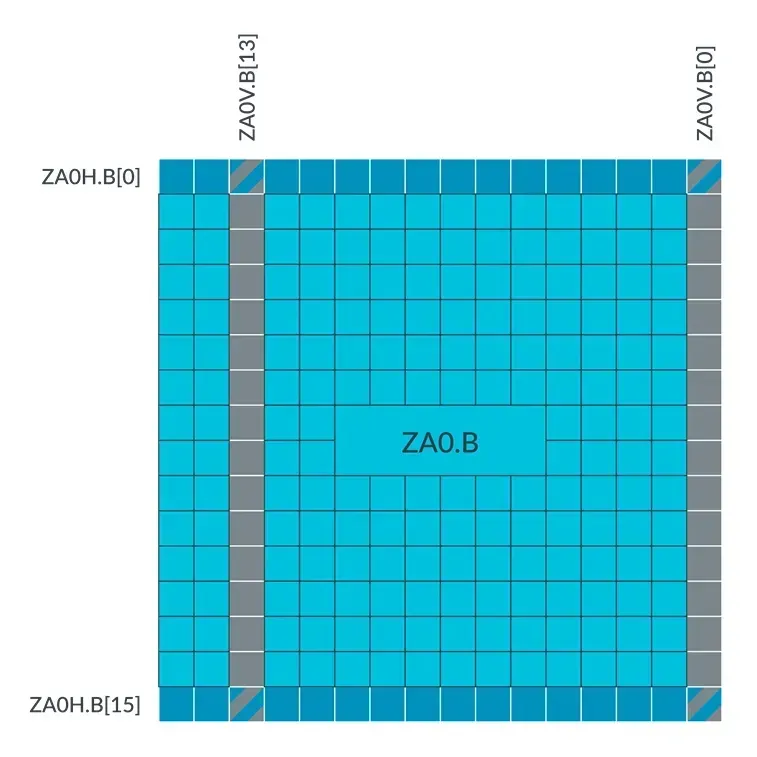
例如,如果 SVL 为 128 位,元素数据类型大小为 8-bit,那么其水平的和垂直的 ZA tile slice 可由下图所示:
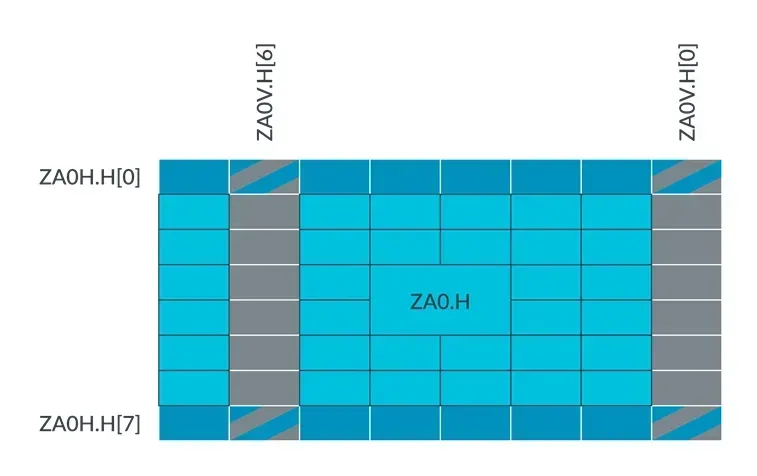
再例如,如果 SVL 为 128 位,元素数据类型大小为 16-bit,那么其水平的和垂直的 ZA tile slice 可由下图所示:
为了提高硬件访问 ZA tile 和 ZA tile slices 的效率,ZA tile 的 ZA tile slices 是交错排列的。
下图显示了这种交错排列的示例。在此示例中,SVL 为 256 位,元素数据类型大小为 16 位。这意味着,ZA 可被视为两个 ZA tile(ZA0H 和 ZA1H),并具有交错的水平 tile slices :
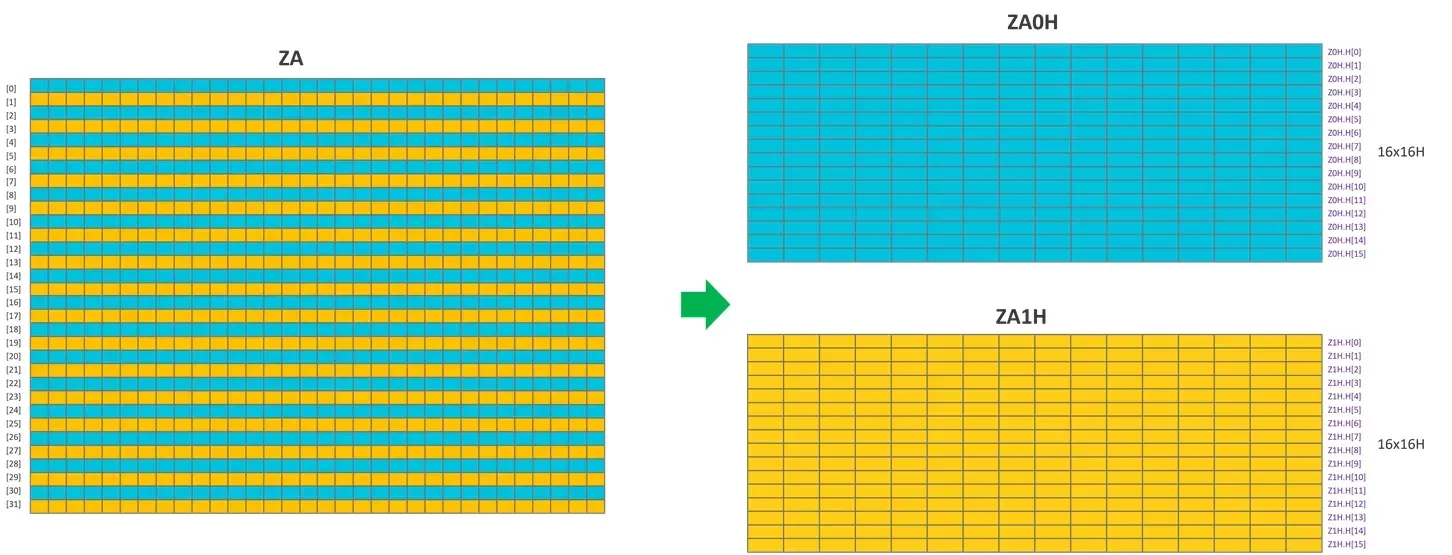
下图展示了不同的元素数据类型大小的水平和垂直方向 ZA tile slice 的混合视图:

左侧各栏显示了 ZA 存储器每一行的不同处理方式。
设 SIZE 为向量元素的大小,其中 SIZE 为 1、2、4、8、16,分别代表数据类型 B、H、S、D 或 Q。
设 NUM_OF_ELEMENTS 为向量中的元素个数,即 bytes_of(SVL)/SIZE。
水平 tile slice, ZAnH.<B|H|S|D|Q>[m] 访问一个向量,该向量包含 ZA storage 中的整行(m x SIZE + n)。该向量包含数据类型为 B、H、S、D 或 Q 的元素。
垂直 tile slice,ZAnV.<B|H|S|D|Q>[m] 访问一个向量,该向量包含 ZA storage 中的整列(m x SIZE)。该向量包含数据类型为 B、H、S、D 或 Q 的元素。
ZAnV.[m] 访问一个包含列(m x SIZE)和行元素(i x SIZE + n)的向量,其中 i 为 0 ~ NUM_OF_ELEMENTS-1。该向量包含数据类型为 B、H、S、D 或 Q 的元素。
使用混合元素数据类型大小以及水平和垂直 tile slice 的应用应小心处理重叠。
有关 ZA Array、ZA array vectors、tile 和 tile slices 的更多信息,请参阅《Arm 架构参考手册》中有关 A-profile 架构的 B1.4.8 至 B1.4.12 节。
# 6. Steaming SVE 模式下支持的指令
某些指令在 Streaming SVE 模式下有限制:
- 一些 SVE/SVE2 指令变为非法执行
- Gathed-load 和 Scatter-store 指令
- 使用 First Fault 寄存器的 SVE2 指令
- 大多的 NEON 指令变为 UNDEFINED
有关受 Streaming SVE 模式影响的指令的更多信息,请参阅文档 《Arm 架构参考手册》。
SME 增加了几条新指令,其中包括:
- 矩阵外积和累加或减法指令,包括 FMOPA、UMOPA 和 BFMOPA。
- SVE2 向量寄存器(Z0-Z31)作为外积运算的行和列输入。
- ZA storage 保存二维矩阵 tile 的输出结果。
- 将 SVE2 Z 向量与 ZA 的行或列做加法运算的指令
- 对 ZA tiles 的清零操作指令
- 增加了一些在 Streaming 和 Non-streaming 模式下都能使用的指令
# 7. SME 指令
操作 ZA storage 的 SME 指令主要包括:
- 计算两个向量的外积,并累加或累减,然后将结果放入一个 ZA tile 的指令
- 将 SVE 向量(Z 寄存器)存入或取出 ZA tile 的行或列的指令
- 水平或垂直方向上,一个 SVE 向量与 ZA tile 的加法指令
- 给一个标量寄存器加上 Streaming SVE 模式下向量长度的倍数的指令
# 7.1 外积并累加或累减指令
为了帮助理解外积并累加或累减指令,让我们看看如何使用外积操作来做矩阵乘法。
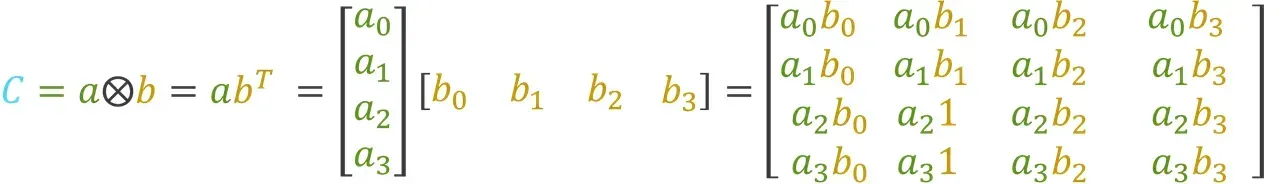
计算两个向量 a 和 b 的外积会得到一个包含外积的结果矩阵 C:
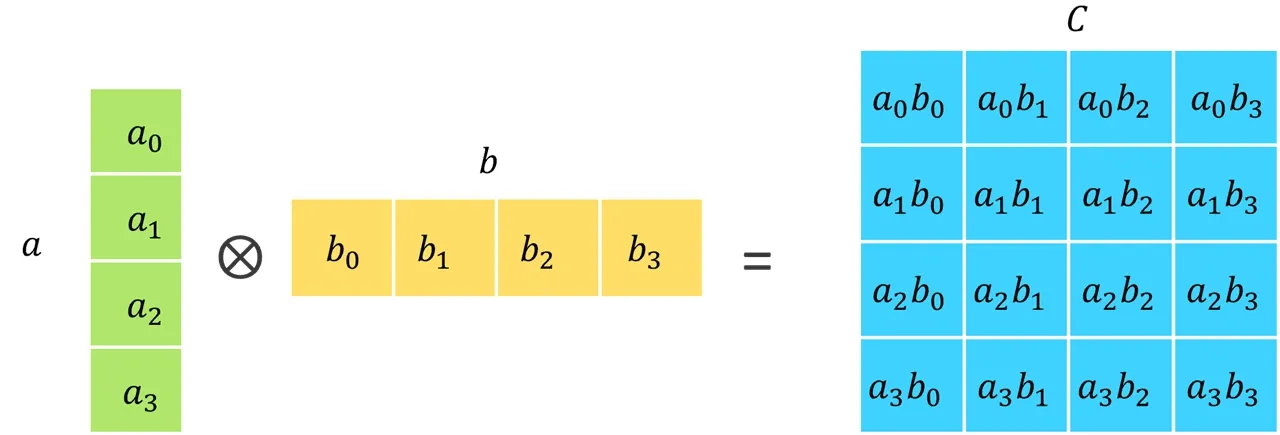
现在考虑两个矩阵 a 和 b 的矩阵乘运算:
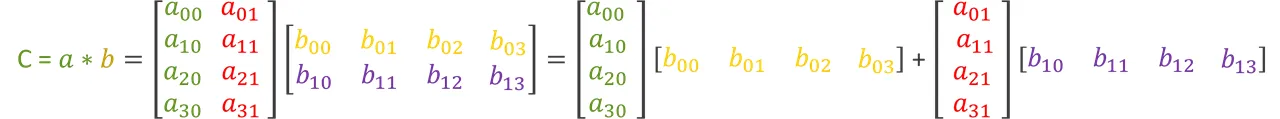
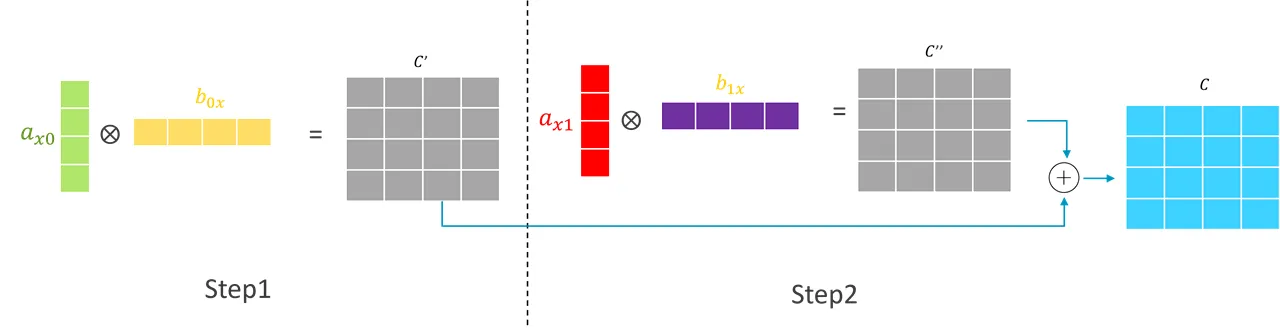
这个矩阵乘可以通过计算两次外积操作和两个结果矩阵的累加来实现(就是常用的手写计算的方法),如下图所示:
SME 为以下数据类型引入了高效的外积并累加或减法指令:
- 8-bit, 16-bit 整数
- FP16, BF16, FP32 和 FP64 浮点数
这些指令计算两个 Z 向量寄存器(Zn 和 Zm)中两个向量的外积,将结果数组与一个 ZA tile(ZAda)中已有数据进行累加或累减,并将结果存入同一 ZA tile(ZAda)中。每个源向量由相应的控制 predicate 寄存器(Pn 和 Pm)独立地 predicate。
| 输出数组 | 输入向量 | 描述 | 示例 |
|---|---|---|---|
| INT32 | INT8, INT8 | 将四个 INT8 外积之和存入每个 INT32 元素 | SMOPA 或 SMOPS 或 UMOPA 或 UMOPS:带符号或无符号整数外积和,并累加或累减。例如: UMOPS <ZAda>.S, <Pn>/M, <Pm>/M, <Zn>.B, <Zm>.B |
| INT32 | INT16, INT16 | 将两个 INT16 外积之和存入每个 INT32 元素 | SMOPA 或 SMOPS 或 UMOPA 或 UMOPS:带符号或无符号整数外积和,并累加或累减。例如: UMOPS <ZAda>.S, <Pn>/M, <Pm>/M, <Zn>.H, <Zm>.H |
| INT64 | INT16, INT16 | 如果实现了 FEAT_SME_I16I64,则将四个 INT16 外积之和存入每个 INT64 元素 | SMOPA 或 SMOPS 或 UMOPA 或 UMOPS:带符号或无符号整数外积和,并累加或累减。例如: UMOPS <ZAda>.D, <Pn>/M, <Pm>/M, <Zn>.H, <Zm>.H |
| FP32 | BF16, BF16 | 将两个 BF16 外积之和存入每个 FP32 元素 | BFMOPA 或 BFMOPS:BFloat16 外积和,并累加或累减。例如: BFMOPS <ZAda>.S, <Pn>/M, <Pm>/M, <Zn>.H, <Zm>.H |
| FP32 | FP16, FP16 | 将两个 FP16 外积之和存入每个 FP32 元素 | FMOPA 或 FMOPS:半精度浮点外积和,并累加或累减。例如: FMOPS <ZAda>.S, <Pn>/M, <Pm>/M, <Zn>.H, <Zm>.H |
| FP32 | FP32, FP32 | 简单的 FP32 外积 | FMOPA 或 FMOPS:浮点外积和,并累加或累减。例如: FMOPS <ZAda>.S, <Pn>/M, <Pm>/M, <Zn>.S, <Zm>.S |
| FP64 | FP64, FP64 | 如果实现了 FEAT_SME_F64F64,则进行简单的 FP64 外积 | FMOPA 或 FMOPS:浮点外积和,并累加或累减。例如: FMOPS <ZAda>.D, <Pn>/M, <Pm>/M, <Zn>.D, <Zm>.D |
# 7.1.1 FP32, FP64 外积并累加或累减指令
那些输入向量和输出数组有同样数据类型(FP32, FP64)的指令相对简单。
下例展示了 FP32 类型的外积并累加或累减指令。
| |
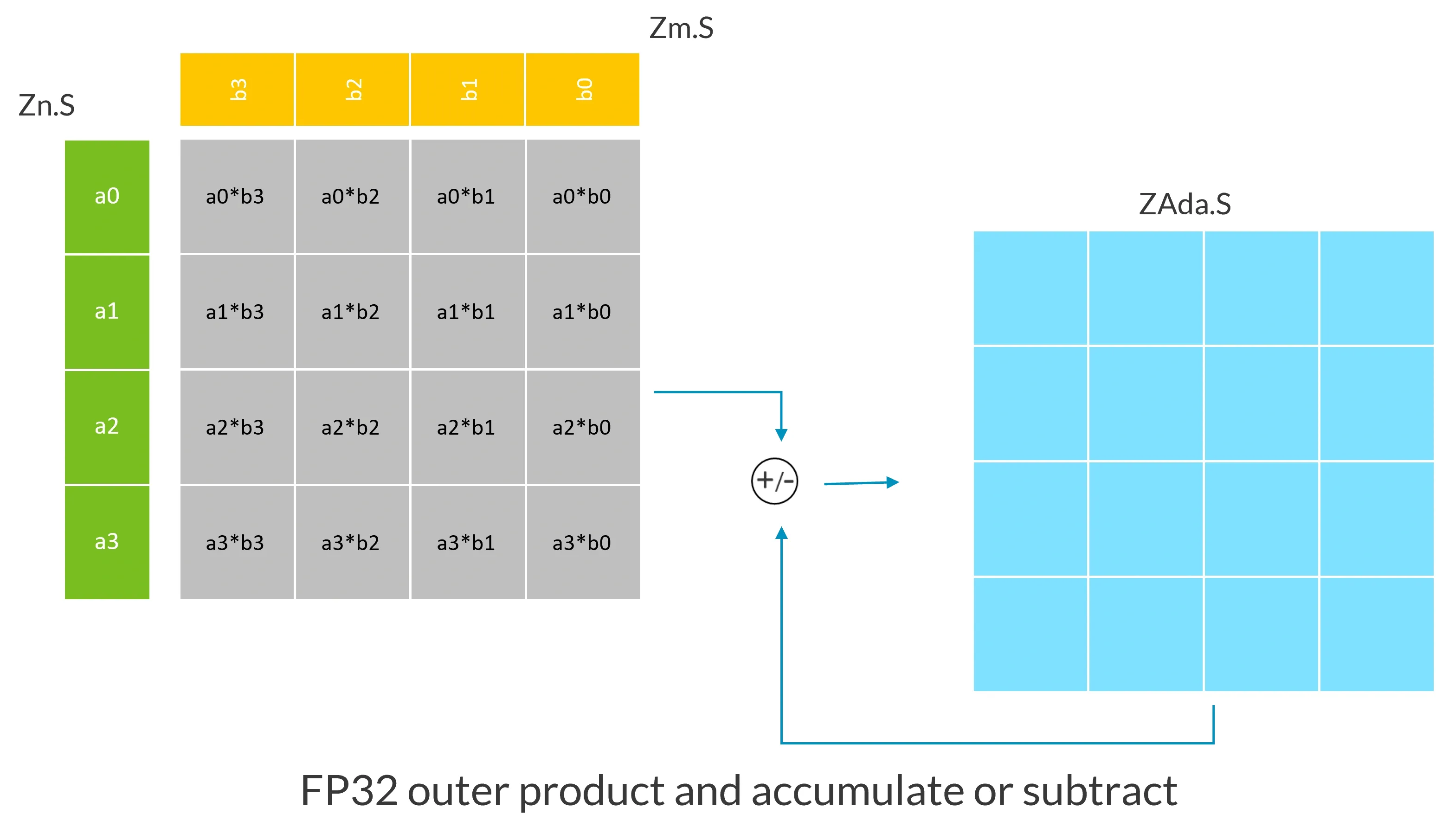
这个例子中,假设 SVL 向量长度为 128,Zn.S 和 Zm.S 中存放了 4 个 FP32 数组成的向量,此指令计算 Zn.S 和 Zm.S 的外积,外积结果为图中灰色的矩阵,然后将此外积结果累加或累减 ZAda.S 这个 ZA tile 中原有的值,将结果存入同一 ZA tile。
# 7.1.2 FP16, BF16, INT16, INT8, I16I64 类型的外积并累加或累减指令
由于这些指令会扩大计算结果数据类型,因此这些操作不像前面 FP32,FP64 类型指令那么简单明了。
- BF16 指令计算两个 BF16 的外积的和,扩大结果类型为 FP32, 然后将结果与目标 tile 进行破坏性相加或相减。
- INT8 指令计算四个 INT8 的外积的和,扩大结果类型为 INT32,然后将结果与目标 tile 进行破坏性相加或相减。
- INT16 指令计算两个 INT16 的外积的和,扩大结果类型为 INT32,然后将结果与目标 tile 进行破坏性相加或相减。
- FP16 指令计算两个 FP16 的外积的和,扩大结果类型为 FP32,然后将结果与目标 tile 进行破坏性相加或相减。
- 如果实现了 FEAT_SME_I16I64,I16I64 指令计算四个 INT16 的外积的和,扩大结果类型为 INT64, 然后将结果与目标 tile 进行破坏性相加或相减。
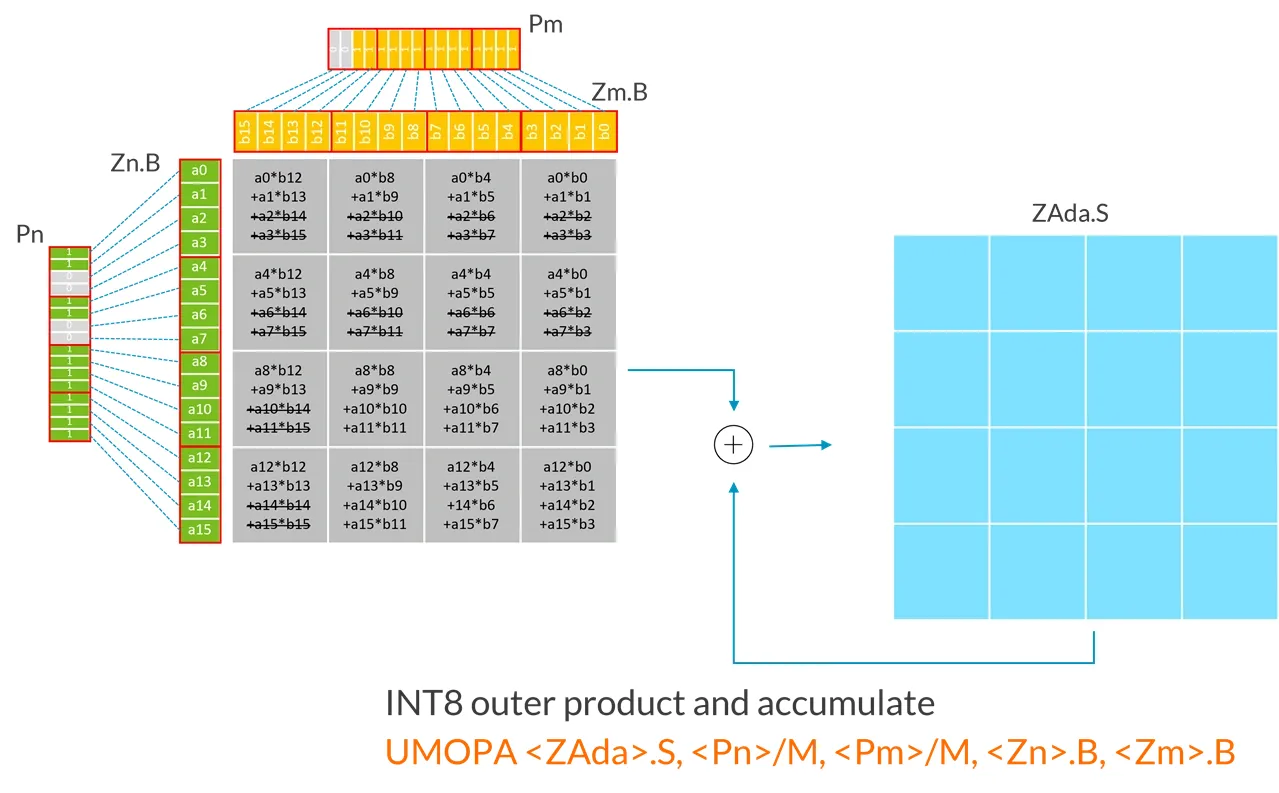
以下例子展示了 SVL 向量长度为 128 的 INT8 UMOPA 指令进行的操作:
| |
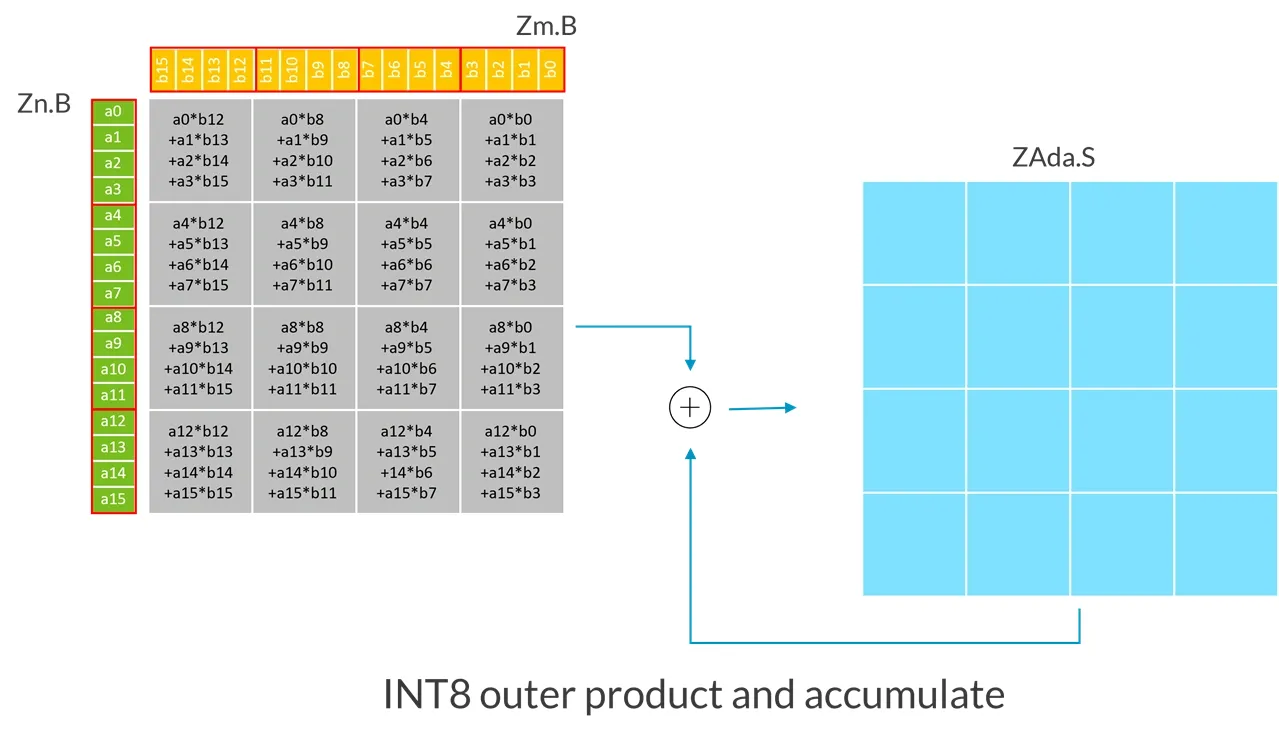
每个输入寄存器(Zn.B、Zm.B)都被视为一个包含 4x4 元素的矩阵,可以看作是 4 个连续元素组成的块(如图中红线所标)被转置了。
在这个例子中,因为 SVL 向量长度为 128-bit:
- 第一源向量
Zn.B,包含一个无符号 8-bit 整数的 4x4 子矩阵。 - 第二源向量
Zm.B,包含一个无符号 8-bit 整数的 4x4 子矩阵。 - UMOPA 指令计算出 4x4 扩大了的 32-bit 整数外积的和,然后破坏性地累加上目标 tile(ZAda)中的整数。
更笼统地说,UMOPA 指令是将第一个源向量中的子矩阵与第二个源向量中的子矩阵相乘。每个源向量包含一个(SVL/32) x 4 的无符号 8-bit 整数的子矩阵。然后将得到的 (SVL/32) x (SVL/32)扩大了的 32-bit 整数外积和破坏性地加上一个 32-bit 整数目标 tile。
下面的例子展示了 SVL 为 128-bit 的 BF16 BFMOPA 进行的操作:
| |
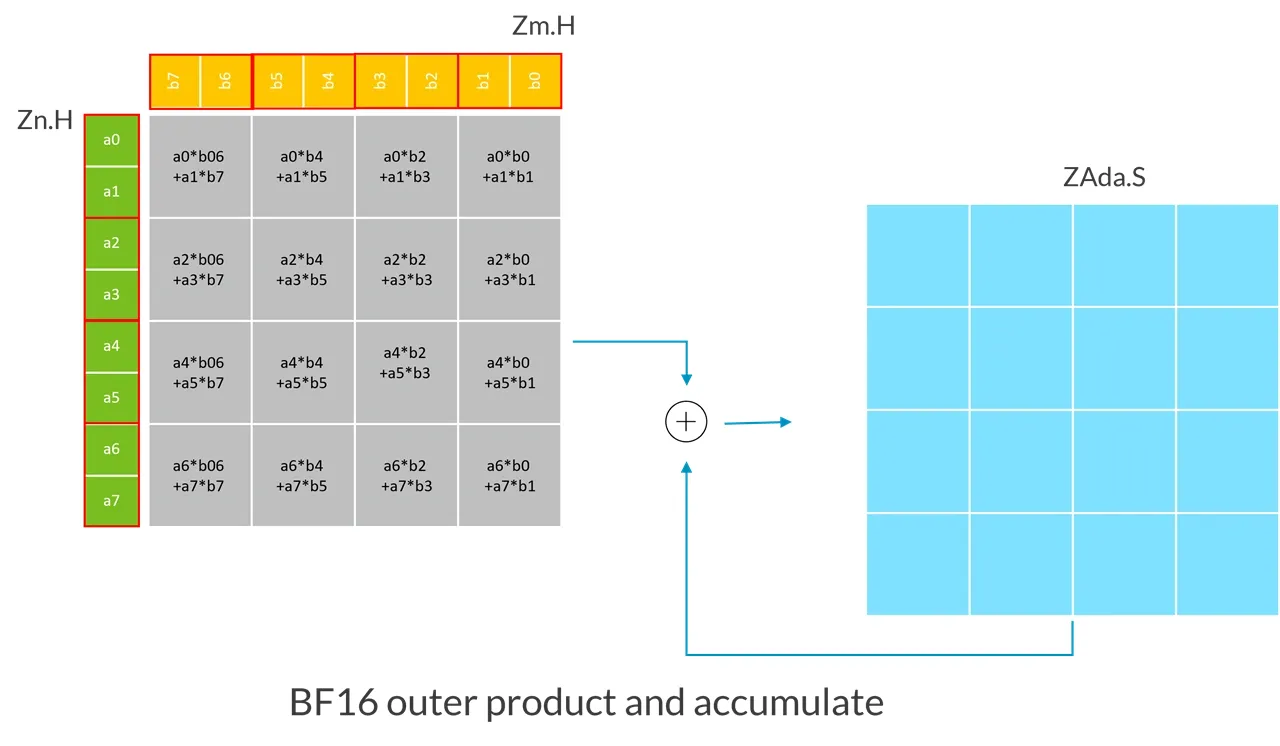
在这个例子中,因为 SVL 向量长度为 128-bit:
- 第一源向量
Zn.H,包含一个 BF16 整数的 4x2 子矩阵,它被扩大成单精度浮点数。 - 第二源向量
Zm.H,包含一个 BF16 整数的 2x4 子矩阵,它被扩大成单精度浮点数。 - BMOPA 指令计算出 4x4 单精度外积的和,然后破坏性地累加上目标 tile(ZAda)中的单精度浮点数。
更笼统地说,BFMOPA 指令扩大了存放在第一源向量里的(SVL/32) x2 BF16 子矩阵的类型为单精度,扩大了存放在第二源向量里的 2x (SVL/32) BF16 子矩阵的类型为单精度,将这两个子矩阵相乘。然后将得到的 (SVL/32) x (SVL/32)单精度外积和破坏性地加上一个单精度目标 tile。
以下表格显示了几种数据类型和 SVL 长度的一条外积并累加或累减指令所做的对应数据类型的 MAC(乘累加)数量:
| 128-bit | 256-bit | 512-bit | |
|---|---|---|---|
| FP32 | 16 | 64 | 256 |
| FP64 | 4 | 16 | 64 |
| INT8 | 64 | 256 | 1024 |
| INT16 | 32 | 128 | 512 |
| BF16 | 32 | 128 | 512 |
| FP16 | 32 | 128 | 512 |
# 7.2 带 Predication 的 SME 指令
每个源向量都可以被其相应的控制 predicate 寄存器独立地 predicate:
- 外积并累加或累减指令使用 Pn/M 和 Pn/M (没有/Z 形式):Inactive 的源元素被当成具有 0 值。
- Slice move 指令使用 Pg/M: 目标 slice 中 Inactive 的元素保持不变。
- Tile slice load 指令使用 Pg/Z: 目标 tile slice 中的 Inactive 元素被设置为 0。
- Tile slice store 指令使用 Pg: Inactive 的元素不会写入内存。
Predication 让矩阵的维数不是 SVL 的倍数的情况更容易处理。
例如下图的指令:
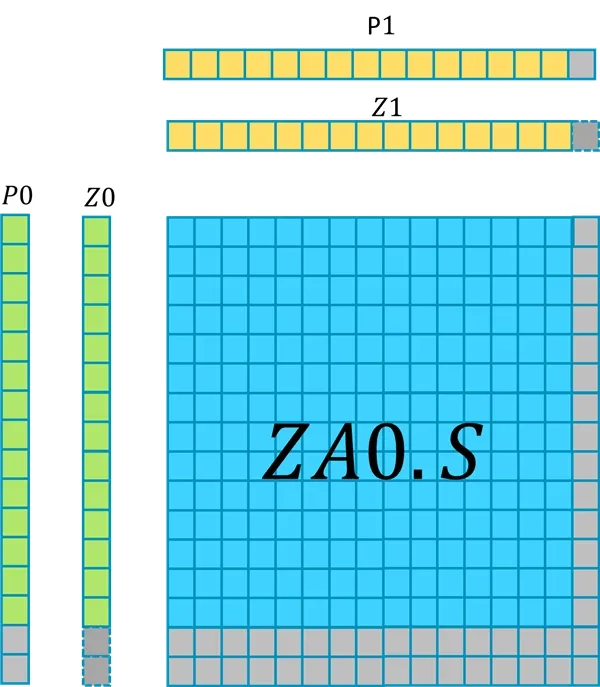
输入向量 Z0 被 P0 predicate,Z1 被 P1 predicate。
在这个例子中:
- SVL 向量长度为 512-bit。
- Z 寄存器中包含 16 个 FP32 数组成的向量。
P0中最后两个元素是 inactive 的。P1中最后一个元素是 inactive 的。
这条指令更新 ZA0.S 中 (16-2) x (16-1) 个 FP32 元素,因为使用了 Pn/M , ZA0.S 中剩下的元素保持不变。
下图展示了更多的 predicated 外积并累加或累减的例子。图中被划线的文字表示被 inactive predicate 元素影响的计算部分。

# 7.3 ZA tile 与一个 Z 向量的加运算
SME 包括 ZA tile 的行或列都加上一个向量的指令,这些指令也有 predication 的支持。
| 指令 | 说明 |
|---|---|
| ADDHA | 将源向量添加到 ZA tile 的每个水平 slice 上 |
| ADDVA | 将源向量添加到 ZA tile 的每个垂直 slice 上 |
例如:
| |
将执行以下操作:

这个 ADDHA 指令将源向量 Z1 中的每个元素加上 ZA0.S tile 每一水平 slice 的相应 active 元素。
Tile 中元素被一对 governing predicate 进行 predicate。 一个水平 slice 中的一个元素在下面情况下可以认为是 active:
- 它在第二 governing predicate 对应的元素是 TRUE, 并且
- 它在第一 governing predicate 对应的水平 slice 行号也为 TRUE,目标 tile 中 inactive 元素保持不变。
# 7.4 Tile load, store, move 指令
SME tile load, store, move 指令可以:
- 从内存读取数据,放入 ZA tile 的行或列
- 将 ZA tile 的行或列写入内存
- 将 ZA tile 的行移动到 SVE Z 向量寄存器
- 将 SVE Z 向量寄存器移动到 ZA tile 行或列
# 7.4.1 Tile slice load 和 store 指令
LD1B、LD1H、LD1S、LD1D 和 LD1Q 指令分别将连续内存值加载到具有 8-bit、16-bit、32-bit、64-bit 或 128-bit 元素的 ZA tile slice 中。
ST1B、ST1H、ST1S、ST1D 和 ST1Q 指令分别将包含 8-bit、16-bit、32-bit、64-bit 或 128-bit 元素的 ZA tile slice 存储到连续内存中。
这些指令也支持 predication ,例如:
| |
此 LD1B 指令执行 predicated 的连续 byte 读取,它从地址为(X1+X2)的内存读取数据到 ZA0 中行号为(W0+imm)的这个水平 tile slice 中。目标 tile slice 中 Inactive 的元素被设置为 0。
| |
此 ST1H 指令执行 predicated 连续 halfword 的存操作,它将 ZA1 中列号为(W0+imm)的垂直 tile slice 存到地址为(X1+X2*2)的内存, tile slice 中 Inactive 的元素不写入内存。
# 7.4.2 Tile slice move 指令
MOV 指令(MOVA 指令的别名)将一个 Z 向量寄存器的值移动到一个 ZA tile slice,或将一个 ZA tile slice 中的值移动到一个 Z 向量寄存器。这条指令操作带指定元素大小的 ZA tile 的单个水平或垂直 tile slice。 Slice 的行号/列号由 slice 的检索寄存器加上立即数偏移指定。目标 slice 中 Inactive 的元素保持不变。
例如:
| |
或
| |
此指令将向量寄存器 Z0.B 中的值移动到 ZA0H.B[W0,#imm] 这个水平 ZA tile slice 中,使用 P0 作为 predication 寄存器。目标 tile slice 中 Inactive 的元素保持不变。
# 7.5 ZA array vector load/store 指令
SME LDR 指令从内存读取数据到一个 ZA array 向量,SME STR 指令将一个 ZA array 向量中的值存入内存。 这些指令是不带 predication 功能的。它们主要是为了软件的 context switching 时对 ZA storage 进行 save/restore。SME LDR/STR 指令也可以在 Non-streaming SVE 模式下,当 PSTATE.ZA 使能的情况下使用。 例如,下面的 STR 指令的 ZA array 向量是由一个向量选择寄存器 Wv(标量寄存器 W)加上可选的立即数(Wv+Imm)指定。访问内存的地址为:一个标量寄存器作为 base,加上相同的可选立即数偏移乘以当前向量长度 byte 数。
| |
# 7.6 ZA tile 清零指令
SME ZERO 指令可以清零一组 64-bit ZA tile:
| |
ZERO 指令可以清零多到 8 个名为 ZA0.D 到 ZA8.D 的 ZA tile,那些 tile 要清零由指令中的 mask 指定,剩下的其他 tile 保持不变。
这条指令也可以在 Non-streaming SVE 模式,当 PSTATE.ZA 开启的情况下使用。
如果要清零整个 ZA array, 可以使用一个指令别名,ZERO {ZA} 。
# 7.7 新的 SVE2 指令
SME 构架扩展加入了一些新的 SVE2 指令,这些指令也可以在 PE 实现了 SVE2, 处于 Non-streaming SVE 模式时使用。这些指令包括:
- 选择一个 predicate 寄存器或是 all-false 的 Predicate select 指令
- 翻转(Reverse)64-bit double word 元素的指令
- 有符号/无符号钳位为更小/更大值向量的指令
下面介绍以下 Predicate select 指令。
# 7.7.1 PSEL 指令
PSEL 指令选择一个 predicate 寄存器复制到到目标 predicate 寄存器或者将目标 predicate 寄存器设置为全零(all-false),如下所示:
| |
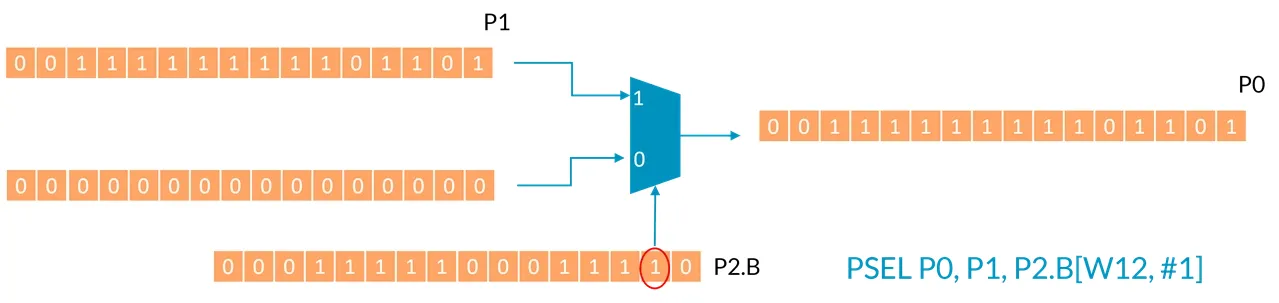
如果指令中 Pm 寄存器中对应索引位置的元素为 True, 这条指令将 Pn 寄存器的内容放到目标寄存器 Pd 中, 否则设置 Pd 寄存器的值全部为 False。 例如以下指令,假设 W12 为 0:
| |
P2.B[W12 + 0] ,即 P2.B[0] 为 False, 因此目标寄存器 P0 被全部设置为 0(all-false),如下图所示:

现在看看如下指令,仍然假设 W12 为 0 ,但这次立即数偏移量(就是硬编码的偏移量)为 1:
| |
P2.B[W12 + 1] ,即 P2.B[1] 为 True, 因此选择将 P1 寄存器的值复制到目标寄存器 P0,如下图所示: