
This article welcomes non-commercial reprints, please indicate the source when reprinting.
Declaration: For collection only, for easy reading.
― Savir, Zhihu Column: 1. RDMA Overview
I originally intended to complete this overview entirely in my own language, but the beginning was not as easy to write as I imagined. It seems that summarizing a technology from a macro perspective is much more difficult than exploring the details from a micro perspective. This article mainly introduces RDMA technology based on previous people’s explanations, along with some of my own understanding. As the content of this column increases, this overview will also be updated and gradually improved.
# What is DMA
DMA stands for Direct Memory Access, meaning that the process of reading and writing to memory by peripherals can be done directly without the involvement of the CPU. Let’s first take a look at what happens without DMA:
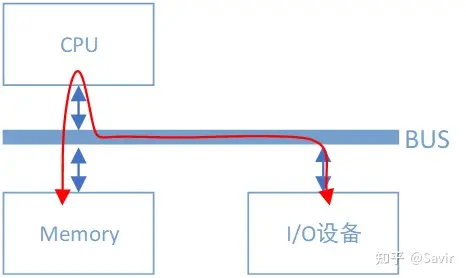
Data path between I/O devices and memory without DMA controller
Assuming the I/O device is a regular network card, in order to retrieve the data to be sent from memory, assemble the data packet, and send it to the physical link, the network card needs to inform the CPU of its data request via the bus. The CPU will then copy the data from the memory buffer to its internal registers, and then copy it to the I/O device’s storage space. If the amount of data is large, the CPU will be busy transferring data for a long time and will not be able to engage in other tasks.
The primary job of the CPU is computation, not data copying, which is a waste of its computational capabilities. To “lighten the load” on the CPU and allow it to focus on more meaningful tasks, the DMA mechanism was later designed:
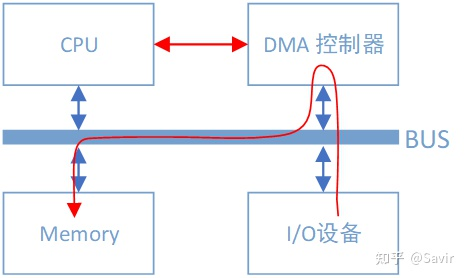
Data path between I/O devices and memory with DMA controller
You can see that there is another DMA controller attached to the bus, which is specifically used for reading and writing memory devices. With it, when our network card wants to copy data from memory, apart from some necessary control commands, the entire data copying process is completed by the DMA controller. The process is the same as CPU copying, except this time the data in the memory is copied through the bus to the registers inside the DMA controller, and then copied to the storage space of the I/O device. Apart from paying attention to the start and end of this process, the CPU can do other things during the rest of the time.
DMA controllers are generally together with I/O devices, which means that a network card has both a module responsible for data transmission and reception, as well as a DMA module.
# What is RDMA
RDMA (Remote Direct Memory Access) means remote direct memory access, through RDMA, the local node can “directly” access the memory of the remote node. The so-called direct means that it can read and write remote memory like accessing local memory, bypassing the complex TCP/IP network protocol stack of traditional Ethernet, and this process is not perceived by the other end. Moreover, most of the work in this read and write process is done by hardware rather than software.
In order to intuitively understand this process, please look at the two diagrams below (the arrows in the diagrams are for illustration only and do not indicate actual logical or physical relationships):
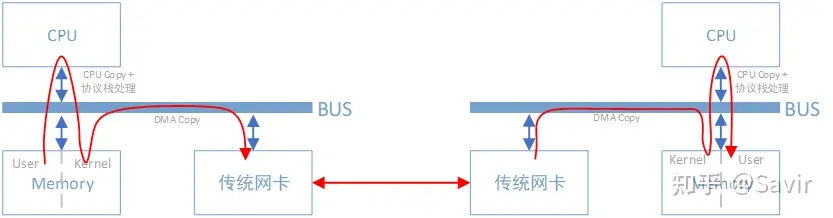
In traditional networks, “node A sends a message to node B” actually involves “transferring a segment of data from node A’s memory to node B’s memory through the network link.” This process, whether at the sending or receiving end, requires CPU direction and control, including control of the network card, handling of interrupts, packet encapsulation, and parsing, among other tasks.
The data in the user space memory on the left node in the figure needs to be copied by the CPU to the buffer in the kernel space before it can be accessed by the network card. During this process, the data will pass through the software-implemented TCP/IP protocol stack, adding headers and checksums for each layer, such as the TCP header, IP header, etc. The network card uses DMA to copy the data from the kernel into the network card’s internal buffer, processes it, and then sends it to the peer through the physical link.
After the peer receives the data, it will perform the opposite process: from the internal storage space of the network card, the data is copied to the buffer in the memory kernel space via DMA, then the CPU parses it through the TCP/IP protocol stack and extracts the data to copy it into the user space.
You can see that even with DMA technology, the above process still heavily relies on the CPU.
After using RDMA technology, this process can be simply represented by the following diagram:
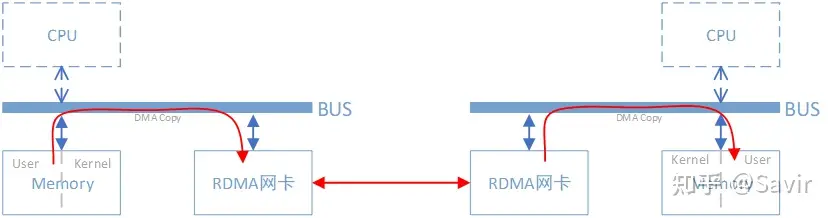
Similarly, when copying a segment of data from local memory to remote memory using RDMA technology, the CPUs on both ends hardly participate in the data transmission process (only in the control plane). The local network card directly copies data from the user space in memory to its internal storage space via DMA, then the hardware assembles the various layers of the packet and sends it to the remote network card through the physical link. After the remote RDMA network card receives the data, it strips off the packet headers and checksums at each layer and directly copies the data into user space memory via DMA.
# Advantages of RDMA
RDMA is mainly used in the field of high-performance computing (HPC) and large data centers, and the equipment is relatively more expensive than ordinary Ethernet cards (for example, Mellanox’s Connext-X 5 100Gb PCIe network card is priced above 4000 yuan). Due to the usage scenarios and price, RDMA is relatively distant from ordinary developers and consumers, and is currently mainly deployed and used by some large internet companies.
Why can RDMA technology be applied in the above scenarios? This involves the following characteristics:
- 0 Copy: Refers to not needing to copy data back and forth between user space and kernel space.
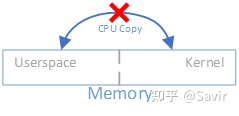
Due to operating systems like Linux dividing memory into user space and kernel space, in the traditional Socket communication process, the CPU needs to copy data back and forth in memory multiple times. However, through RDMA technology, we can directly access the remote registered memory area.
Regarding 0 copy, you can refer to this article: A Brief Discussion on Zero Copy Mechanism in Linux
- Kernel Bypass: Refers to the IO (data) process being able to bypass the kernel, meaning data can be prepared at the user level and notify the hardware to get ready for sending and receiving. This avoids the overhead of system calls and context switching.
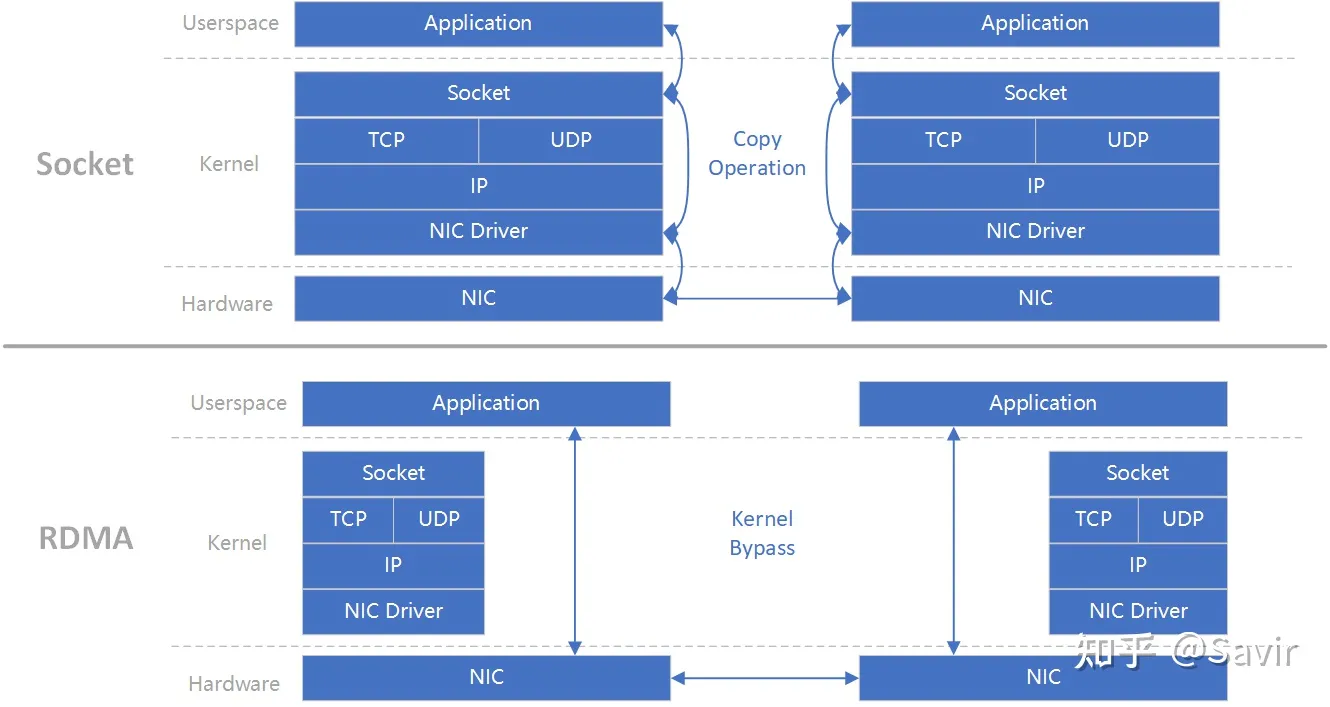
The above figure (original figure [1] ) can effectively explain the meaning of “0 copy” and “kernel Bypass”. The upper and lower parts are respectively a send-receive process based on Socket and RDMA, and the left and right are two nodes. It is obvious that in the Socket process, there is an additional copy action in the software. In contrast, RDMA bypasses the kernel and also reduces memory copying, allowing data to be transferred directly between the user layer and hardware.
- CPU Offloading: Refers to the ability to read and write memory without the remote node’s CPU participating in the communication (of course, you need to have the “key” to access a certain segment of the remote memory). This essentially means encapsulating and parsing packets in hardware. In traditional Ethernet communication, the CPUs on both sides must participate in the parsing of each layer of the packet. If the data volume is large and the interaction is frequent, it will be a considerable overhead for the CPU, and these occupied CPU computing resources could have been used for more valuable work.
The two most frequently appearing performance indicators in the field of communication are “bandwidth” and “latency.” Simply put, bandwidth refers to the amount of data that can be transmitted per unit of time, while latency refers to the time it takes for data to be sent from the local end to be received by the remote end. Due to the above characteristics, compared to traditional Ethernet, RDMA technology achieves higher bandwidth and lower latency, allowing it to play a role in bandwidth-sensitive scenarios—such as massive data interactions, and latency-sensitive scenarios—such as data synchronization between multiple computing nodes.
# Agreement
RDMA itself refers to a technology. On the specific protocol level, it includes Infiniband (IB), RDMA over Converged Ethernet (RoCE), and internet Wide Area RDMA Protocol (iWARP). All three protocols comply with the RDMA standard, use the same upper-layer interface, and have some differences at different levels.
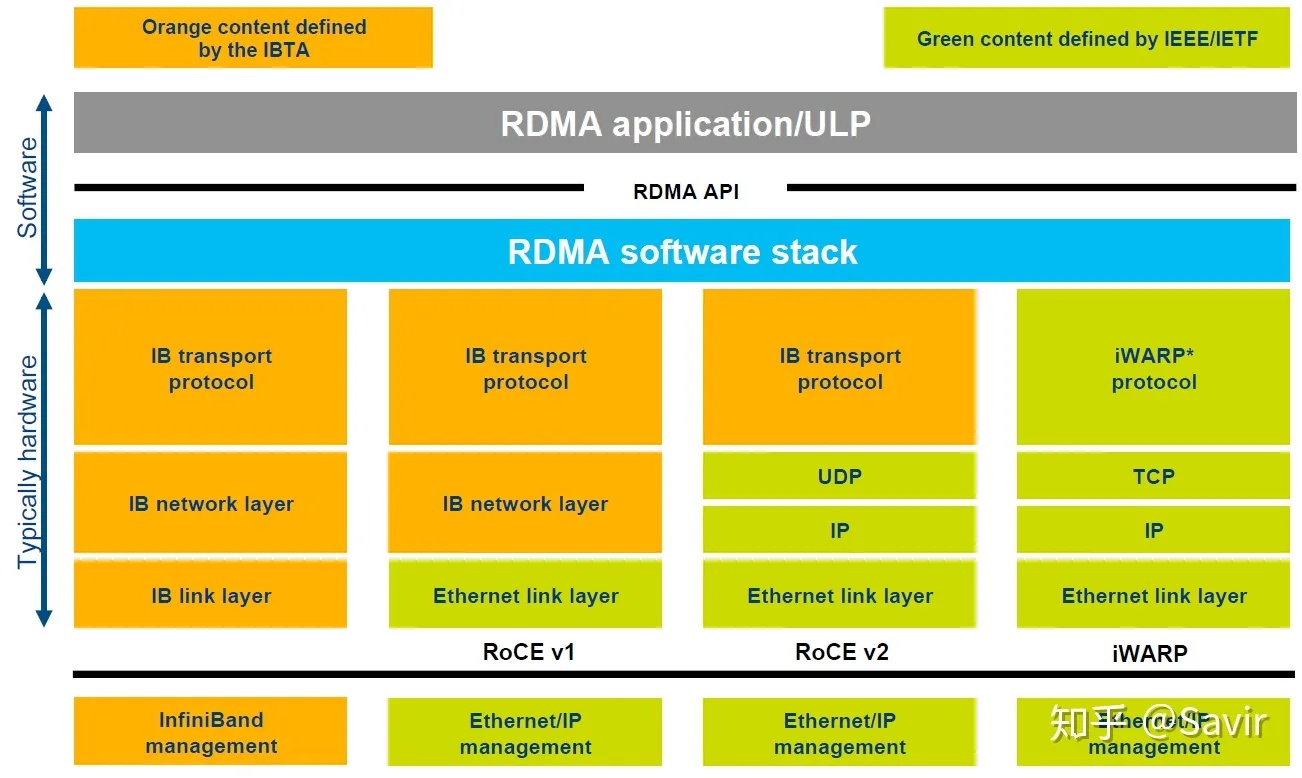
The image above [2]g provides a very clear comparison of the protocol layers for several common RDMA technologies.
# Infiniband
The IB protocol proposed by IBTA (InfiniBand Trade Association) in 2000 is undoubtedly the core, as it specifies a complete set of link layer to transport layer (not the traditional OSI seven-layer model’s transport layer, but one that is above it) standards. However, it is not compatible with existing Ethernet; besides needing network cards that support IB, companies would also need to purchase matching switching equipment if they want to deploy it.
# RoCE
From the full English name of RoCE, it can be seen that it is a protocol based on the Ethernet link layer. The v1 version still used the IB specification for the network layer, while v2 uses UDP+IP as the network layer, allowing data packets to be routed. RoCE can be considered as a “low-cost solution” for IB, encapsulating IB messages into Ethernet packets for sending and receiving. Since RoCE v2 can use Ethernet switching devices, it is now more commonly used in enterprises, but compared to IB, there is some performance loss in the same scenarios.
# iWARP
The iWARP protocol is proposed by IETF based on TCP, because TCP is a connection-oriented reliable protocol. This makes iWARP more reliable in lossy network scenarios (which can be understood as network environments where packet loss may frequently occur) compared to RoCE v2 and IB, and it also has significant advantages in large-scale networking. However, a large number of TCP connections consume a lot of memory resources, and the complex flow control mechanisms of TCP can lead to performance issues, so in terms of performance, iWARP is inferior to UDP’s RoCE v2 and IB.
It should be noted that although there are software implementations of RoCE and iWARP protocols, in actual commercial use, the above protocols all require dedicated hardware (network cards) support.
iWARP itself did not directly evolve from Infiniband, but it inherited some design concepts from Infiniband technology. The relationship between these three protocols is shown in the diagram below:
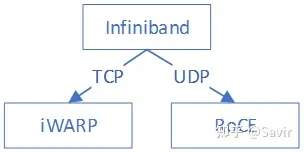
# Player
# Standard/Ecological Organization
Speaking of the IB protocol, we must mention two major organizations - IBTA and OFA.
# IBTA[3]
Founded in 1999, responsible for developing and maintaining the Infiniband protocol standards. IBTA is independent of various manufacturers, integrating the entire industry through sponsoring technical activities and promoting resource sharing, and actively promoting IB and RoCE through online communication, marketing, and offline activities.
IBTA will conduct protocol standard compliance and interoperability testing and certification for commercial IB and RoCE devices, led by a committee composed of many large IT manufacturers. Its main members include Broadcom, HPE, IBM, Intel, Mellanox, and Microsoft, among others. Huawei is also a member of IBTA.
# OFA[4]
A non-profit organization established in 2004 is responsible for developing, testing, certifying, supporting, and distributing a vendor-independent open-source cross-platform InfiniBand protocol stack, and started supporting RoCE in 2010. It is responsible for the OFED (OpenFabrics Enterprise Distribution) software stack used to support RDMA/Kernel bypass applications, ensuring its compatibility and ease of use with mainstream software and hardware. The OFED software stack includes drivers, kernel, middleware, and APIs.
The two organizations mentioned above have a cooperative relationship. IBTA is mainly responsible for developing, maintaining, and enhancing the Infiniband protocol standards; OFA is responsible for developing and maintaining the Infiniband protocol and upper-layer application APIs.
# Developer community
# Linux Community
The RDMA subsystem of the Linux kernel is relatively active, frequently discussing protocol details, and modifications to the framework are quite frequent. Additionally, some vendors, including Huawei and Mellanox, often make changes to the driver code.
Email subscription: http://vger.kernel.org/vger-lists.html#linux-rdma
The code is located in the kernel’s drivers/infiniband/ directory, including the framework core code and the driver code from various vendors.
Code repository: https://git.kernel.org/pub/scm/linux/kernel/git/rdma/rdma.git/
# RDMA Community
For upper-layer users, IB provides an interface similar to Socket sockets—libibverbs, and all three protocols mentioned earlier can be used. Referring to the protocol, API documentation, and sample programs, it is easy to write a demo. The RDMA community referred to in this column specifically refers to its user-space community, and its repository on GitHub is named linux-rdma.
Mainly contains two sub-repositories:
- rdma-core
User-mode core code, API, documentation, and user-mode drivers from various vendors.
- perftest A powerful tool for testing RDMA performance.
Code repository: https://github.com/linux-rdma/
# UCX[5]
UCX is a communication framework built on technologies such as RDMA for data processing and high-performance computing, with RDMA being one of its core components. We can understand it as middleware positioned between applications and the RDMA API, providing an additional layer of interfaces that are easier for upper-level users to develop with.
The author does not know much about it, only that there are some companies in the industry developing applications based on UCX.
Code repository: https://github.com/openucx/ucx
# Hardware manufacturer
There are many manufacturers that design and produce IB-related hardware, including Mellanox, Huawei, Intel which acquired Qlogic’s IB technology, Broadcom, Marvell, Fujitsu, etc. We won’t go into each one here, just briefly mention Mellanox and Huawei.
Mellanox The leader in the IB field, Mellanox is visible in protocol standard setting, software and hardware development, and ecosystem construction, holding the greatest influence in the community and standard setting. The latest generation of network cards currently is the ConnextX-6 series, which supports 200Gb/s.
Huawei The Kunpeng 920 chip, launched early last year, already supports the 100Gb/s RoCE protocol, and is technically leading in China. However, in terms of software, hardware, and influence, there is still a long way to go compared to Mellanox. I believe Huawei will catch up with the big brother soon.
# User
Microsoft, IBM, and domestic companies like Alibaba and JD are using RDMA, and many other large IT companies are also conducting initial development and testing. In data centers and high-performance computing scenarios, RDMA replacing traditional networks is an inevitable trend. The author does not have much exposure to the market, so cannot provide more detailed application information.
The next article will compare a typical Socket-based traditional Ethernet and RDMA communication process in a more intuitive way.