
# 1. SVE Introduction
After the Neon architecture extension with a fixed 128-bit vector length instruction set, Arm designed the Scalable Vector Extension (SVE) as the next-generation SIMD extension for AArch64. SVE introduces the scalable concept, allowing flexible vector length implementations and providing a range of possible values in CPU implementations. The vector length can vary from a minimum of 128 bits to a maximum of 2048 bits, in increments of 128 bits. The SVE design ensures that the same application can run on different SVE-supporting implementations without recompiling the code. SVE enhances the architecture’s applicability to high-performance computing (HPC) and machine learning (ML) applications, which require very large amounts of data processing. SVE2 is a superset of SVE and Neon. SVE2 allows the use of more functional domains in data-level parallelism. SVE2 inherits the concepts, vector registers, and operation principles of SVE. SVE and SVE2 define 32 scalable vector registers. Chip partners can choose an appropriate vector length design implementation, with hardware varying between 128 bits and 2048 bits (in increments of 128 bits). The advantage of SVE and SVE2 is that only one vector instruction set uses scalable variables.
The SVE design philosophy allows developers to write and build software once, and then run the same binary on different AArch64 hardware with various SVE vector length implementations. The portability of the binary means developers do not need to know the vector length implementation of their system. This eliminates the need to rebuild the binary, making the software easier to port. In addition to scalable vectors, SVE and SVE2 also include:
- per-lane predication
- Gather Load/Scatter Store
- Speculative Vectorization
These features help vectorize and optimize loops when dealing with large datasets.
The main difference between SVE2 and SVE lies in the functional coverage of the instruction set. SVE is specifically designed for HPC and ML applications. SVE2 extends the SVE instruction set to enable accelerated data processing in areas beyond HPC and ML. The SVE2 instruction set can also accelerate common algorithms used in the following applications:
- Computer Vision
- Multimedia
- LTE Basic Processing
- Genomics
- In-memory database
- Web Service
- General software
SVE and SVE2 both support collecting and processing large amounts of data. SVE and SVE2 are not extensions of the Neon instruction set. Instead, SVE and SVE2 are redesigned to offer better data parallelism than Neon. However, the hardware logic of SVE and SVE2 covers the implementation of Neon hardware. When a microarchitecture supports SVE or SVE2, it also supports Neon. To use SVE and SVE2, the software running on that microarchitecture must first support Neon.
# 2. SVE Architecture Basics
This section introduces the basic architectural features shared by SVE and SVE2. Like SVE, SVE2 is also based on scalable vectors. In addition to the existing register file provided by Neon, SVE and SVE2 add the following registers:
- 32 scalable vector registers,
Z0-Z31 - 16 scalable Predicate registers,
P0-P15- 1 First Fault Predicate register,
FFR
- 1 First Fault Predicate register,
- Scalable Vector System Control Register,
ZCR_ELx
# 2.1 Scalable Vector Registers
Scalable vector registers Z0-Z31 can be implemented in microarchitecture as 128-2048 bits. The lowest 128 bits are shared with Neon’s fixed 128-bit vectors V0-V31.
The image below shows scalable vector registers Z0-Z31:
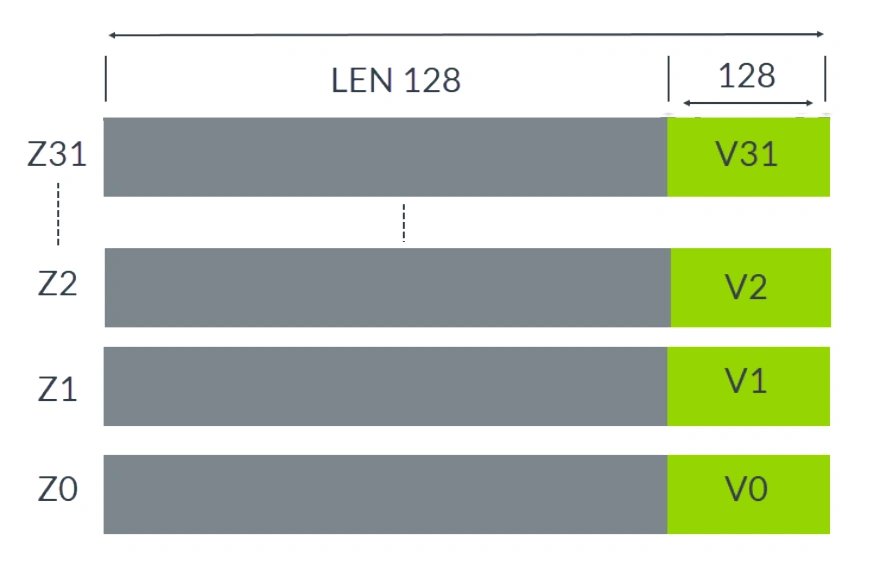
Scalable Vector Registers Z0-Z31
Scalable Vector:
- Can accommodate 64, 32, 16, and 8-bit elements
- Supports integer, double precision, single precision, and half precision floating-point elements
- The vector length can be configured for each exception level (EL)
# 2.2 Scalable Predicate Register
In order to control which active elements participate in operations, Predicate registers (abbreviated as P registers) are used as masks in many SVE instructions, which also provides flexibility for vector operations. The figure below shows the scalable Predicate registers P0-P15:
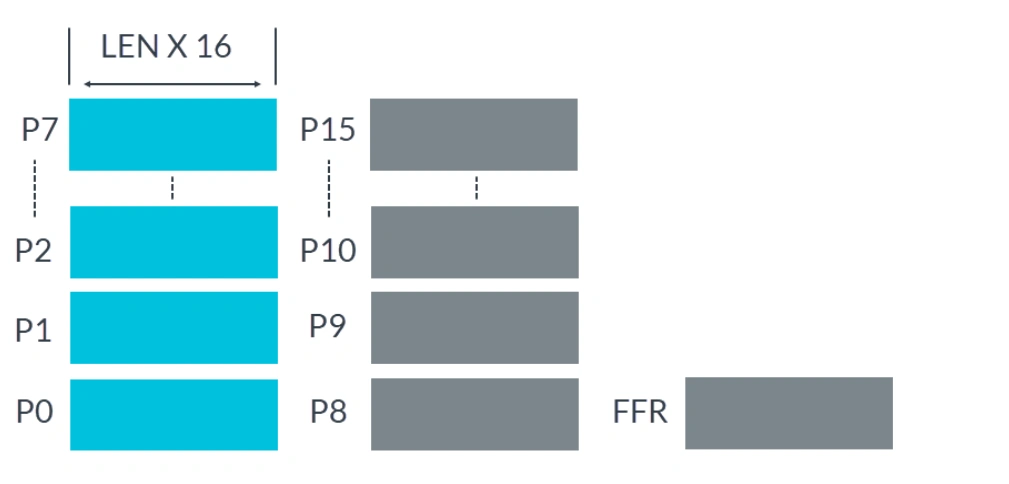
Scalable Predicate Registers P0-P15
The P register is typically used as a bitmask for data manipulation:
- Each P register is 1/8 the length of a Z register
P0-P7are used for loading, storing, and arithmetic operationsP8-P15used for loop management- FFR is a special P register set by the first-fault vector load and store instructions, used to indicate the success of load and store operations for each element. FFR is designed to support speculative memory access, making vectorization easier and safer in many cases.
# 2.3 Scalable Vector System Control Register
The figure below shows the Scalable Vector System Control Register ZCR_ELx:

Scalable Vector System Control Register ZCR_Elx
Scalable Vector System Control Register indicates SVE implementation features:
ZCR_Elx.LENfield is used for the vector length of the current and lower anomaly levels.- Most bits are currently reserved for future use.
# 2.4 SVE Assembly Syntax
The SVE assembly syntax format consists of an opcode, destination register, P register (if the instruction supports a Predicate mask), and input operands. The following instruction example will detail this format.
Example 1:
| |
Among them:
<Zt>is the Z register,Z0-Z31<Zt>.D and<Zm>.D specify the element type of the target and operand vectors, without needing to specify the number of elements.<Pg>is the P register,P0-P15<Pg>/Zis to zero the P register.<Zm>specifies the offset for the Gather Load address mode.
Example 2:
| |
Among them:
<Pg>/Mis the merge P register.<Zdn>is both the destination register and one of the input operands. The instruction syntax shows<Zdn>in both places for convenience. In the assembly encoding, for simplification, they are only encoded once.
Example 3:
| |
Sis the new interpretation of the P register condition flagsNZCV.<Pg>controls the P register to act as a bitmask in the example operation.
# 2.5 SVE Architecture Features
SVE includes the following key architectural features:
- per-lane predication
In order to allow flexible operations on selected elements, SVE introduces 16 P registers, P0-P15, to indicate valid operations on vector active channels. For example:
| |
Add the active elements Z0 and Z1 and place the result in Z0. P0 indicates which elements of the operands are active and inactive. The M following P0 stands for Merging, meaning the inactive elements of Z0 will retain their initial values after the ADD operation. If Z follows P0, the inactive elements will be zeroed, and the inactive elements of the destination register will be zeroed after the operation.
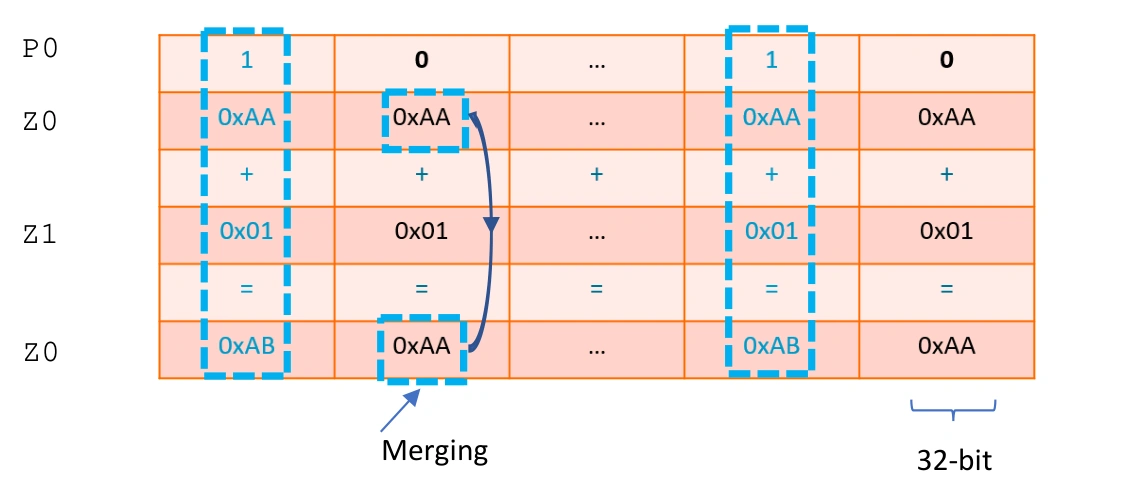
Per-lane predication merging
If \Z is used, the inactive elements will be zeroed, and the inactive elements of the target register will be zeroed after the operation. For example
| |
Indicates that the signed integer 0xFF will be copied to the active channel of Z0, while the inactive channels will be cleared.

Per-lane predication zeroing
Note
Not all instructions have the Predicate option. Additionally, not all Predicate operations have both merge and zeroing options. You must refer to the AArch64 SVE Supplement to understand the specification details of each instruction.
- Gather Load and Scatter Store
The addressing modes in SVE allow vectors to be used as base addresses and offsets in Gather Load and Scatter Store instructions, which enables access to non-contiguous memory locations. For example:
| |
The following example shows the load operation LD1SB Z0.S, P0/Z, [Z1.S], where P0 contains all true elements, and Z1 contains scattered addresses. After loading, the least significant byte of each element in Z0.S will be updated with data fetched from scattered memory locations.
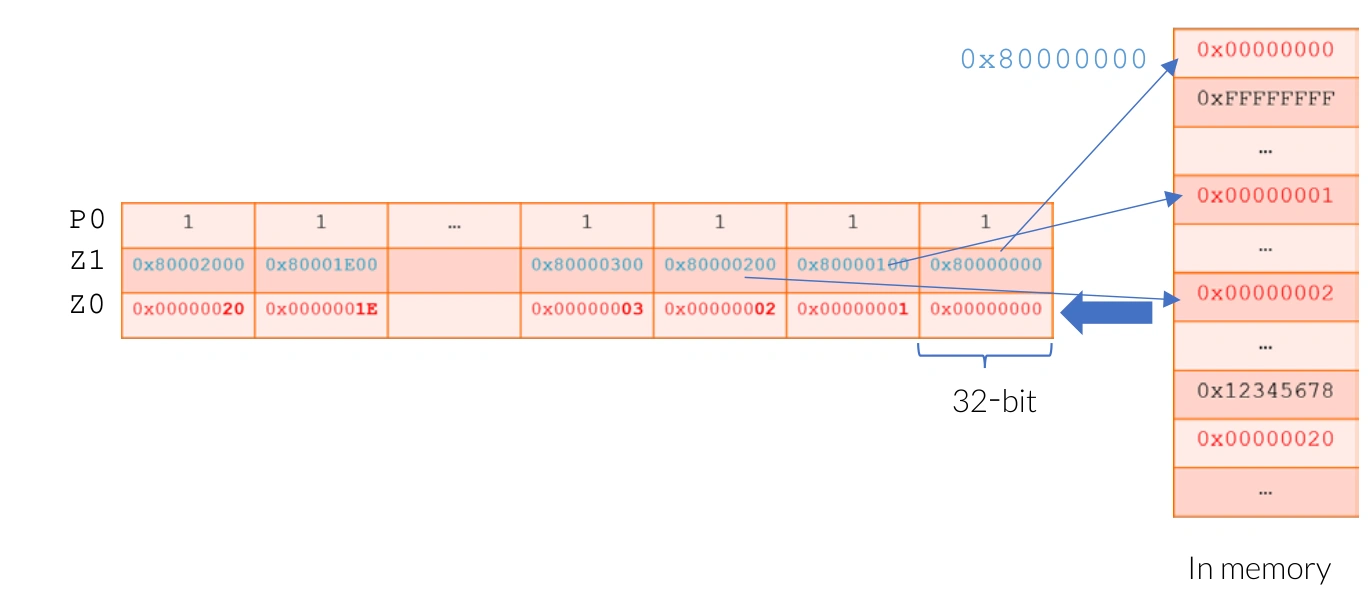
Gather-load and Scatter-store Example
- Loop control and management of the P register driver
As a key feature of SVE, the P register not only flexibly controls individual elements of vector operations but also enables P register-driven loop control. P register-driven loop control and management make loop control efficient and flexible. This feature eliminates the overhead of extra loop heads and tails for processing partial vectors by registering active and inactive element indices in the P register. P register-driven loop control and management mean that in the subsequent loop iterations, only active elements will perform the intended operations. For example:
| |
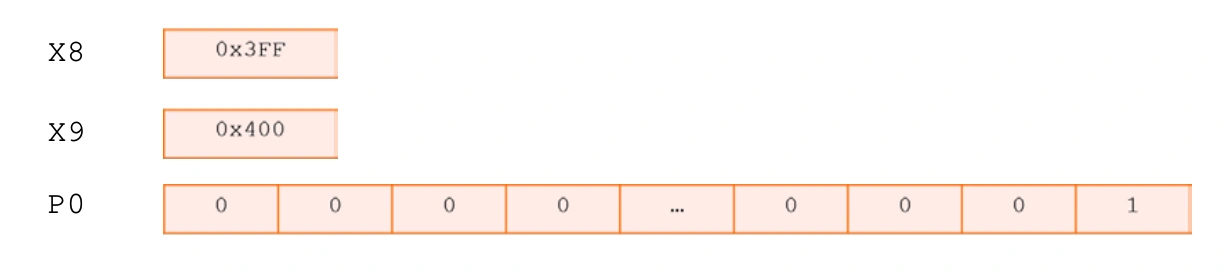
Example of loop control and management driven by P register
- Vector partitioning for speculation in software management
Speculative loading can pose challenges for memory reading of traditional vectors, if errors occur in certain elements during the reading process, it is difficult to reverse the load operation and track which elements failed to load. Neon does not allow speculative loading. To allow speculative loading of vectors (e.g., LDRFF), SVE introduces the first-fault vector load instruction. To allow vector access across invalid pages, SVE also introduces the FFR register. When using the first-fault vector load instruction to load into an SVE vector, the FFR register updates with the success or failure result of each element’s load. When a load error occurs, FFR immediately registers the corresponding element, registers the remaining elements as 0 or false, and does not trigger an exception. Typically, the RDFFR instruction is used to read the FFR status. The RDFFR instruction ends iteration when the first element is false. If the first element is true, the RDFFR instruction continues iteration. The length of FFR is the same as the P vector. This value can be initialized using the SETFFR instruction. The following example uses LDFF1D to read data from memory, and FFR is updated accordingly:
| |
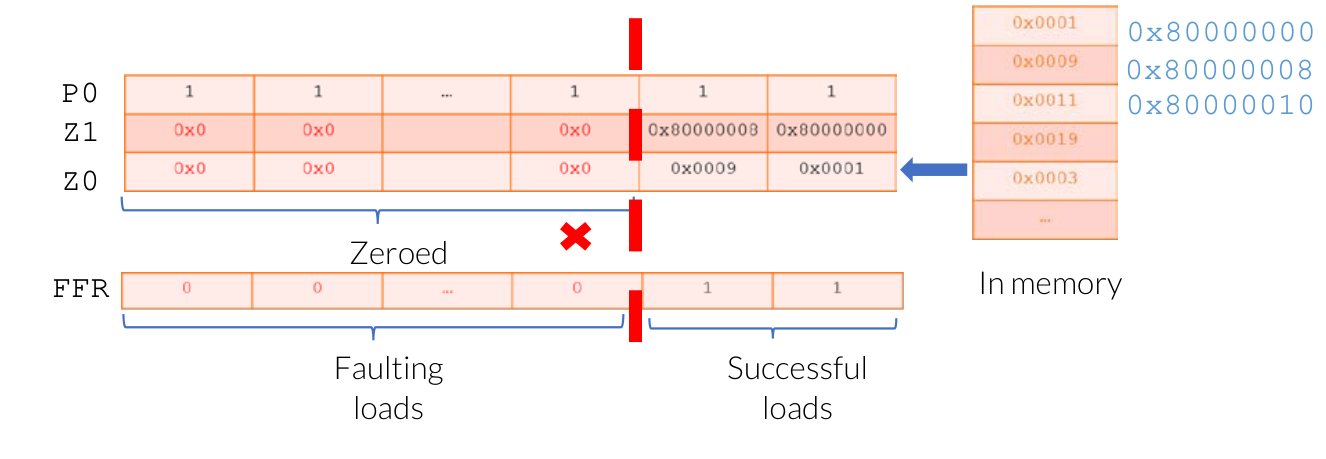
Example of Vector Partitioning for Software-Managed Speculation
- Extended floating point and horizontal reduction
In order to allow efficient reduction operations in vectors and meet different precision requirements, SVE enhances floating-point and horizontal reduction operations. These instructions may have a sequential (low to high) or tree-based (pairwise) floating-point reduction order, where the order of operations may lead to different rounding results. These operations require a trade-off between reproducibility and performance. For example:
| |
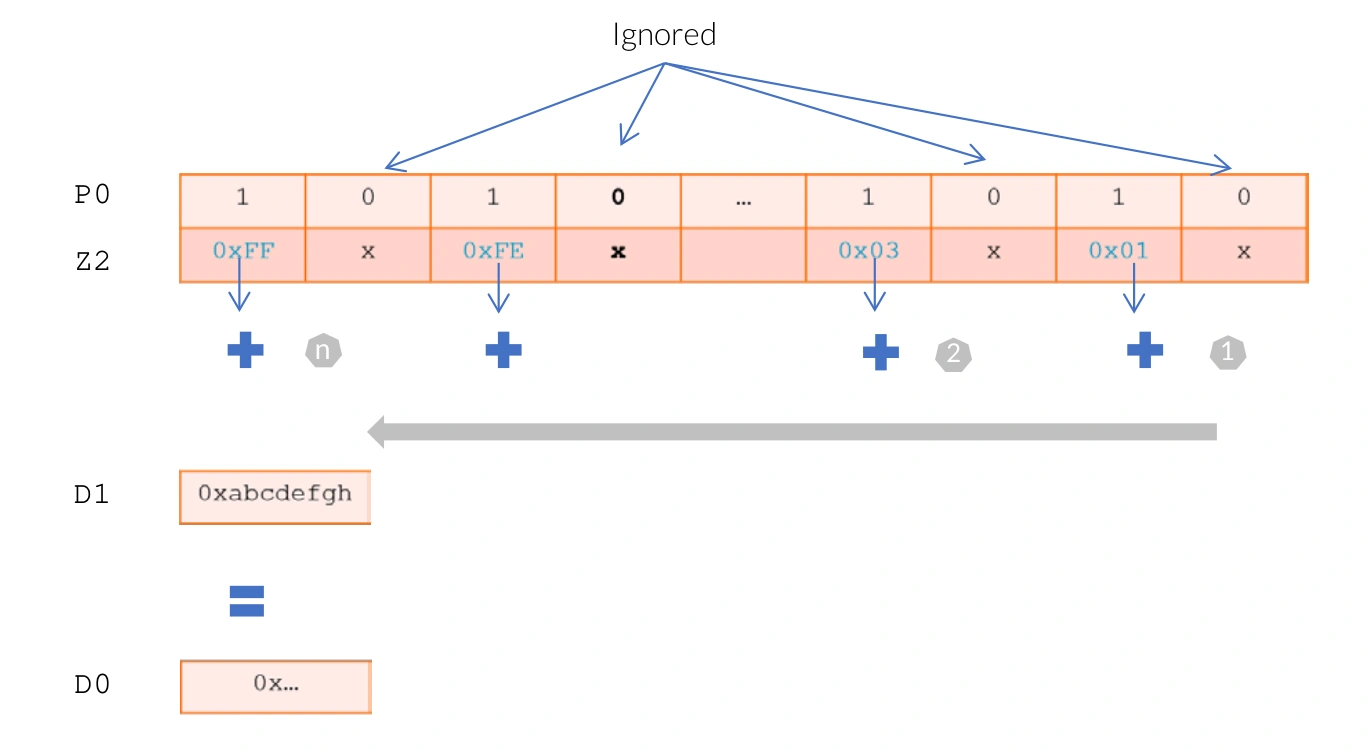
Extended Floating-point and Horizontal Reductions Example
# 3. New Features of SVE2
This section introduces the features added by SVE2 to the Arm AArch64 architecture. To achieve scalable performance, SVE2 is built on SVE, allowing vectors to reach up to 2048 bits.
In SVE2, many instructions that replicate existing instructions in Neon have been added, including:
- Converted Neon integer operations, for example, Signed Absolute Difference Accumulate (SAB) and Signed Halving Add (SHADD).
- Converted Neon extensions, narrowing and paired operations, for example, Unsigned Add Long - Bottom (UADDLB) and Unsigned Add Long - Top (UADDLT).
The order of element processing has changed. SVE2 processes interleaved even and odd elements, while Neon processes the low half and high half elements of narrow or wide operations. The diagram below illustrates the difference between Neon and SVE2 processing:
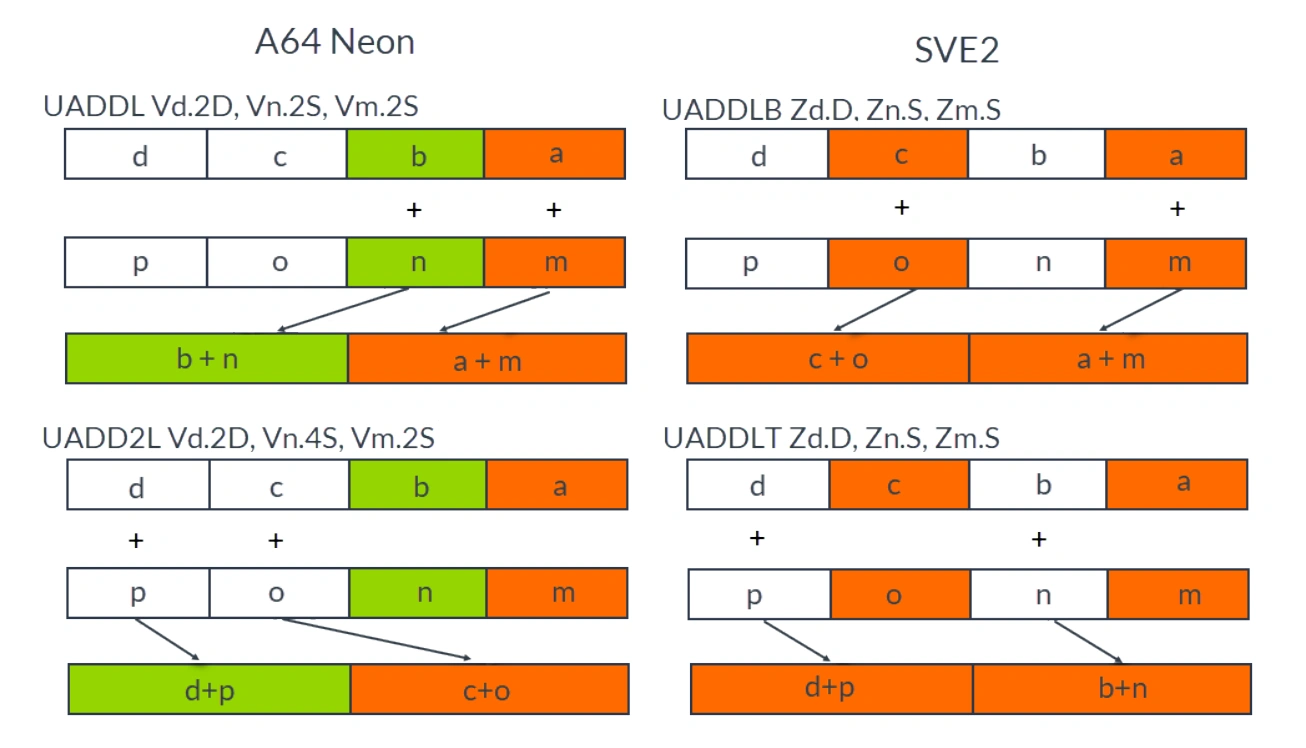
Comparison of Transformed Neon Narrow or Wide Operations
- Complex number operations, such as complex integer multiplication-accumulation with rotation (CMLA).
- Multi-precision arithmetic, used for large integer arithmetic and cryptography, for example, carry-in long addition - bottom (ADCLB), carry-in long addition - top (ADCLT) and SM4 encryption and decryption (SM4E).
For backward compatibility, the latest architecture requires Neon and VFP. Although SVE2 includes some features of SVE and Neon, SVE2 does not preclude the presence of Neon on the chip.
SVE2 supports optimization for emerging applications beyond the HPC market, such as in machine learning (ML) (UDOT instructions), computer vision (TBL and TBX instructions), baseband networks (CADD and CMLA instructions), genomics (BDEP and BEXT instructions), and servers (MATCH and NMATCH instructions).
SVE2 enhances the overall performance of general-purpose processors in handling large volumes of data, without the need for additional off-chip accelerators.
# 4. Using SVE programming
This section introduces software tools and libraries that support SVE2 application development. This section also explains how to develop applications for targets that support SVE2, run the application on hardware that supports SVE2, and simulate the application on any Armv8-A hardware.
# 4.1 Software and Library Support
To build SVE or SVE2 applications, you must choose a compiler that supports SVE and SVE2 features.
- GNU tools version 8.0+ supports SVE.
- Arm Compiler for Linux Version 18.0+ supports SVE, Version 20.0+ supports SVE and SVE2.
- Both GNU and Arm Compiler for Linux compilers support optimizing C/C++/Fortran code.
- LLVM (open-source Clang) version 5 and above includes support for SVE, and version 9 and above includes support for SVE2. To find out which SVE or SVE2 features are supported by each version of the LLVM tools, please refer to the LLVM toolchain SVE support page .
Arm Performance Libraries are highly optimized for mathematical routines and can be linked to your applications. Arm Performance Libraries version 19.3+ supports SVE’s math library.
Arm Compiler for Linux is part of Arm Allinea Studio, including Arm C/C++ Compiler, Arm Fortran Compiler, and Arm Performance Libraries.
# 4.2 How to Program Using SVE2
There are several methods to write or generate SVE and SVE2 code. In this section, we will explore some of these methods.
To write or generate SVE and SVE2 code, you can:
- Write SVE assembly code
- Programming with SVE intrinsics
- Automatic vectorization
- Use SVE optimization library
Let’s take a closer look at these four options.
# 4.2.1 Write SVE assembly code
You can write SVE instructions as inline assembly in C/C++ code, or as a complete function in assembly source code. For example:
| |
If you write functions that mix high-level language and assembly language, you must be familiar with the Application Binary Interface (ABI) standards updated for SVE. The Arm Architecture Procedure Call Standard (AAPCS) specifies data types and register allocation, and is most relevant to assembly programming. AAPCS requires:
Z0-Z7andP0-P3are used to pass scalable vector parameters and results.Z8-Z15andP4-P15are callee-saved.- All other vector registers (
Z16-Z31) may be corrupted by the called function, and the calling function is responsible for backing up and restoring them when necessary.
# 4.2.2 Using SVE Instruction Functions (Intrinsics)
SVE intrinsic functions are functions supported by the compiler that can be replaced with corresponding instructions. Programmers can directly call instruction functions in high-level languages such as C and C++. The ACLE (Arm C Language Extensions) for SVE defines which SVE intrinsic functions are available, their parameters, and their functionality. A compiler that supports ACLE can replace intrinsics with mapped SVE instructions during compilation. To use ACLE intrinsics, you must include the header file arm_sve.h, which contains a list of vector types and intrinsic functions (for SVE) that can be used in C/C++. Each data type describes the size and data type of the elements in the vector:
svint8_t svuint8_tsvint16_t svuint16_t svfloat16_tsvint32_t svuint32_t svfloat32_tsvint64_t svuint64_t svfloat64_t
For example, svint64_t represents a 64-bit signed integer vector, svfloat16_t represents a half-precision floating-point vector.
The following example C code has been manually optimized using SVE intrinsics:
| |
The source code that includes the arm_sve.h header file can use SVE vector types, just like data types can be used for variable declarations and function parameters. To compile the code using the Arm C/C++ compiler and target the Armv8-A architecture that supports SVE, use:
| |
This command generates the following assembly code:
| |
# 4.2.3 Automatic Vectorization
C/C++/Fortran compilers (for example, the native Arm Compiler for Linux
for the Arm platform and the GNU compiler) support vectorization of C, C++, and Fortran loops using SVE or SVE2 instructions. To generate SVE or SVE2 code, choose the appropriate compiler options. For example, one option to enable SVE2 optimization using armclang is -march=armv8-a+sve2. If you want to use the SVE version of the library, combine -march=armv8-a+sve2 with -armpl=sve.
# 4.2.4 Using SVE/SVE2 to Optimize Libraries
Use libraries highly optimized for SVE/SVE2, such as Arm Performance Libraries
and Arm Compute Libraries. Arm Performance Libraries contain highly optimized implementations of mathematical functions optimized for BLAS, LAPACK, FFT, sparse linear algebra, and libamath. To be able to link any Arm Performance Libraries function, you must install Arm Allinea Studio and include armpl.h in your code. To build applications using Arm Compiler for Linux and Arm Performance Libraries, you must specify -armpl=<arg> on the command line. If you are using GNU tools, you must include the Arm Performance Libraries installation path in the linker command line with -L<armpl_install_dir>/lib and specify the GNU option equivalent to the Arm Compiler for Linux -armpl=<arg> option, which is -larmpl_lp64. For more information, please refer to the Arm Performance Libraries Getting Started Guide.
# 4.3 How to run SVE/SVE2 programs
If you do not have access to SVE hardware, you can use models or simulators to run the code. You can choose from the following models and simulators:
- QEMU: Cross-compilation and native models, supporting modeling on Arm AArch64 platforms with SVE.
- Fast Models: Cross-platform models that support modeling on Arm AArch64 platforms with SVE running on x86-based hosts. Architecture Envelope Model (AEM) with SVE2 support is only available to major partners.
- Arm Instruction Emulator (ArmIE): Runs directly on the Arm platform. Supports SVE and supports SVE2 from version 19.2+.
# 5. ACLE Intrinsics
# 5.1 ACLE Introduction
ACLE (Arm C Language Extensions) is used in C and C++ code to support Arm features through intrinsics and other characteristics.
- ACLE (ARM C Language Extensions) extends the C/C++ language with Arm-specific features.
- Predefined macros:
__ARM_ARCH_ISA_A64,__ARM_BIG_ENDIAN, etc. - Internal functions:
__clz(uint32_t x),__cls(uint32_t x), etc. - Data types: SVE, NEON, and FP16 data types.
- Predefined macros:
- ACLE support for SVE uses ACLE for variable-length vector (VLA) programming.
- Almost every SVE instruction has a corresponding intrinsic function.
- Data type used to represent size-agnostic vectors used by SVE intrinsics.
- Applicable scenarios for the following users:
- Users who wish to manually adjust SVE code.
- Users who wish to adapt or manually optimize applications and libraries.
- Users who need low-level access to Arm targets.
# 5.2 How to use ACLE
- Include header files
arm_acle.h: Core ACLEarm_fp16.h: Add FP16 data type.- The target platform must support FP16, i.e.,
march=armv8-a+fp16.
- The target platform must support FP16, i.e.,
arm_neon.h: Add NEON Intrinsics and data types.- The target platform must support NEON, i.e.,
march=armv8-a+simd.
- The target platform must support NEON, i.e.,
arm_sve.h: Add SVE Intrinsics and data types.- The target platform must support SVE, i.e.,
march=armv8-a+sve.
- The target platform must support SVE, i.e.,
# 5.3 SVE ACLE
- The first thing to do is to include the header files
| |
- VLA data type
svfloat64_t,svfloat16_t,svuint32_t, etc.- Naming convention:
sv<datatype><datasize>_t
- Prediction
- Merge:
_m
- Merge:
- Reset:
_z - Uncertain:
_x - Data type of P register:
svbool_t - Use generics for function overloading, for example, the function
svaddwill automatically select the corresponding function based on the parameter type. - Function naming convention:
svbase[disambiguator][type0][type1]...[predication]- base refers to basic operations, such as
add,mul,sub, etc. - disambiguator is used to distinguish different variants of the same basic operation.
- base refers to basic operations, such as
- typeN specifies the type of vector and P register.
- predication specifies the handling method for inactive elements.
- For example:
svfloat64_t svld1_f64,svbool_t svwhilelt_b8,svuint32_t svmla_u32_z,svuint32_t svmla_u32_m
- For example:
# 5.4 Common SVE Intrinsics
- Predicate
- Predicate is a vector of type bool, used to control whether the corresponding position in the vector participates in the computation during the process.
svbool_t pg = svwhilelt_b32(i, num)generates a predicate for (i, i + 1, i + 2, …, i + vl - 1) < numsvbool_t pg = svptrue_b32()generates a predicate that is all true- Among them, b32 corresponds to processing 32-bit data (int/float), in addition, there are also intrinsics corresponding to b8, b16, b64.
- Memory data access
svld1(pg, *base): Load contiguous vector from address base.svst1(pg, *base, vec): Store the vector vec into the address base.
svld1_gather_index(pg, *base, vec_index): Load the data corresponding to the vector index from the address base.svst1_scatter_index(pg, *base, vec_index, vec): Store data from vector vec to the positions corresponding to the vector indices.- Basic calculation
svadd_z(pg, sv_vec1, sv_vec2)svadd_m(pg, sv_vec1, sv_vec2)svadd_x(pg, sv_vec1, sv_vec2)svadd_x(pg, sv_vec1, x)- Among them,
_zindicates setting the position where pg is false to zero,_mindicates retaining the original value, and_xindicates uncertainty (any value is possible).
- The second operand can be scalar data.
svmul,svsub,svsubr,svdiv,svdivr: Among them,svsubrswaps the position of the subtrahend and the minuend compared tosvsub.- Others
svdup_f64(double x): Generate a vector with all elements being x.svcntd(): Returns the vector length of 64-bit data:svcntbcorresponds to 8 bits,svcnthcorresponds to 16 bits,svcntwcorresponds to 32 bits.
# 5.5 SVE Structure Intrinsics
For corresponding structure data, SVE provides some special intrinsics, such as: svld3, svget3, svset3, svst3, etc. These intrinsics are used for processing structure data.
For example, for the particle structure:
| |
You can use svld3 to load all the data in the structure as a group of 3 vectors, and then use svget3 to extract a vector from the group of 3 vectors, where the value of index 0, 1, 2 corresponds to x, y, z respectively.
| |
svld3(pg, *base): Load all data in the structure as a group of 3 vectors; where base is the address of the 3-element structure array.svget3(tuple, index): Extract a vector from a group of 3 vectors; the value of index is 0, 1, or 2.svset3(tuple, index, vec): Set one vector in a group of 3 vectors; the value of index is 0, 1, or 2.svst3(pg, *base, vec): Store a group of 3 vectors into a structure; where base is the address of an array of structures with 3 elements.
# 5.6 SVE Condition Selection
SVE provides methods such as svcmplt, svcompact, svcntp_b32, etc., which can select elements to retain in the vector based on conditions.
For example, for non-vectorized code:
| |
The purpose of this code is to select elements from the provided array that are less than mark and store them in the selected array until the selected array is full.
Rewrite with SVE Intrinsic:
| |
svcmplt(pg, vec1, vec2): Compare the size of two vectors, returning a predicate indicating the positions in vec1 that are less than vec2.svcompact(pg, sv_tmp): Compress the vector, move the data withpgas active to the lower positions of the vector in order, and set the remaining positions to zero.svcntp_b32(pg, pg2): Returns the number of active elements in pg2- This code first loads the data from the provided array into sv_tmp, then uses
svcmpltto generate a predicate indicating the positions less than mark. Next, it usessvcompactto compress sv_tmp, obtaining the data less than mark, and then stores it into the selected array usingsvst1. Finally, it usessvcntp_b32to count the number of active elements and update count.
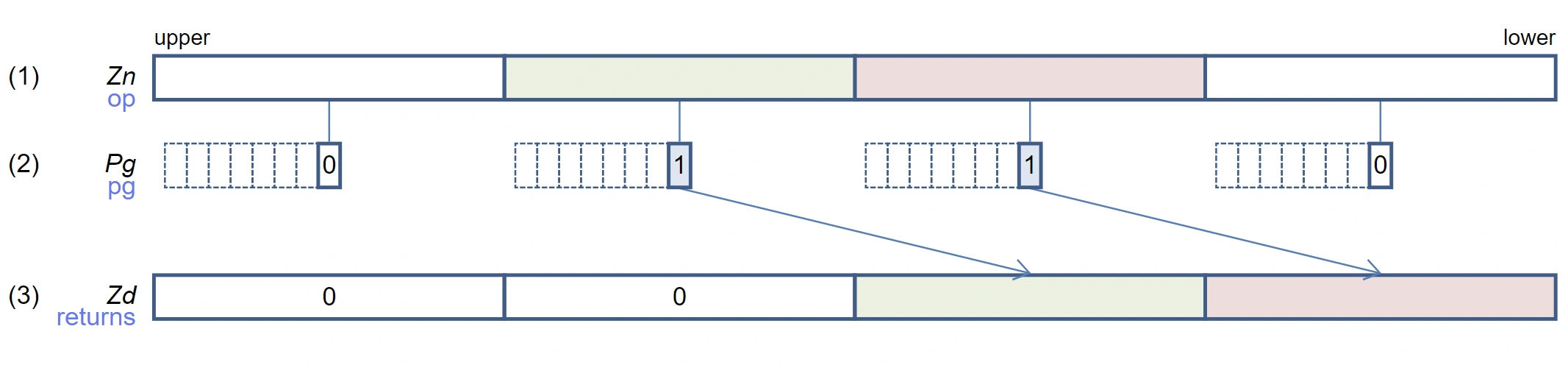
svcompact schematic diagram (256-bit vector)
Due to the compact operation, the selected array stores new data less than mark continuously from the count position, and the remaining positions are set to zero.
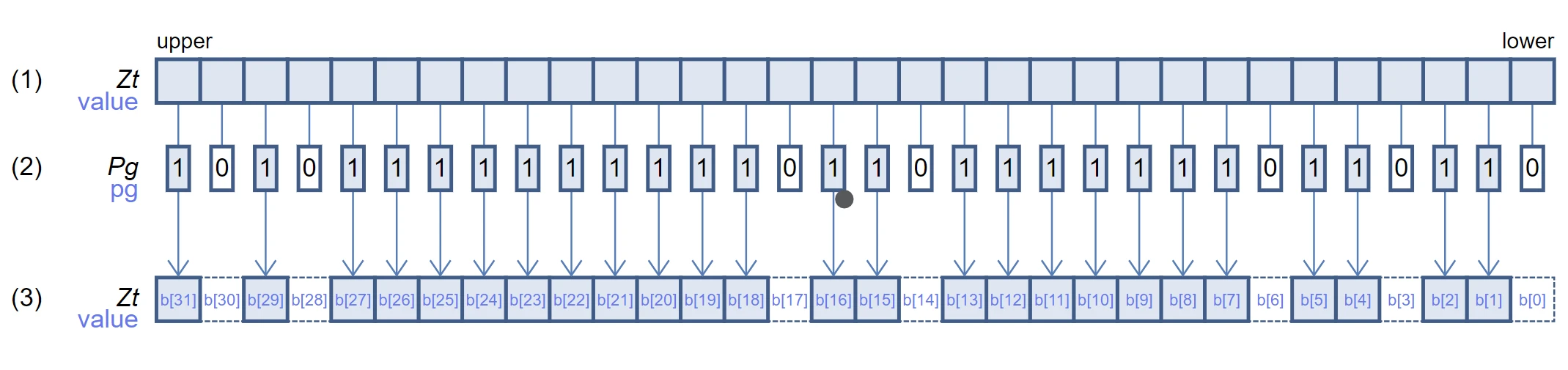
svst1 schematic diagram (256-bit vector)
# 5.7 SVE Vectorized Loop Interleaving
The vectorized loop interleaving implemented by SVE Intrinsic can greatly reduce the number of times vectors are read compared to compiler auto vectorization.
For example, for non-vectorized code:
| |
After the compiler automatically vectorizes the code, each iteration requires reading data from five different vectors, resulting in low efficiency.
Rewrite with SVE Intrinsic:
| |
svmad_x(pg, vec1, vec2, vec3): Calculates vec1 * vec2 + vec3, returns a vector.- This code only needs to read one vector per iteration, greatly reducing the number of vector reads.