
This article welcomes non-commercial reprints, please indicate the source when reprinting.
Statement: For collection only, for easy reading
― Savir, Zhihu Column: 8. RDMA Address Handle
It has already been introduced that the basic unit of RDMA communication is the QP. Let’s consider a question: Suppose a QP on node A wants to exchange information with a QP on node B. Besides knowing the QP number—QPN—of node B, what other information is needed? It should be noted that the QPN is a number maintained independently by each node and is not unique across the entire network. For instance, if QP 3 on A wants to communicate with QP 5 on B, there is not just one QP5 in the network; many nodes might have their own QP 5. Therefore, we can naturally think of the need to find a way for each node to have a unique identifier.
In the traditional TCP-IP protocol stack, the well-known IP address is used to identify each node at the network layer. In the IB protocol, this identifier is called the GID (Global Identifier), which is a 128-bit sequence. This article will not discuss GID in detail and will introduce it later.
# What is AH
AH stands for Address Handle. I couldn’t think of a particularly suitable Chinese translation, so let’s directly translate it as “地址句柄” for now. The address here refers to a set of information used to locate a remote node. In the IB protocol, the address refers to information such as GID, port number, etc. As for the so-called handle, we can understand it as a pointer to an object.
Does everyone still remember that there are four basic service types in the IB protocol—RC, UD, RD, and UC, with RC and UD being the most commonly used. The characteristic of RC is that a reliable connection is established between the QPs of two nodes, and once the connection is established, it is not easily changed. The information of the peer is stored in the QP Context when creating the QP.
As for UD, there is no connection relationship between QPs. The user can fill in the peer’s address information in the WQE for whoever they want to send to. The user does not directly fill the peer’s address information into the WQE but prepares an “address book” in advance, specifying the peer node’s address information each time through an index, which is the AH.
The concept of AH can be roughly represented by the diagram below:
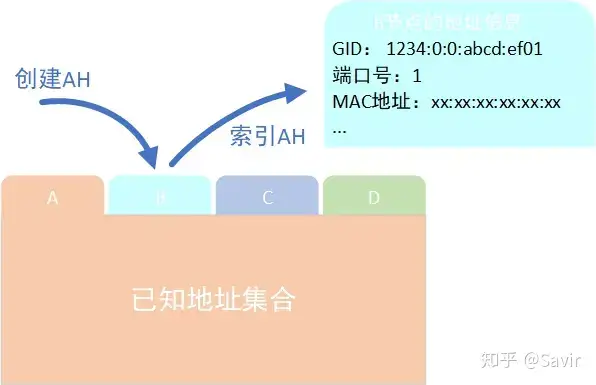
Address Handle Function Diagram
For each destination node, a corresponding AH will be created at this end, and the same AH can be shared by multiple QPs.
# The role of AH
Before each communication of the UD service type, the user needs to first use the interface provided by the IB framework to create an AH for each possible peer node, then these AHs are driven into a “secure” area, and an index (pointer/handle) is returned to the user. When the user actually issues a WR (Work Request), they just need to pass in this index.
The above process is shown in the diagram below. Node A receives a task from the user to exchange data using its QP4 with Node B’s QP3 (specified through AH):
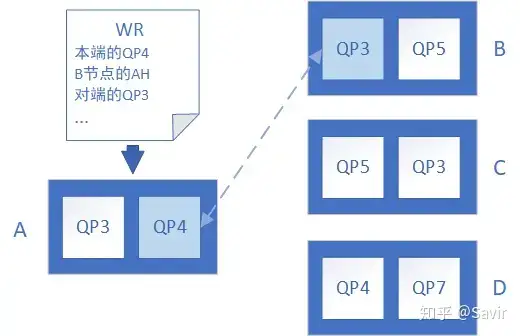
UD service type uses AH to specify peer node
The IB protocol does not explain why AH is used. I believe there are three reasons for defining the concept of AH:
- Ensure the destination address is available, improve efficiency
Due to the connectionless nature of UD, users can directly specify the destination through WR in user mode. However, if users are allowed to fill in address information at will, and then hardware packages the data according to this information, it may lead to problems. For example, there is a scenario like this: a user tells the hardware through WR to send data to port Z of a node with GID X and MAC address Y. However, X, Y, and Z may not be a valid combination, or a node with GID X may not even exist in the network, and the hardware is unable to verify this content, so it can only obediently package and send the data. This results in the unnecessary sending of a data packet to an invalid destination.
And preparing the address information in advance can avoid the above situation. When the user creates AH, they will enter kernel mode. If the parameters passed by the user are valid, the kernel will store this destination node information, generate a pointer, and return it to the user; if the parameters passed by the user are invalid, AH creation will fail. This process ensures that the address information is valid. The user can quickly specify the destination node through the pointer, speeding up the data interaction process.
Some may ask, since the kernel is trusted, why not switch to kernel mode to verify the address information passed by the user when sending data? Please do not forget where one of the major advantages of RDMA technology lies—the data flow can go directly from user space to hardware, completely bypassing the kernel, thus avoiding the overhead of system calls and copying. If the legality of the address has to be checked every time data is sent, it will inevitably reduce the communication rate.
- Hide underlying address details from the user
When the user creates AH, they only need to provide information such as gid, port number, static rate, etc., while other address information required for communication (mainly MAC addresses) is resolved by the kernel driver through querying the system neighbor table and other methods. There is no need to expose this additional information to the user layer.
- You can use PD to manage the destination address.
In the previous text, when we introduced protection domains, we mentioned that besides QP and MR, AH is also resource partitioned by PD. Once the software entity AH is defined, we can isolate and manage all destinations reachable by QP.
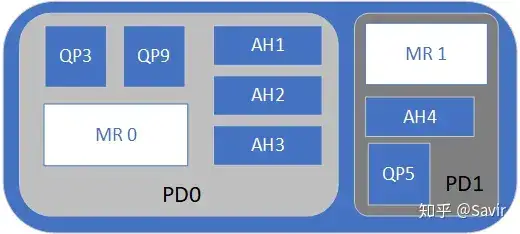
Use PD to isolate AH
For example, in the image above, AH1~3 can only be used by QP3 and QP9 under the same PD, while AH4 can only be used by QP5.
# Relevant sections of the agreement
There is not much coverage about AH in the agreement, and there is not even a chapter dedicated to introducing its concept:
[1] 9.8.3 What components make up the destination address in UD service type: including AH, QPN, and Q_key
[2] 10.2.2.2 Relevant Considerations for the Destination Address
[3] 11.2.2.1 AH Related Verbs Interface
AH is introduced here, thank you for reading. In the next article, I plan to describe more details about QP.